Discovery, CMDB e Gestão de Ativos
- Introdução ao discovery do Priax
- Gestão de Ativos
- Discovery de Mapas de Aplicações
- Exibição de Dados e Navegação na CMDB
- Tipos de IC Nativos e Templates
Introdução ao discovery do Priax
O Módulo de Discovery identifica Itens de Configuração (ICs), seus atributos essenciais e suas relações com outros ICs diretamente do ambiente administrado, mantendo-os atualizados na CMDB. Ele é dividido em submódulos, licenciados separadamente, que realizam o discovery em diferentes classes de tecnologias e fontes de dados.
Funcionalidades do Discovery
Discovery de Rede e Domínios LDAP/Active Directory
Esse submódulo utiliza redes e domínios LDAP como fontes de dados para identificar hosts, seus sistemas operacionais e realizar varreduras internas, detectando itens de configuração e suas dependências. Os hosts descobertos passam a ser monitorados regularmente, e as alterações são refletidas na CMDB. Opcionalmente, servidores com tecnologias Windows e Linux podem receber agentes que aceleram o processo de discovery de mudanças, inserções e exclusões de ICs.
Discovery de Hypervisors
Compatível com Microsoft Hyper-V e VMware, este submódulo descobre componentes de clusters, armazenamento de dados, hosts virtuais, componentes de rede virtual e suas inter-relações.
Discovery Cloud
Especializado em plataformas de nuvem, descobre máquinas virtuais, bancos de dados gerenciados, sistemas de arquivos, armazenamento e outros elementos instanciáveis em Amazon AWS, Microsoft Azure e Google GCP. Também identifica relações entre elementos na nuvem e em ambientes on-premises.
Discovery Kubernetes e OpenShift
Capaz de mapear automaticamente toda a infraestrutura Kubernetes na CMDB, mantendo-a sincronizada com o ambiente real. Descobre elementos como nodes, storages, namespaces, deployments, replica sets e pods, além de suas relações de dependência.
Discovery e Inventário de Estações de Trabalho
Permite inventariar dispositivos de usuários, realizando o levantamento de hardware, software e outros itens de configuração. O processo pode ser feito sem agentes, utilizando redes e domínios Active Directory, ou com agentes para garantir o inventário mesmo de equipamentos externos, como notebooks em uso remoto.
Características Gerais dos submódulos de Discovery
Os módulos de Discovery apresentam um conjunto de funcionalidades robustas e flexíveis que facilitam a identificação, o monitoramento e a gestão dos Itens de Configuração (ICs) na CMDB. Essas características incluem:
Discovery de Itens de Configuração a partir de diferentes origens
Os módulos permitem configurar diversas fontes de dados para identificar e mapear ICs no ambiente de TI. As fontes possíveis incluem:
- Redes e credenciais associadas: Endereços de rede e suas respectivas credenciais, para varreduras que identificam dispositivos conectados, sistemas operacionais e outros atributos.
- Domínios Active Directory: Uso de credenciais LDAP para acessar informações sobre hosts e seus ICs, como sistemas operacionais, configurações de hardware e software instalado.
- Datacenters VMware: Endereços e credenciais de datacenters para descobrir clusters, máquinas virtuais, hosts e componentes relacionados.
- APIs de provedores de nuvem: Amazon AWS, Microsoft Azure e Google GCP, com credenciais para acessar configurações de máquinas virtuais, bancos de dados, sistemas de arquivos e outros serviços.
- Clusters Kubernetes: Endereços e credenciais para identificar nós, pods, namespaces e outros elementos da infraestrutura Kubernetes.
Automação e simplificação da gestão da CMDB
Os módulos incluem ferramentas que aceleram a implementação e reduzem a complexidade da manutenção, como:
- Discovery contínuo e automatizado: A CMDB é mantida atualizada automaticamente, com inserção e remoção de ICs em tempo real, de acordo com as mudanças no ambiente.
- Varredura sem agentes: A descoberta inicial pode ser realizada sem a necessidade de instalar agentes nos dispositivos, simplificando a configuração inicial.
- Compatibilidade com múltiplas assinaturas em ambientes cloud: Suporte para varreduras de múltiplos tenants e subscriptions em uma única instância, cobrindo ambientes híbridos ou complexos.
Personalização com modelos de IC adicionais
Os usuários podem criar modelos personalizados de ICs, permitindo o discovery e a gestão de itens que não são nativamente suportados pela ferramenta. Esses modelos podem ser associados a fontes de dados específicas, como APIs ou configurações customizadas.
Flexibilidade na descoberta de ICs personalizados
A ferramenta oferece mecanismos para expandir sua capacidade de descoberta, permitindo:
- Adicionar novos modelos de ICs.
- Configurar fontes de dados customizadas.
- Automatizar o mapeamento de dependências e relações para modelos personalizados.
Identificação e classificação de relações entre ICs
Os módulos detectam automaticamente as relações entre ICs e classificam essas dependências, com base em critérios como:
- Armazenamento de dados: Um IC armazena informações de outro.
- Fluxo de dados: Um IC envia ou recebe dados de outro.
- Dependência funcional: Um IC depende de outro para operar corretamente.
Descoberta automatizada de dependências
A ferramenta identifica relações intrínsecas ou funcionais entre ICs, como:
- Relações de composição: Um IC é parte integrante de outro.
- Relações de funcionamento: Um IC depende de outro para operar.
Visualização hierárquica de dependências
As dependências entre ICs e aplicações de negócios são representadas em árvores hierárquicas. Essas visualizações facilitam o entendimento das relações e oferecem painéis analíticos para análise de impacto e funcionamento.
Identificação de Single Points of Failure (SPFs)
O sistema detecta SPFs, ou seja, ICs cuja falha pode causar interrupções significativas em aplicações ou processos críticos. Essa análise é apresentada em relatórios específicos, fáceis de gerar e interpretar.
Análise de impactos de falhas
A ferramenta identifica os possíveis impactos de uma falha em um IC sobre outros ICs e aplicações relacionadas. Assim como os SPFs, essa análise é documentada em relatórios específicos, sem necessidade de procedimentos manuais.
Consideração de redundâncias entre ICs
A CMDB permite configurar clusters de ICs redundantes, detalhando:
- A quantidade mínima de ICs ativos necessários para o funcionamento do cluster.
- A lógica de redundância aplicada nos relatórios de SPFs e impactos.
- Grupos de tipos de ICs.
- Atributos específicos.
- Relações entre ICs.
Esses filtros permitem criar listagens personalizadas para análises específicas.
Painéis customizados para visualização da CMDB
A ferramenta oferece suporte à criação de painéis personalizados, permitindo que os usuários configurem visualizações adaptadas às suas necessidades de monitoramento e gestão.
Gestão de Ativos
O Priax é uma solução completa e integrada para o controle eficiente de todos os recursos tecnológicos de uma organização. Projetada para atender às necessidades das áreas de infraestrutura, suporte e governança de TI, a ferramenta centraliza as informações de hardware e software, oferecendo visibilidade, controle e rastreabilidade de ativos ao longo de seu ciclo de vida.
Gestão de Hardware
-
Inventário de Equipamentos: Registro detalhado de estações de trabalho, notebooks, celulares e outros dispositivos, com informações como modelo, fabricante, número de série, localização física e status.
-
Gestão Patrimonial: Acompanhamento do patrimônio de TI com controle de tombamento, movimentações internas, cessões e baixas.
-
Controle de Garantias: Registro e monitoramento automático de prazos de garantia de cada equipamento, com alertas para vencimentos iminentes.
-
Histórico de Manutenções e Trocas: Registro de intervenções técnicas, substituições e movimentações de equipamentos por usuário, local ou setor.
Inventário de Equipamentos (Hardware)
A funcionalidade de Inventário de Hardware da Priax oferece uma visão completa, automatizada e em tempo real de todos os ativos físicos de tecnologia da informação da organização. Por meio de mecanismos de varredura e coleta inteligente de dados, a Priax realiza um mapeamento detalhado de computadores, impressoras e outros dispositivos conectados à infraestrutura corporativa.
Coleta Automática de Informações Técnicas
A Priax realiza a coleta automatizada de informações técnicas por meio de agentes locais, protocolos padrão (como WMI, SNMP, etc.) ou integração com soluções de gerenciamento já existentes. Esse processo permite capturar e registrar com precisão os seguintes dados:
-
Identificação do Equipamento
-
Fabricante
-
Nome e modelo do equipamento
-
Número de série (Serial Number)
-
Etiqueta de patrimônio (se aplicável)
-
Tipo de dispositivo (notebook, desktop, servidor, impressora, etc.)
-
Localização física e unidade organizacional
-
-
Componentes de Hardware
-
Processador (CPU): modelo, fabricante, número de núcleos, arquitetura e velocidade de clock
-
Placa-mãe: modelo, fabricante, revisão, número de série
-
Memória RAM: capacidade total instalada, quantidade de pentes, tipo (DDR3, DDR4 etc.), slots ocupados
-
Disco Rígido / SSD: capacidade, tipo, fabricante, uso atual, número de série e status SMART (se disponível)
-
Placa de Vídeo: modelo, memória dedicada, fabricante
-
Placa de Rede: interfaces detectadas, endereços MAC, velocidades suportadas
-
Monitor(es): modelo, resolução nativa, tamanho e número de série (quando disponível)
-
-
Outros Equipamentos
-
Impressoras (locais ou em rede): modelo, fabricante, status, tipo (jato de tinta, laser), contador de páginas (via SNMP)
-
Dispositivos periféricos: teclado, mouse, dispositivos USB e outros dispositivos PNP relevantes
-
Rastreabilidade e Histórico
Cada item de hardware registrado na Priax mantém um histórico completo de alterações, incluindo:
- Troca de componentes
- Movimentações entre unidades ou usuários
- Alterações de configuração ou upgrade
- Manutenções realizadas
Gestão de Software
-
Inventário de Softwares Instalados: Detecção automática de aplicativos instalados nos dispositivos, com identificação de versão, fornecedor e frequência de uso.
-
Gestão de Licenças: Controle centralizado de contratos, chaves de ativação e número de licenças adquiridas versus utilizadas, com alertas para vencimentos ou não conformidades.
-
Controle de Uso de Software: Monitoramento da utilização de softwares críticos ou licenciados, com dados analíticos para apoiar decisões de renovação, remoção ou realocação de licenças.
Inventário de Softwares
A funcionalidade de Inventário de Softwares da Priax oferece visibilidade completa e contínua sobre todos os aplicativos instalados nos dispositivos da organização, abrangendo ambientes Windows e Linux. Por meio de uma varredura inteligente e não intrusiva, a ferramenta identifica, cataloga e mantém atualizado o repositório de softwares em uso, promovendo governança, segurança e compliance com políticas de licenciamento.
Descoberta e Coleta de Informações
A Priax realiza a coleta de dados por meio de agentes locais ou acesso remoto via protocolos nativos do sistema operacional, como:
-
Windows Management Instrumentation (WMI)
-
Linux package managers (APT, RPM, DPKG, YUM, Zypper, etc.)
-
Scripts personalizados e comandos shell
Essa abordagem permite identificar:
-
Nome do software/aplicativo
-
Versão instalada
-
Fornecedor / fabricante
-
Data de instalação
-
Caminho de instalação
-
Chave de licença (quando disponível)
-
Tipo de instalação (usuário ou sistema)
-
Frequência e data do último uso (opcional)
Catálogo e Normalização de Aplicações
Os dados coletados são organizados automaticamente em um catálogo de softwares com normalização de nomes e versões, evitando duplicidades e inconsistências. Isso facilita a visualização em relatórios e a análise gerencial, além de permitir a categorização por tipo de aplicação, finalidade, criticidade ou compliance.
Controle e Medição de Uso de Software
A funcionalidade de Medição de Uso de Software da Priax vai além do inventário tradicional, oferecendo um monitoramento preciso e detalhado da utilização real dos softwares instalados em cada estação de trabalho ou servidor. Essa capacidade permite à organização identificar padrões de uso, justificar investimentos, otimizar licenciamento e promover a governança eficaz de seu parque de aplicações.
Coleta Inteligente de Dados de Uso
Por meio de agentes leves instalados em dispositivos Windows e Linux, a Priax monitora de forma contínua os seguintes parâmetros:
-
Execução de Aplicativos: Detecção de quando um determinado software é iniciado e encerrado.
-
Duração de Uso Ativo: Tempo total em que o software permaneceu em execução, considerando apenas períodos em que o usuário estava ativo (interações reais com o sistema).
-
Usuário e Estação Associada: Identificação precisa do usuário logado e da máquina em que o software foi utilizado.
-
Contagem de Sessões: Número de vezes que o software foi executado em um determinado período.
-
Registro em Tempo Real: Dados podem ser enviados em tempo real para o servidor central ou armazenados localmente para sincronização posterior, ideal para ambientes com rede instável ou dispositivos móveis.
Exemplos de Métricas Capturadas
| Software | Usuário | Estação | Execuções (mês) | Duração Total (hh:mm) |
|---|---|---|---|---|
| Microsoft Excel | j.silva | WS-019 | 24 | 12:35 |
| AutoCAD | a.rocha | NB-042 | 3 | 4:20 |
| Adobe Photoshop | m.almeida | NB-113 | 0 | 0:00 |
Análises e Aplicações Práticas
A Priax utiliza os dados de uso para gerar insights estratégicos e operacionais, tais como:
-
Identificação de Softwares Subutilizados: Aplicativos com baixíssima ou nenhuma frequência de uso, candidatos à remoção ou redistribuição de licenças.
-
Justificativa de Investimentos: Base objetiva para renovação, expansão ou encerramento de contratos de software.
-
Compliance e Governança: Evidência concreta de conformidade ou violação de políticas de uso de software.
-
Planejamento de Treinamentos: Identificação de usuários que pouco utilizam ferramentas essenciais para suas funções, indicando possíveis lacunas de capacitação.
-
Mapeamento de Cargas de Trabalho: Apoio na redistribuição de licenças flutuantes e de alto custo, como softwares de engenharia ou design.
Relatórios e Dashboards
A Priax apresenta os dados de uso em dashboards interativos e relatórios que podem ser filtrados por:
-
Usuário, estação, grupo ou departamento
-
Nome do software ou categoria
-
Período (diário, semanal, mensal, customizado)
-
Faixas de tempo de uso (ex.: >20h/mês, entre 1-5h, etc.)
Os relatórios podem ser exportados em PDF, Excel ou enviados automaticamente por e-mail para áreas como TI, Compras, Auditoria ou Gestão de Riscos.
Gestão de Licenciamento
A Priax oferece uma robusta funcionalidade de Gestão de Licenças, permitindo à organização manter total controle sobre os contratos de software adquiridos, sua vigência, utilização real e conformidade com os limites de uso. Combinando dados do inventário de software e do monitoramento de uso, a solução proporciona uma gestão preventiva, inteligente e auditável do licenciamento.
Registro Centralizado de Licenças
A Priax permite o cadastro completo das licenças adquiridas para cada software, com os seguintes campos:
-
Nome do software e versão
-
Tipo de licença (perpétua, por assinatura, por usuário, por dispositivo, flutuante, etc.)
-
Quantidade de licenças adquiridas
-
Número(s) de série ou chave(s) de ativação
-
Fornecedor ou fabricante
-
Data de aquisição
-
Data de expiração ou renovação (se aplicável)
-
Unidade, centro de custo ou projeto vinculado
Vinculação com Dispositivos e Usuários
Cada licença registrada pode ser vinculada de forma automática ou manual aos computadores e/ou usuários onde o software correspondente está instalado e/ou em uso. A Priax mantém um mapeamento preciso de:
-
Quais estações estão utilizando cada licença
-
Quem são os usuários atribuídos
-
Quando cada licença foi ativada ou instalada
Controle de Utilização de Licenças
A ferramenta realiza a conciliação contínua entre o número de licenças adquiridas e o número de instalações ou execuções registradas no ambiente. Isso permite:
-
Contabilizar licenças em uso: Com base no inventário e no uso ativo do software
-
Detectar licenças ociosas: Equipamentos com softwares instalados que não foram utilizados recentemente
-
Gerenciar excedentes: Alertas automáticos sempre que o número de instalações ultrapassar a quantidade licenciada
Alertas e Notificações
A Priax gera alertas configuráveis em diversos cenários críticos:
-
Excesso de uso: Mais softwares em uso do que o permitido pela licença
-
Vencimento de licenças: Avisos antecipados por e-mail ou dashboard para licenças próximas à expiração
-
Risco de não conformidade: Sinalização de softwares instalados sem vínculo com uma licença válida
-
Distribuição ineficiente: Licenças atribuídas a máquinas ou usuários sem uso efetivo
Relatórios e Auditoria
A solução oferece relatórios completos sobre:
-
Licenças por software (adquiridas, utilizadas, ociosas)
-
Histórico de alocação e utilização
-
Conformidade por unidade ou departamento
-
Projeções de renovação e necessidades futuras
-
Alertas e desvios detectados
Esses relatórios podem ser exportados, agendados e integrados a ferramentas externas, como sistemas ERP, ITSM ou plataformas de auditoria.
Discovery de Mapas de Aplicações
O Priax Application Mapping
O Priax Application Mapping tem em sua base o conceito de rastreamento distribuído (Distributed Tracing) que é usado por diversas ferramentas de Application Performance Monitoring (APM) para solucionar o problema de entender o fluxo de execução de uma solicitação em sistemas distribuídos, nos quais uma única solicitação é processada por vários componentes ou serviços.
A ideia central do rastreamento distribuído é que uma solicitação pode ser dividida em várias operações menores, conceitualmente chamadas de "spans", que representam unidades de trabalho individuais dentro de um sistema distribuído. Cada span registra informações sobre a operação, como seu início, duração, identificador exclusivo e quaisquer metadados relevantes. Os spans são conectados em uma árvore hierárquica, na qual o span raiz representa a solicitação inicial e os spans filhos representam operações dependentes ou subprocessos.
Essa estrutura hierárquica de spans permite visualizar o fluxo de execução completo de uma solicitação, identificar gargalos de desempenho, analisar o tempo gasto em cada operação e depurar problemas em sistemas distribuídos complexos. Além disso, cada span pode conter anotações adicionais, como logs e tags, que fornecem informações contextuais para facilitar a compreensão do comportamento do sistema.
A teoria relacionada às spans no rastreamento distribuído é fortemente influenciada por conceitos de observabilidade, como causalidade, transparência e correlação de eventos. Ao coletar e correlacionar spans de diferentes componentes, é possível reconstruir a trajetória completa de uma solicitação e obter insights valiosos sobre o desempenho e a eficiência do sistema distribuído. O rastreamento distribuído e o uso de spans tornaram-se fundamentais para a observabilidade e o monitoramento de sistemas distribuídos modernos, permitindo aos desenvolvedores e operadores uma compreensão mais profunda do comportamento e do desempenho de suas aplicações.
Com base nessas tecnologias, o Application Mapping, que é um módulo do Priax, visa o mapeamento automático de dependências de Aplicações, correlacionando os Itens de Configuração da CMDB em função do uso que as Aplicações, ao longo de seus funcionamentos, fazem desses recursos. Para tal, o Application Mapping analisa as spans geradas pela aplicação, buscando informações sobre o uso ou consumo de recursos externos à aplicação (Itens de Configuração), para gerar o correlacionamento de dependência. Desta forma o Priax é capaz de identificar, entre outros tipos de Itens de Configuração os seguintes tipos de recursos:
- Bases (schemas ou databases) de dados em Bancos de Dados Relacionais;
- Bancos de dados não-relacionais;
- WebServices e outras aplicações web consultadas;
- Sockets de rede consultados;
- Processos (executáveis em execução) locais e remotos com os quais a aplicação troca informação;
- Tópicos ou filas de serviços de mensagens ou fluxo de dados como Kafka e RabbitMQ.
O resultado dessas análises são mapas de dependências, que correlacionam os Itens de Configuração diretamente e indiretamente consumidos pelas transações executadas pela Aplicação, formando uma árvore de dependências que explica exatamente o que cada aplicação precisa para funcionar, podendo ser usadas posteriormente para simulações de impactos e de dependências, na análise em tempo real de impactos no caso de uma falha de algum IC ou para o planejamento de continuidade de negócios e recuperação de desastres. Abaixo um exemplo de mapa gerado pelo Application Mapping.
O Application Mapping realiza também a remoção de vínculos de dependência que não mais estão presentes na aplicação, removendo as dependências que não mais se apresentaram por tempo determinado e configurável.
Funcionamento do Application Mapping
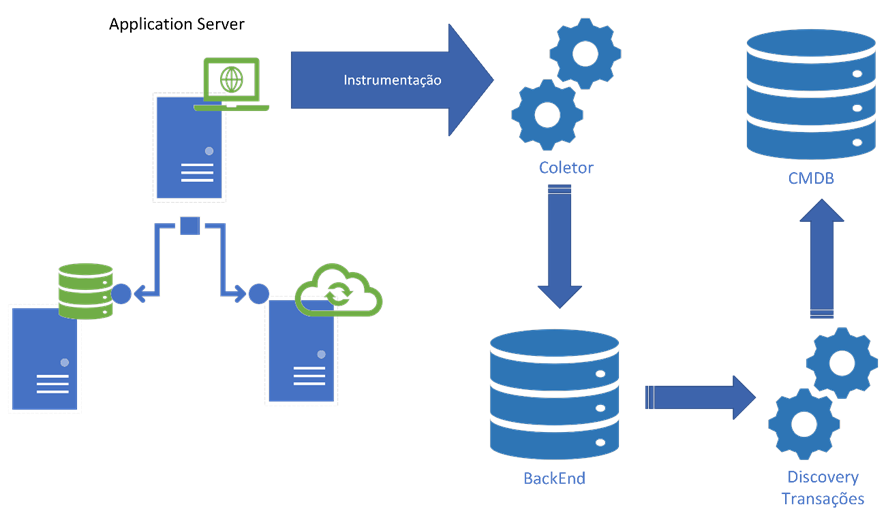
O Priax se beneficia-se do Rastreamento Distribuído de aplicações para realizar o mapeamento de Aplicações, tendo como base as spans que podem ser capturadas de diversas formas utilizando quatro componentes básicos:
- Instrumentação: A instrumentação é o ato de adicionar bibliotecas de telemetria ao código-fonte ou em camadas inferiores de sua infraestrutura (servidores de aplicação, proxies máquinas virtuais Java, etc.). Essas bibliotecas são projetadas para diferentes linguagens de programação e fornecem APIs para instrumentar pontos específicos do seu código. Por exemplo, você pode instrumentar chamadas de função, solicitações HTTP ou consultas de banco de dados. A instrumentação gera dados de telemetria, como spans (para rastreamento) e métricas. Para instrumentar uma aplicação podemos fazer uso de bibliotecas prontas ou alterar o código fonte das aplicações para realizar uma instrumentação própria.
- Coletores: Os coletores são responsáveis por coletar os dados de telemetria gerados pela instrumentação. Existem coletores específicos para diferentes tipos de dados, como rastreamento, métricas e logs. Os coletores podem ser executados como agentes no mesmo host da sua aplicação ou podem ser configurados como serviços independentes.
- BackEnds: Os dados coletados pelos coletores são enviados para backends de armazenamento, onde podem ser processados e analisados posteriormente. Os backends podem ser serviços de terceiros, como provedores de nuvem ou sistemas de armazenamento de dados internos. Eles oferecem recursos para consultar, visualizar e analisar os dados de telemetria, fornecendo insights sobre o desempenho e o comportamento do seu aplicativo. Os dados fornecidos nessa camada são utilizados para descobrir as relações entre as Aplicações e os itens de configuração presentes na CMDB Priax.
- Discovery de Transações: O sistema de Discovery de transações é um componente do Priax que consulta e analisa os dados das spans presentes nos BackEnds utilizando inteligência artificial e análise de dados, relaciona os Itens de Configuração na CMDB, criando as transações das aplicações na CMDB como Itens de Configuração que interligam os ICs.
No desenho abaixo pode-se observar como estes componentes se relacionam.
O Priax é compatível com os seguintes mecanismos de Instrumentação:

Devido aos melhores resultados obtidos, é recomendado a pilha OpenTelemetry, visto que a quantidade de informações coletadas é mais abundante e devido à melhor anonimização dos dados obtidas por essas bibliotecas de instrumentação.
Na camada de Instrumentação o Priax também é compatível com instrumentações proprietárias, desde que utilizem Coletores e BackEnds compatíveis. Desta forma é possível instrumentar uma aplicação para funcionar com o Priax sem depender diretamente de bibliotecas de terceiros em seu código-fonte. As tecnologias compatíveis com o Priax possuem especificações e API aberta que permitem implementações personalizadas para integrar a telemetria em sua aplicação.
Aqui estão algumas abordagens que você pode seguir para instrumentar sua aplicação sem utilizar bibliotecas de terceiros:
- Implementação manual: Você pode criar sua própria implementação personalizada das APIs do OpenTelemetry em seu código-fonte. Isso envolve a criação de classes, métodos e estruturas de dados necessários para capturar e enviar os dados de telemetria, como spans, métricas e logs. No entanto, essa abordagem requer um esforço significativo de desenvolvimento e manutenção, pois você precisará lidar com aspectos como a geração de IDs de rastreamento exclusivos, a propagação do contexto de rastreamento e a integração com os coletores compatíveis.
- Adaptação de código-fonte aberto: Se você preferir não desenvolver uma implementação personalizada do zero, pode considerar adaptar e modificar um código-fonte aberto existente que seja compatível com o Priax. Existem várias implementações de referência e bibliotecas de código aberto que você pode usar como base e personalizar de acordo com as necessidades da sua aplicação. Recomendamos neste caso as bibliotecas OpenTelemetry.
- Integração proxies: Uma alternativa é utilizar proxies que atuam como intermediários entre sua aplicação e os coletores. Esses agentes podem interceptar as chamadas da sua aplicação, gerar spans automaticamente e enviá-los para os coletores. Essa abordagem pode ser útil se você deseja evitar a modificação direta do código-fonte da sua aplicação.
Independentemente da abordagem escolhida, é importante garantir que você esteja seguindo as especificações compatíveis com uma das pilhas compatíveis com o Priax e fornecendo as informações de telemetria necessárias, como spans, metadados e contexto de rastreamento, para obter uma visão completa do comportamento e desempenho da sua aplicação distribuída.
Aplicações, Serviços e Transações
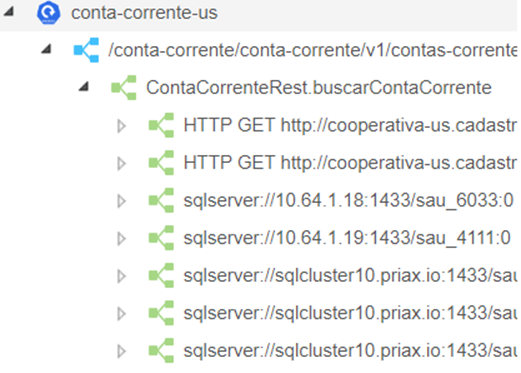
O Priax Application Mapping, através do discovery de transações cria no Priax as transações das aplicações. As transações são os Itens de Configuração que representam as spans encontradas no BackEnd que apresentam funcionamento similar. Cada diferente perfil de spans gera diferentes transações no Priax. Consultas em bancos de dados com mesmo endereço de servidor, database e query e consultas à webservices com mesmo endereço e estrutura são exemplos de perfis de spans que são transformados em transações na CMDB Priax pelo Discovery de Transações. Uma transação representa centenas e milhares de repetições de execução do mesmo trecho de código fonte dentro da aplicação.
Além de detectar as diferentes transações nos BackEnds, o discovery de transações detecta quais os Itens de Configuração que foram utilizados na execução de cada transação. Desta forma se uma transação consumir uma base de dados, um tópico de um sistema Kafka, uma fila de um sistema RabbitMQ, um socket de rede com um serviço específico ou ainda um webservice, estes componentes serão relacionados com as transações.
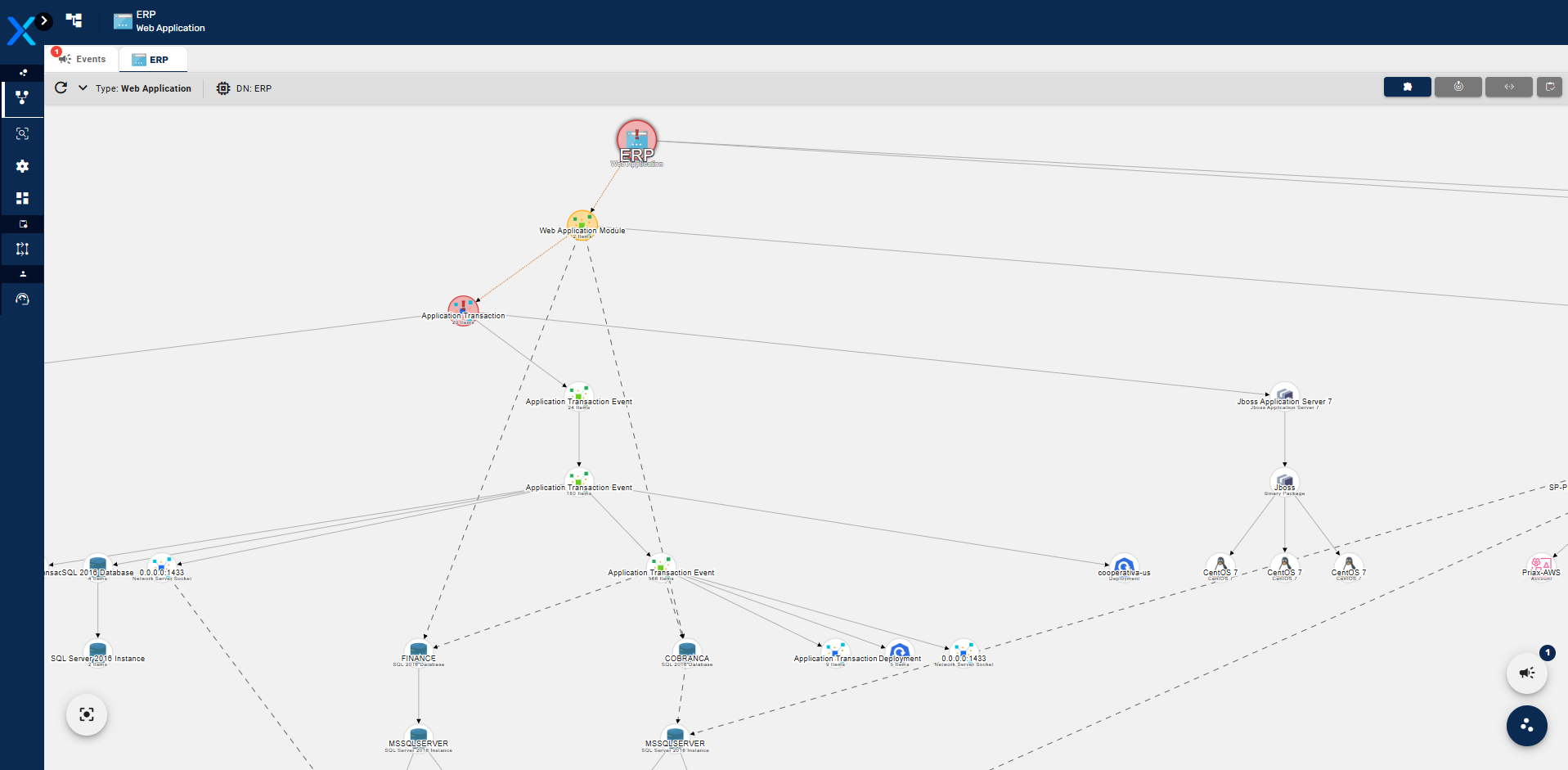
Abaixo um exemplo de transações detectada em um cluster Kubernetes.
No topo do desenho, é representado um Deployment do Kubernetes, o qual foi instrumentado. Os elementos abaixo representam hierarquicamente as transações executadas nestes containers. Cada uma das transações consomem ICs que estão na CMDB, portanto cada transação é relacionada com tais ICs, como pode-se ver no exemplo abaixo para uma transação de consulta a um webservice, hospedado por outro container instrumentado.
Como a transação consome um Deployment também instrumentado, veja que este Deployment também irá apresentar suas transações e dependências, chegando em uma base de dados MS SQL e nas suas respectivas dependências. A sucessão desta lógica, cria o mapa completo de dependência da aplicação.
Exibição de Dados e Navegação na CMDB
ICs e seus filhos
Após descobrir os Itens de Configurações (ICs) e suas relações, o Priax os cadastra em sua CMDB interna e fornece recursos de navegação para que você compreenda as descobertas, entenda a composição de cada tecnologia e também a cadeia de dependência e impacto entre esses ICs. Quando monitorados o Priax ainda fornece a capacidade de exibir os indicadores e suas coletas realizadas ao longo do tempo, exibindo gráficos do tipo Time Series para que se consiga compreender o funcionamento ativo desses elementos.
Ao autenticar, na página principal do Priax, é exibida a no painel da esquerda a árvore de ICs. A árvore de ICs, em sua raiz apresenta as famílias de ICs que é o primeiro nível de classificação. No segundo nível temos as categorias de ICs, essas subdivisões existem para organizar logicamente os ICs e facilitar a navegação na CMDB.
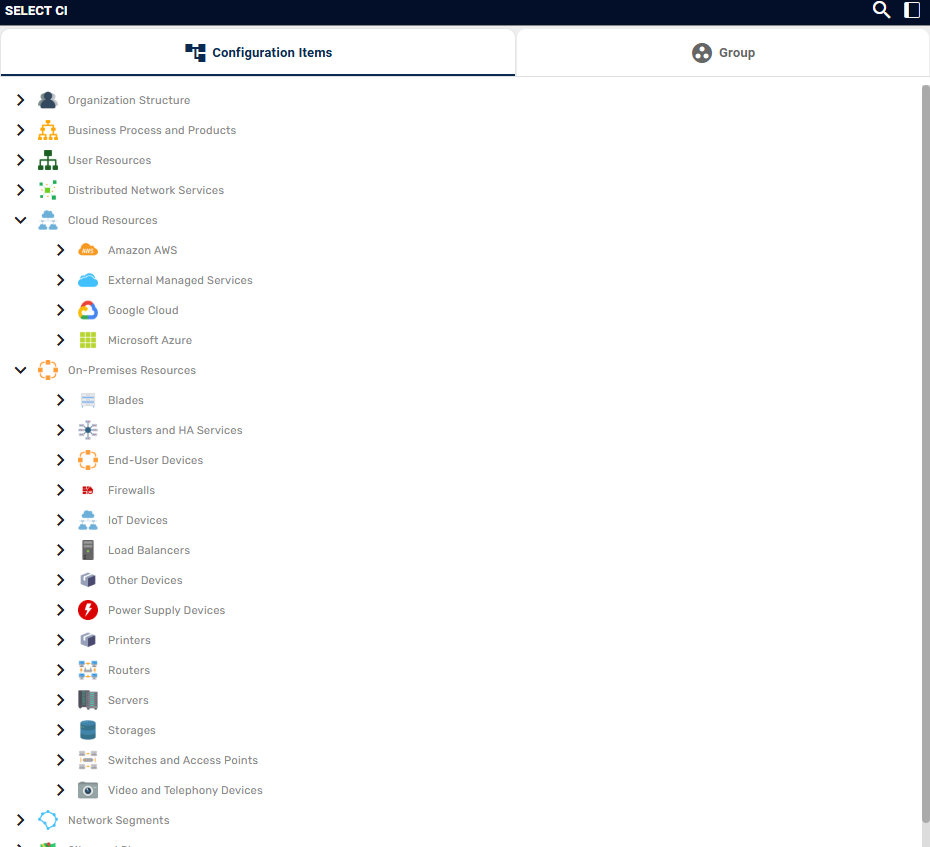
Na imagem acima, estão expandidas duas das principais famílias de ICs: Cloud Resources e On-Premises Resources. Nessas duas famílias vamos encontrar os principais tipos de ICs que estão relacionados à Infraestrutura de TI. Dentro dessas categorias temos por exemplo os Dispositivos presentes nos datacenters, os hosts e além de recursos independentes armazenados em cloud.
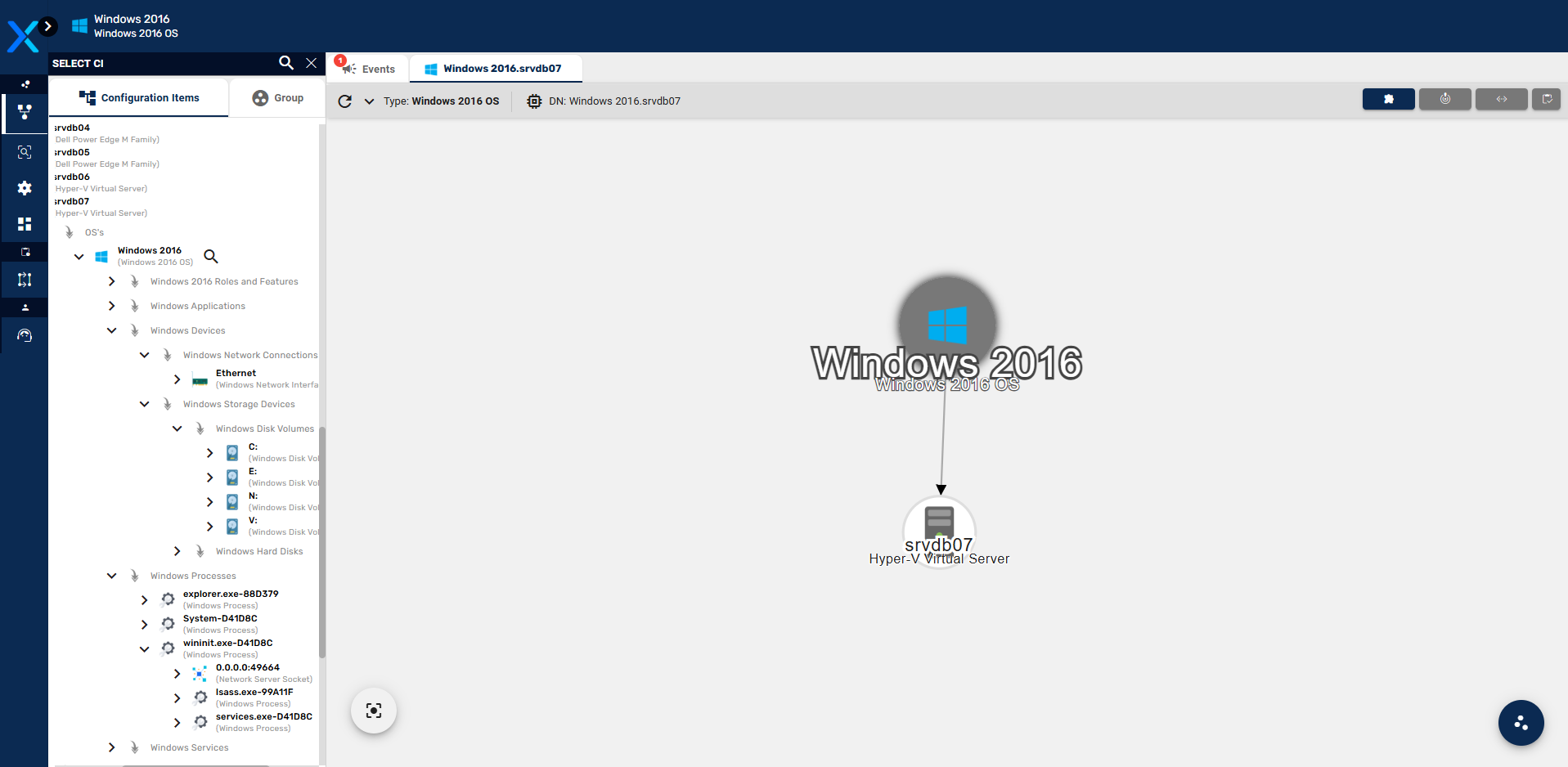
Expandindo a categoria Servers por exemplo, vamos encontrar os servidores do ambiente on-premises. Neste terceiro nível começamos a encontrar os Itens de Configuração Raiz, que são aqueles que não possuem um pai. Essa relação pai e filho é crada entre dois ICs que compõe um ao outro. Um IC pai é composto de seus filhos. Essa relação de composição presume que um filho possui apenas um pai.

Na imagem acima pode ser visto um servidor chamado srvdb07, composto de discos C:, E:, N:, V:, de uma interface de rede chamada Ethernet e também de uma árvore de processos. Esse host representa a estrutura básica de relacionamento entre ICs no Priax. Cada IC em nível inferior na árvore compõe o seu pai no nível imediatamente acima.
Detalhes dos ICs
Ao clicar em um IC, no painel da direita são exibidas suas informações detalhadas.
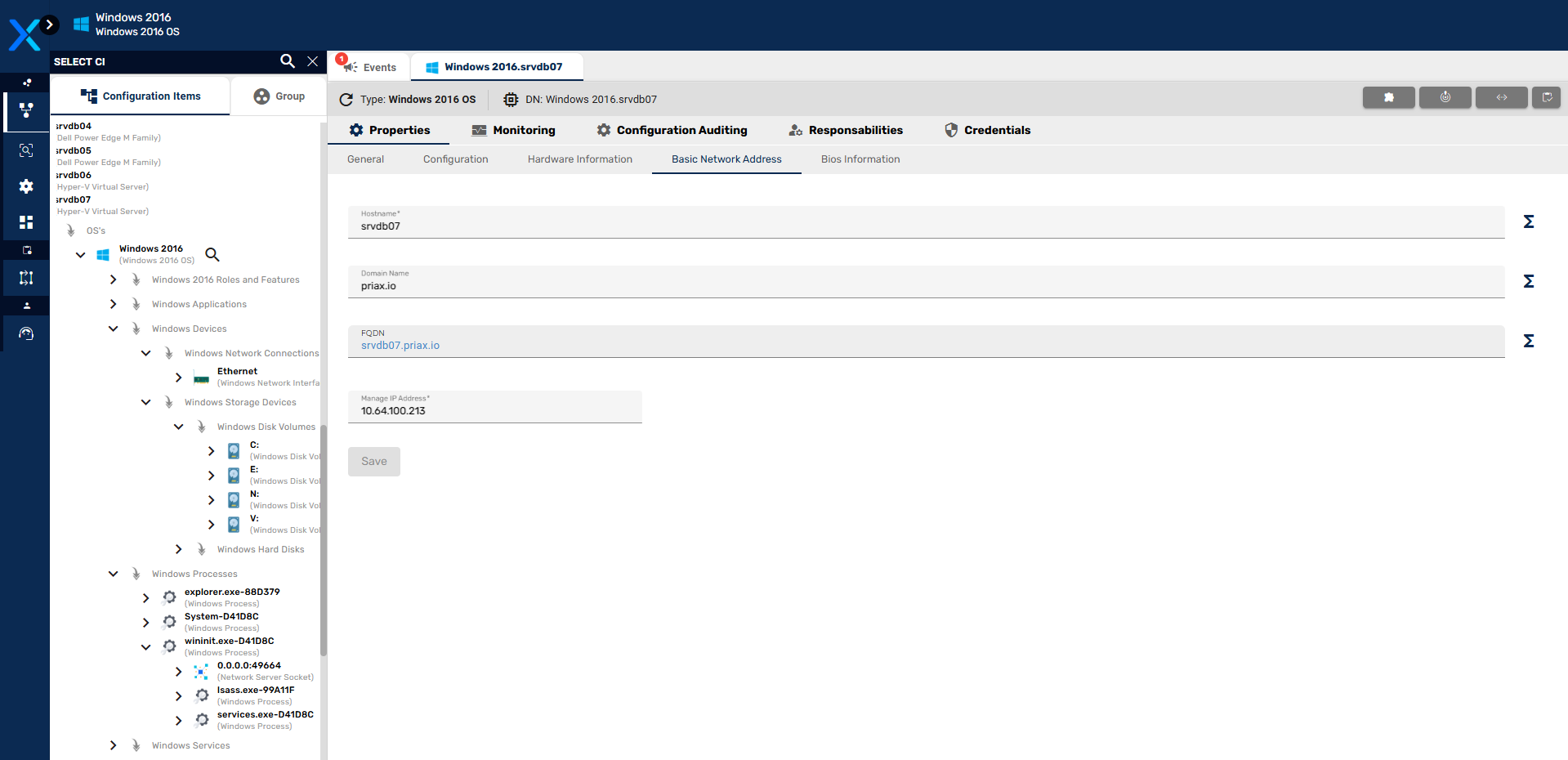
Conforme destacado na tela acima, as áreas principais nessa exibição são:
- Árvore de ICs: Árvore de composição do IC selecionado.
- Atributos do IC selecionado, cada aba representa uma classe de atributos. Cada classe de IC possui uma gama específica de atributos de acordo com sua natureza.
- Indicadores do IC: Dados históricos de cada indicador relacionado ao IC.
- Botões que levam às árvores de Impacto e Dependência de cada IC.
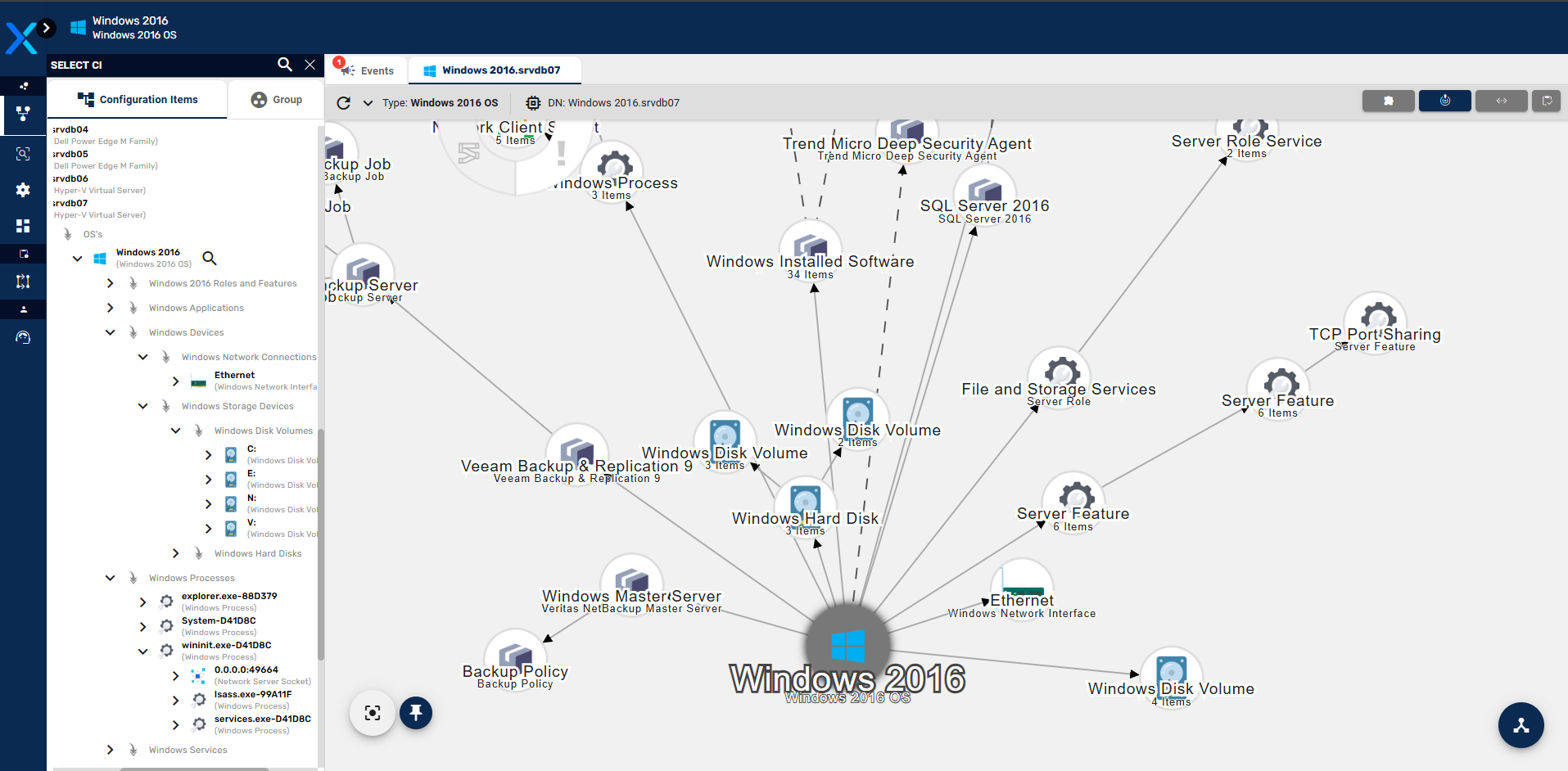
Impactos e Dependências de um IC
Ao clicar no botão Impact Analisys:

É exibida a árvore de impactos do IC, sendo que são utilizados as relações diretas e indiretas do IC para exibir quais ICs seriam afetados no caso do IC selecionado sofrer com algum tipo de mal-funcionamento.
Da mesma forma, ao clicar no botão Dependency Analisys:

É exibida a árvore de dependências do IC.
Importante perceber que as árvores de impacto e dependência representam mais do que as relações de composição de um IC. Um website, por exemplo, que depende de um banco de dados, apesentará essa dependência na árvore de dependências porém um website apenas depende de um banco da dados mas não o compõe. Essas relações são descobertas como parte do processo de discovery ou com o Priax Application Mapping através da interpretação dos dados de traces e transações.
Dependências de uma Aplicação
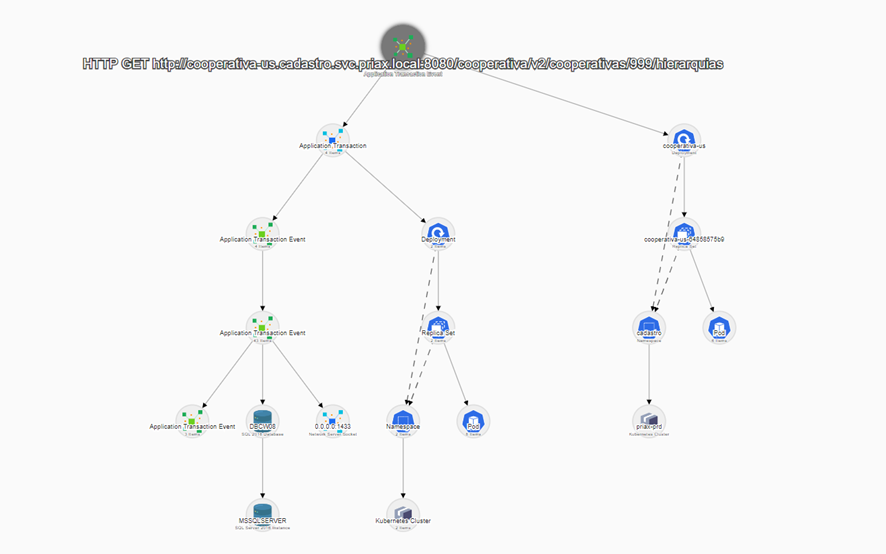
Para o Priax, uma Aplicação é representado como um tipo de Item de Configuraçao. Assim sendo, quando precisamos saber do que depende uma aplicação, basta navegar na árvore de ICs até onde as aplicações são armazenadas e realizar o procedimento acima para ver a árvore completa de dependências da Aplicação específica desejada.
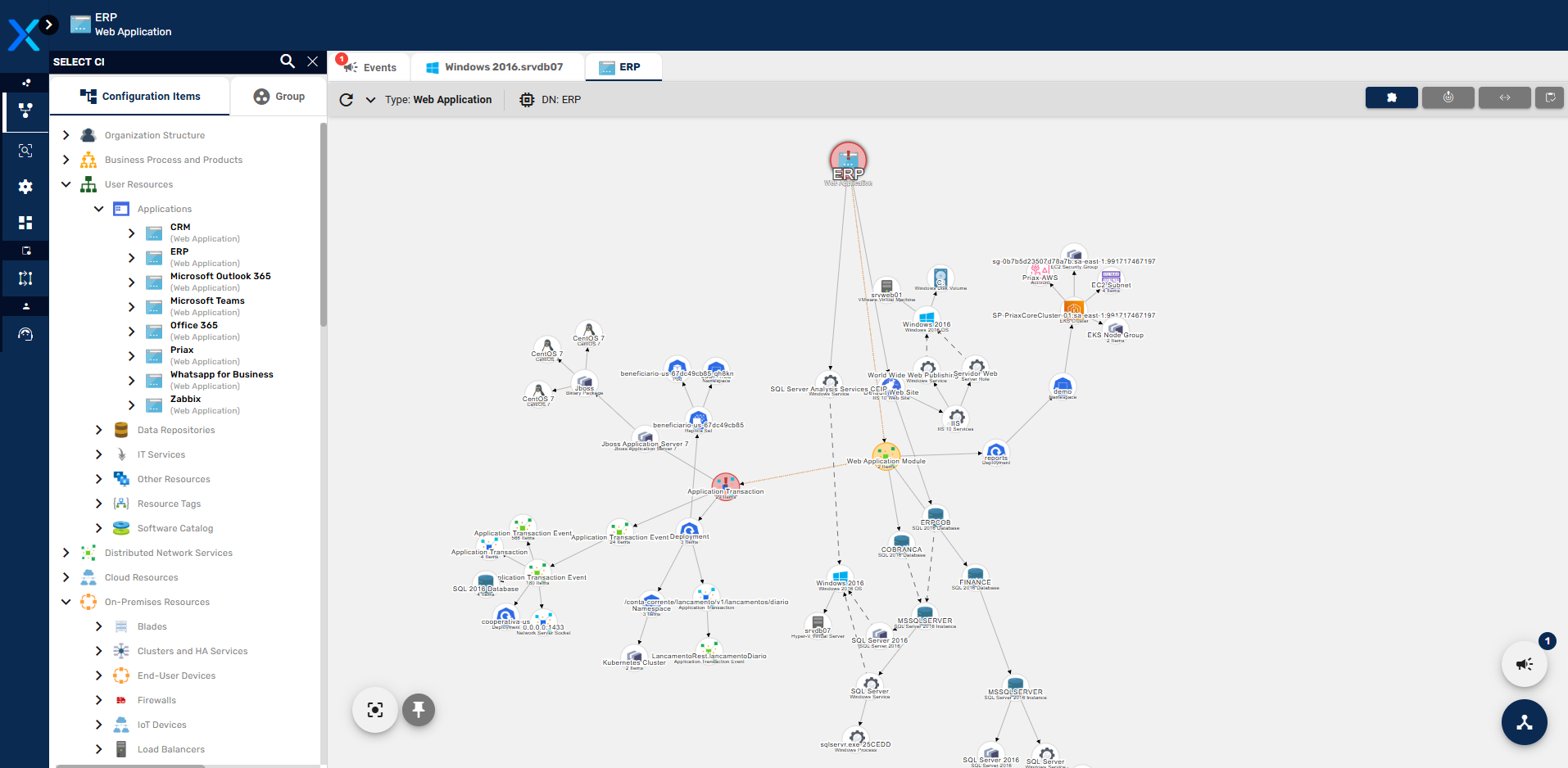
Na imagem acima, podemos ver as dependências de ima aplicação chamada ERP. Veja que a aplicação ERP está armazenada na árvore de ICs em User Resources\Applications\.
É importante entende que as relações entre a Aplicação e os componentes dos quais elas dependem são automaticamente criadas pelo componente Priax Application Mapping, que é um módulo especial de Discovery. Para entender mais sobre esse módulo veja o capítulo deste manual dedicado à esse módulo.
Análise de Indicadores em uma árvore de Dependências
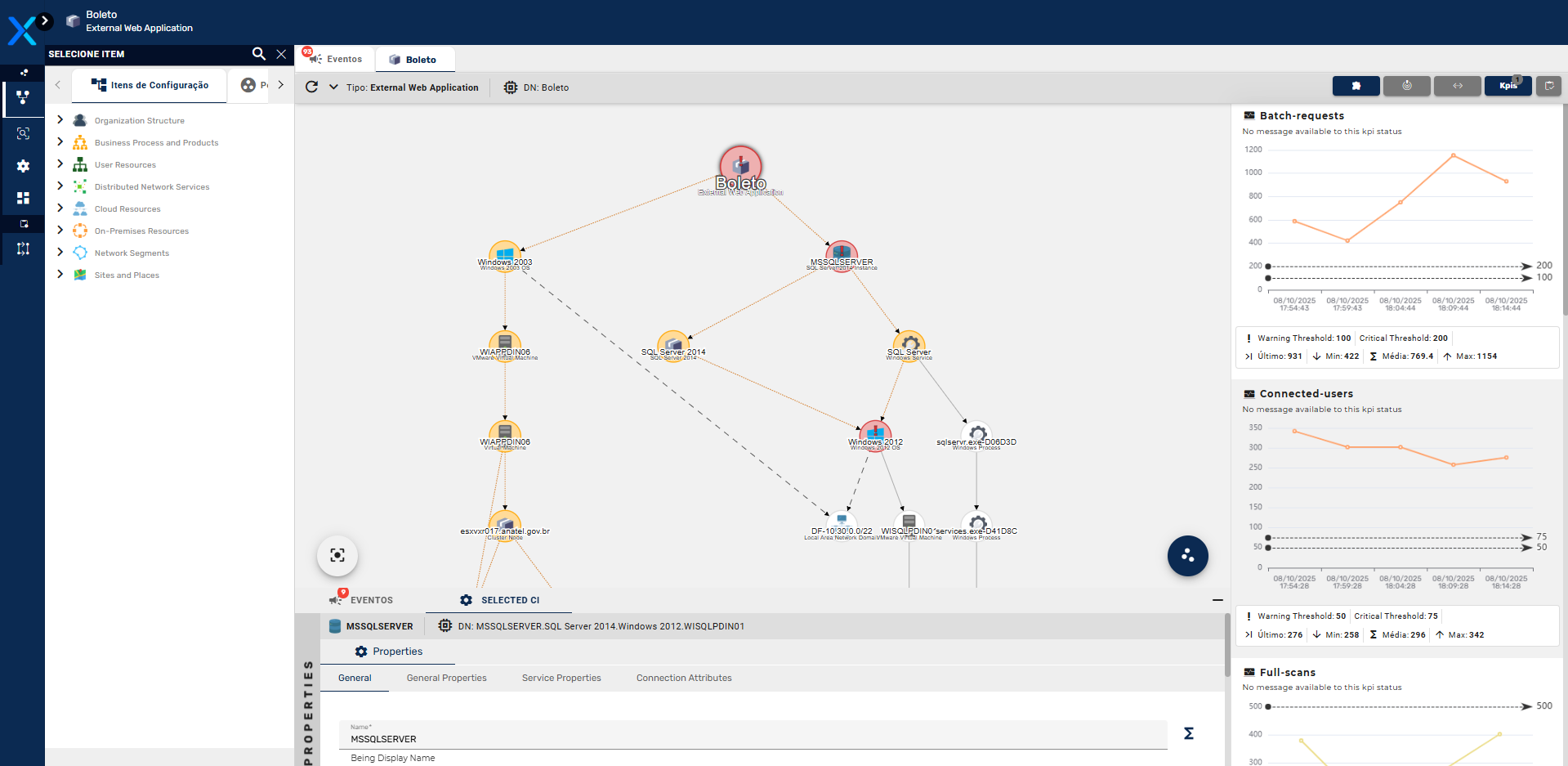
Ao clicar em qualquer componente da árvore de dependências seus indicadores são exibidos no lado direito da tela. Sempre que um IC apresentar um indicador que esteja fora da normalidade, pintará o IC na tela de amarelo, laranja ou vermelho de acordo com a gravidade da anormalidade.
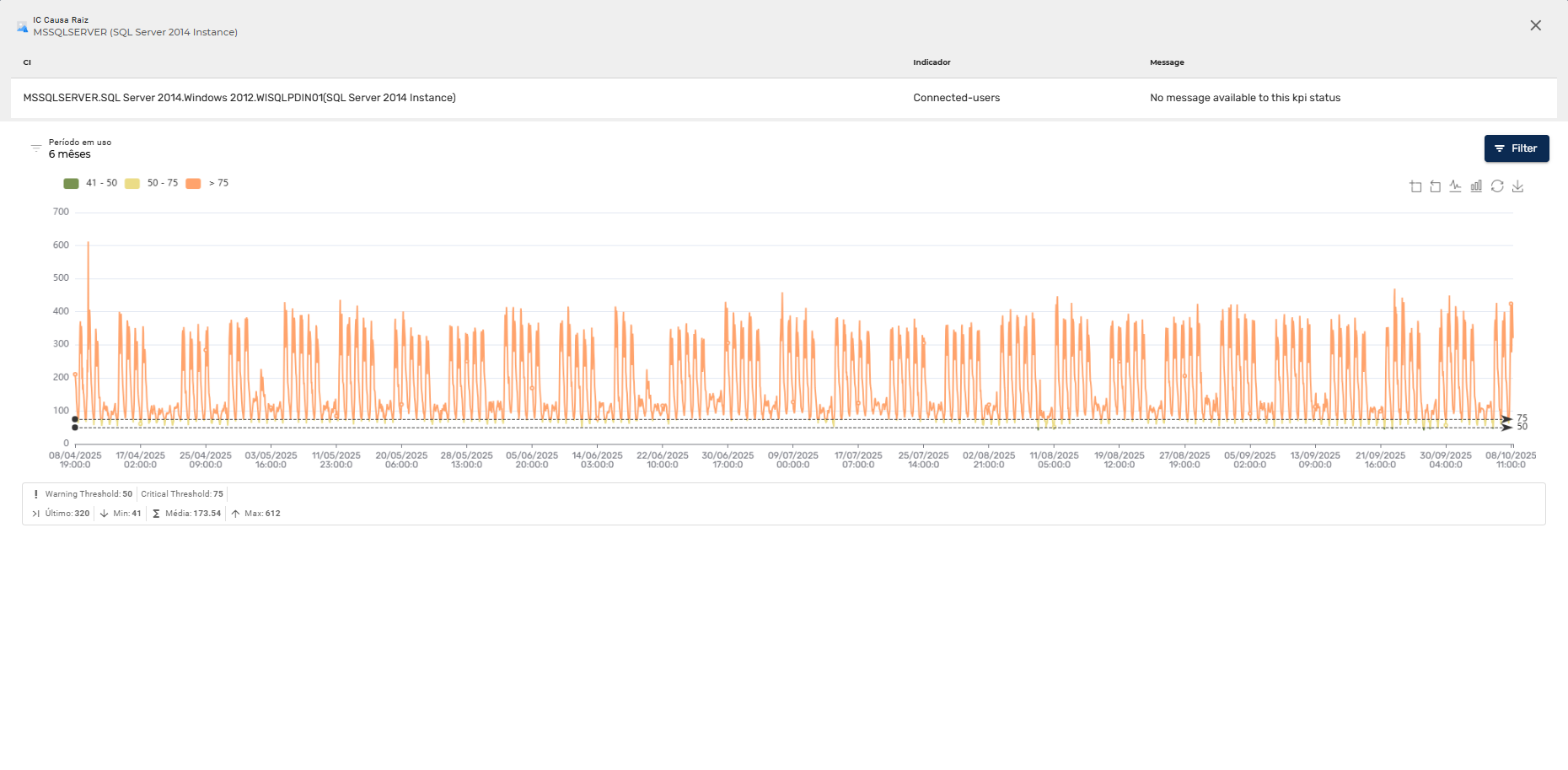
Todos os indicadores podem ser analisados de forma detalhada, customizando o período de tempo e o tipo de visualização desejado. Para isso, use o botão de expansão dentro do gráfico do indicador. Abaixo exemplo de Gráfico de linha exibido para 6 meses par ao indicador de tempo médio de execução de ima transação em 5 minutos.
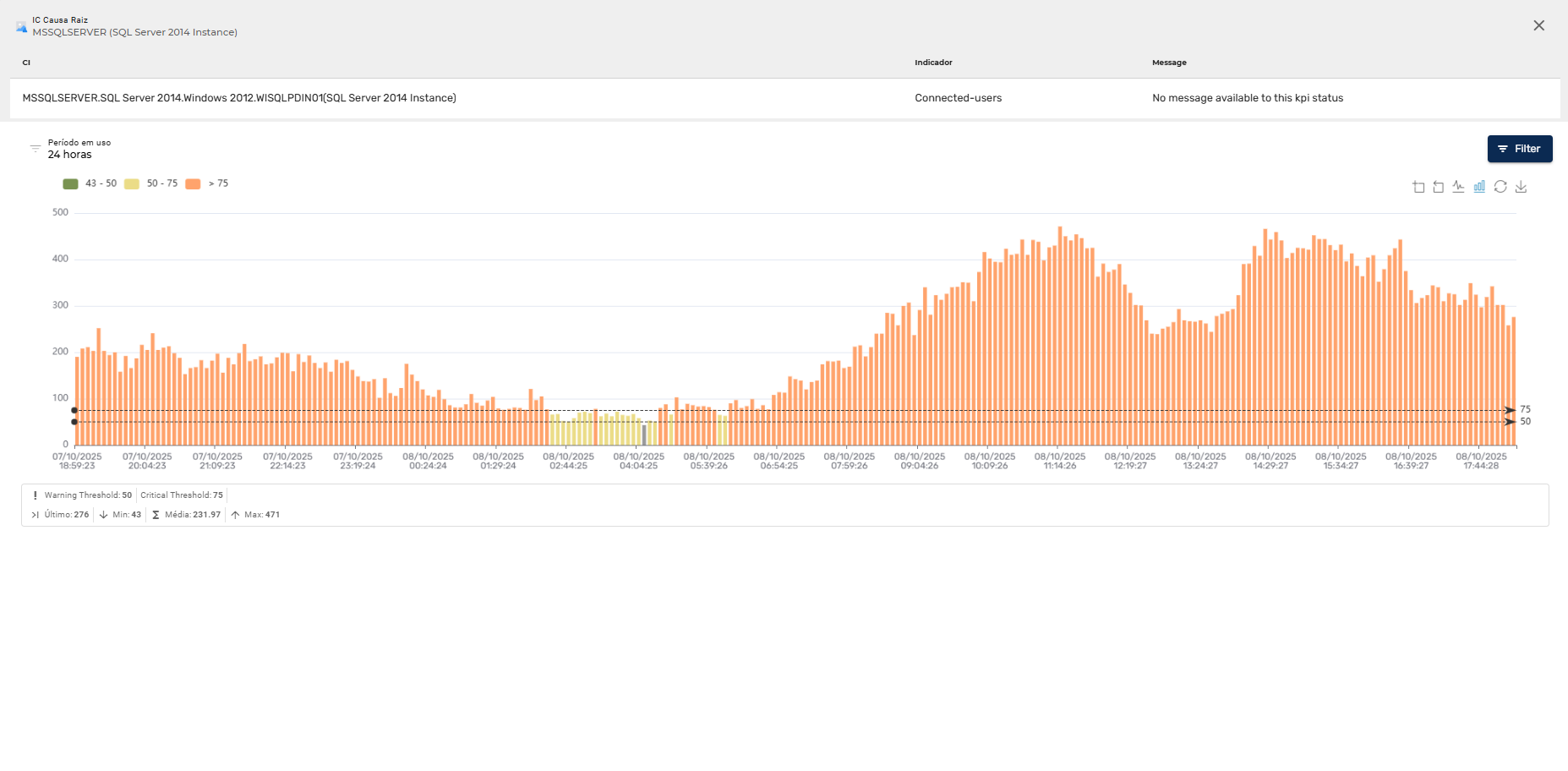
E abaixo o mesmo indicador exibido em gráfico de barras para um período curto de algumas horas.
Tipos de IC Nativos e Templates
O Priax permite a detecção de Itens de Configuração customizados de forma muito flexíve. Tipos de Itens de Configuração customizados podem ser criados e scripts de reconhecimento podem ser utilizados para detectar esses novos tipos de IC. Esse nível de customização praticamente torna possível que o Priax detecte todo o tipo de IC da infraestrutura e a partir e de diversos executores com diferentes tecnologias base. No entanto, nativamente são detectados mais de oito mil tipos de ICs.
Segue uma lista de alguns dos principais Itens de Configuração detectados pelo Priax, lembrando que a lista completa possui mais de 8 mil tipos de itens de configuração:
- Sistemas Operacionais Microsoft Windows Server (Todos com suporte ativo)
- Indicadores do Sistema Operacional
- Memória e Paginação
- CPU física e Virtual
- Discos Físicos do Sistema Operacional
- Discos lógicos do Sistema Operacional
- Interfaces de rede
- Atividade por protocolo de camada 2 e 3
- Erros
- Tráfego in e out
- Socket de Rede
- Atividade TCP e UDP (Camada 4 de rede)
- Serviços do Sistema Operacional
- Processos do Sistema Operacional
- Programas Instalados no Sistema Operacional
- Todas as funcionalidades nativas (Roles) do sistema operacional
- Indicadores do Sistema Operacional
- Sistemas Operacionais Linux (Distros: Oracle Linux, RedHat, Debian, Suse, Ubuntu, entre outras)
- Indicadores do Sistema Operacional
- Memória e Paginação
- CPU física e Virtual
- Discos Físicos do Sistema Operacional
- Discos lógicos do Sistema Operacional
- Interfaces de rede
- Atividade por protocolo de camada 2 e 3
- Erros
- Tráfego in e out
- Socket de Rede
- Atividade TCP e UDP (Camada 4 de rede)
- Serviços do Sistema Operacional
- Processos do Sistema Operacional
- Programas Instalados no Sistema Operacional
- Pacotes de Software nativas do Sistema Operacional (DEB, RPM)
- Indicadores do Sistema Operacional
- Hypervisors, seus cluters, Sites, Máquinas Virtuais, Storages
- VMWare
- Hyper-V
- Xen Server
- Tecnologia VmWare (SNMP e API)
- Datacenters
- Clusters
- Servidores Físicos
- Máquinas Virtuais
- Storages
- Networks e Port Groups
- Bancos de Dados (Postgre SQL MySQL, Microsoft SQL Server, Oracle DB, Oracle RAC, Mongo DB, IBM DB2, Cassandra)
- Instância do Banco de Dados
- Database
- Tabelas
- Campos de Tabelas
- Instâncias de Servidores de Aplicação, seus deployments, websites, aplicações ou equivalente
- Microsoft IIS
- NGINX
- Apache
- Tomcat
- Wildfly
- JBoss
- Oracle WebLogic
- Serviços de Mensagens e Filas
- Kafka
- RabbitMQ
- JMS
- MQ
- Outros dispositivos
- Servidores Físicos (Dell, HP, IBM, HUAWEI, CISCO, etc.)
- Componentes de Hardware
- Discos lógicos e físicos
- Interface de Rede
- Periféricos
- Interfaces de Gerenciamento
- Switches (Cisco, Dell, 3Com, Extreme, EdgeCore, HPE, etc.)
- Interfaces (portas)]
- Roteadores
- Interfaces do Roteador
- Equipamentos relacionados à Segurança da Informação:
- Soluções de Antivírus
- Soluções de AntiSpam
- Soluções de Unified Threat Management
- Soluções Network Access Control
- Equipamentos de Firewall
- Storages (EMC, HP, DELL, HUAWEI, ETC)
- Discos Físicos
- Grupos de Disco
- Discos Lógicos
- Servidores Físicos (Dell, HP, IBM, HUAWEI, CISCO, etc.)
- Rede
- Monitoramento de tráfego, consumo e latência de Rede de forma passiva e ativa, utilizando técnicas que independem de fabricantes ou utilizando protocolos proprietários e Open Source.
- Soluções de Backups e Rotinas de Backups
- Containers
- Docker
- Kubernetes e OpenShift
- Namespaces
- Deployments
- Replicasets
- Statefulsets
- Daemonsets
- Pods
- Services
- Ingress
- PV
- PVC
- Cloud Computing
- Discovery AWS
- Discovery Azure
- Discovery GPC
- OpenStack (Serviços cloud que utilizam tecnologia OpenStack)
- OCI - Oracle Cloud Interprise
- IBM Cloud