Guia de Administração
Priax 3.0 - Administration Book Brazilian Portuguese
- Conceitos
- O que é o Priax?
- Discovery e CMDB
- Observabilidade, Detecção e Gestão de Eventos
- Gerenciamento da Continuidade de Negócios
- Priax IT Operation Manager (ITOM)
- Instalação e Primeiros Passos
- Discovery, CMDB e Gestão de Ativos
- Introdução ao discovery do Priax
- Gestão de Ativos
- Discovery de Mapas de Aplicações
- Exibição de Dados e Navegação na CMDB
- Tipos de IC Nativos e Templates
- Observabilidade de Capacidade e Disponibilidade da Infraestrutura de TI
- Introdução à Observabilidade de Infraestrutura de TI
- Seleção e Customização de ICs e Indicadores a serem Observados
- Priax Performance and Availability Agent
- Exibição de Indicarores dos Itens de Configuração
- Indicadores Nativos e Templates
- Observabilidade de Aplicações (APM)
- Introdução à Observabilidade de Aplicações
- Sinais e Métricas das Aplicações
- Instrumentação com Bibliotecas OpenTelemetry
- Ingestão de Dados e Backend de Armazenamento
- Visualização de Dados de Aplicações
- Gestão de Operações e Eventos (ITOM)
- Introdução à Gestão de Eventos
- Seleção e Customização de ICs e Indicadores a serem Observados
- Criação de Regras de Reação
- Recepção e Tratamento de Eventos
- Gestão de Equipes e Usuários
Conceitos
O que é o Priax?
O Priax é uma ferramenta abrangente para gestão de operações de TI que oferece funcionalidades de discovery, observabilidade full stack, gestão de eventos e automação. Ele centraliza informações em uma CMDB (Banco de Dados de Gerenciamento de Configuração) compatível com ITIL, permitindo a coleta e análise de dados de toda a infraestrutura de TI, seja on-premises ou em cloud. O Priax utiliza IA e análise de dados para facilitar a criação de mapas de dependências, a identificação de problemas, a gestão de ativos, a conformidade e governança, além de suportar planejamento de continuidade de negócios e a aplicação de AIOps para aumentar a produtividade das equipes de TI.
Funcionalidades do Priax
Discovery e Mapeamento
Descobrir, catalogar e armazenar de forma eficiente os componentes de sua infraestrutura de TI é o primeiro passo para um gerenciamento eficiente, afinal, não se gerencia o que não se conhece. O discovery do Priax utiliza diversas fontes de informação para criar um mapa completo e unificado de sua infraestrutura, relacionando logicamente os componentes de acordo com o funcionamento de cada tecnologia e com a utilização desses componentes pelas aplicações, criando mapas das dependências de forma automatizada disponibilizando essas informações em formato de relatórios, dashboards e painéis interativos que permitem o compartilhamento seguro de informações entre os membros da equipe e permitindo a eficiente gestão de Eventos, Incidentes, Problemas, Mudanças e Conhecimento. Com o Priax você elevará rapidamente o nível maturidade do gerenciamento de sua Infraestrutura e obterá as seguintes vantagens:
- Construção rápida e automatizada da CMDB através do poderoso sistema de Discovery
- Visibilidade completa e unificada da infraestrutura de TI
- Dashboards e Relatórios
- Gestão de Ativos
- Conformidade e Governança
- Automação e Orquestração
- Criação de CMDB e Integrações
Observabilidade, Detecção e Gestão de Eventos
O módulo de Observabilidade do Priax que permite a coleta de dados de Disponibilidade, Capacidade, Configurações, Logs e Eventos de Segurança a respeito dos Itens de Configuração, além de dados de performance de Aplicações, através de Tracing de suas transações. São armazenados dados históricos e gerados Alertas e Notificações para as equipes responsáveis por agir em cada situação distinta. O Priax possibilita a observabilidade completa da infraestrutura e de aplicações incluindo:
- Monitoramento de Disponibilidade e Capacidade de Aplicações e Infraestrutura
- Coleta e Análise de Logs
- Detecção de Eventos de Segurança
- Mudanças em Configurações e Atributos dos ICs
- Coleta e Análise de Logs, Traces e Métricas de Aplicações
- Coleta e Análise de Comportamento do Usuário (RUM)
- Monitoramento e Análise de Desempenho da Aplicação
- Monitoramento e Análise dos Acessos e Segurança de Aplicações
- Coleta e Análise de Transações de Negócios
Planejamento de Continuidade de Negócios
Em um mundo onde praticamente todas as atividades humanas estão cada vez mais dependentes de tecnologias devemos estar preparados para agir no caso de algum evento inesperado interromper o fornecimento de tais recursos por determinado período. Para podermos ter um plano de ação com o intuito de continuar a operar sem determinado recurso tecnológico, precisamos entes de mais nada entender quais são os recursos utilizados em cada atividade, como estes recursos são fornecidos, suas dependências na infraestrutura de TI e identificar quais são os eventos que podem ocorrer e prejudicar seu fornecimento. Depois disso, precisamos documentar o plano de ação para continuar operando e para recuperar o funcionamento de acordo com seus níveis de serviços ideais.
Um sistema de BCP ajuda você a realizar essas atividades, e manter esses planos atualizados ao longo do tempo. Com esse intuito o Priax oferece:
- Avaliação de riscos aplicação de Business Impact Analysis
- Desenvolvimento de estratégias de continuidade
- Desenvolvimento de estratégia de recuperação
- Documentação de processos e procedimentos
- Testes e exercícios
- Atualização e revisão contínua
- Gerenciamento de Comunicação
IT Operation Manager (ITOM) e AIOPS
O ITOM e AIOps são conceitos que estão revolucionando a forma como ambientes de TI são gerenciados. A crescente complexidade dos ambientes de TI e sistemas e a dinamicidade cada vez mais veloz em que os ambientes se transformam exigem que se forneça ferramentas de gerenciamento que sejam capazes de fazer com que as equipes de TI consigam dar conta de todas as suas atividades, mantendo o custo sob controle. Atualmente é comum que equipes de TI estejam dispersas geograficamente, mas a necessidade de agir de forma coordenada e sem barreiras de comunicação é cada vez maior.
Neste contexto, o Priax ITOM oferece um ambiente de trabalho para profissionais de TI que atentem justamente estas necessidades de apresentação, interpretação e análise de dados além da automatização de processos, comunicação e registro de atividades realizadas para solução das mais diversas demandas que o ambiente de TI necessite. Com ele é possível realizar:
- Análise avançada dos dados de Observabilidade
- Correlação de eventos e análise de causa-raiz
- Aprendizado de ações corretivas e execução de resposta automatizadas
- Automação de tarefas e criação de Runbooks
- Análise preditiva e preventiva
- Gerência de Eventos, Incidentes, Problemas e Mudanças de forma integrada e interativa entre múltiplas equipes e pessoas
- Gerenciamento de níveis de serviço (SLA)
- Alertas, notificações, registro de atividades e comunicação intra e inter equipes
Discovery e CMDB
Um Sistema de Gerenciamento de Banco de Dados de Configuração (CMDB) é uma ferramenta essencial para organizações que desejam ter um controle eficiente e preciso de sua infraestrutura de TI. Juntamente com um sistema de discovery, a CMDB do Priax é base para todos os processos de gestão oferecidos pelo Priax. Com a CMDB Priax você elevará rapidamente o nível maturidade do gerenciamento de sua Infraestrutura e obterá as seguintes vantagens:
- Construção rápida e automatizada da CMDB através do poderoso sistema de Discovery que através de diversos módulos de integração possibilita o cadastro do Itens de Configuração e suas relações sem a necessidade de processos manuais e custosos.
- Discovery Contínuo e Automatizado: O Discovery do Priax, após ativado é executado continuamente, insere e remove itens de configuração na CMDB sem a interação do usuário.
- Obtenção de visibilidade completa da infraestrutura de TI fornecendo uma representação centralizada de todos os componentes, ativos e relacionamentos da infraestrutura, incluindo servidores, dispositivos de rede, software, aplicativos e outros elementos críticos.
- Construção de Dashboards e Relatórios customizados, utilizando qualquer atributo ou configuração dos Itens de Configuração do ambiente, possibilitando a navegação nos dados de sua infraestrutura em painéis no estilo BI.
- Gestão de Ativos e planejamento de capacidade com insights valiosos sobre a capacidade atual e futura de sua infraestrutura de TI. Eles podem identificar gargalos, otimizar a utilização dos recursos, planejar adequadamente as expansões e aquisições de ativos e garantir que os ativos estejam alinhados com as necessidades de negócios.
- Conformidade e governança: A CMDB Priax permite que as organizações mantenham um registro preciso e rastreável de todos os itens de configuração e suas alterações. Isso é especialmente importante para fins de conformidade regulatória e governança de TI. O CMDB ajuda a documentar as políticas e processos relacionados à configuração dos ativos, bem como a auditar e rastrear as alterações para garantir a conformidade com os requisitos internos e externos.
- Automação e orquestração: A integração da CMDB com outras ferramentas de gerenciamento de TI permite a automação de tarefas rotineiras e a orquestração de processos complexos. Isso reduz a carga de trabalho manual, minimiza erros humanos e melhora a eficiência operacional.
- Mapeamento automático de Dependência de Aplicações: O discovery em conjunto com o módulo de APM, pode realizar o mapeamento de todas as dependências das aplicações de negócio baseando-se no seu funcionamento real e identificando na CMDB quais são exatamente os Itens de Configurações consumidos por essa aplicação. Além de apresentar mapas de dependência, o resultado desta descobertas é usado para identificar em tempo real automaticamente os impactos de um evento, incidente ou problema, no planejamento de mudanças, nas simulações de impactos e dependência e nos processos de planejamento de continuidade de negócios.
- Integrações com sistemas adjacentes que podem se beneficiar das informações adquiridas pelo discovery ou interagir com a CMDB para reportar informações adicionais.
Em resumo, o CMDB do Priax oferece vantagens significativas para sua organização, incluindo visibilidade aprimorada, gerenciamento eficiente de mudanças, resolução rápida de problemas, planejamento de capacidade, conformidade, automação e orquestração. Essas vantagens combinadas ajudam a melhorar a disponibilidade, confiabilidade e desempenho da infraestrutura de TI, permitindo que as organizações sejam mais ágeis e responsivas às demandas do negócio.
Observabilidade, Detecção e Gestão de Eventos
O módulo de Observabilidade do Priax que permite a coleta de dados de Disponibilidade, Capacidade, Configurações, Logs e Eventos de Segurança a respeito dos Itens de Configuração, além de dados de performance de Aplicações, através de Tracing de suas transações. São armazenados dados históricos e gerados Alertas e Notificações para as equipes responsáveis por agir em cada situação distinta.
-
Monitoramento de Disponibilidade e Capacidade de Aplicações e Infraestrutura
O Priax coleta dados em tempo real sobre o desempenho e a disponibilidade de Aplicações e suas transações e dos itens de configuração de TI presentes na CMDB, como servidores, bancos de dados, aplicativos, redes e dispositivos de armazenamento, bancos de dados, serviços, websites etc. Os dados são coletados continuamente com a finalidade de identificar problemas potenciais antes que eles afetem os serviços. Isso pode incluir a detecção de picos de uso, falta de capacidade, quedas de desempenho e falhas de hardware. São enviados alertas e notificações imediatas quando ocorrerem problemas ou quando determinados limiares forem atingidos. Isso permite que a equipe de TI responda prontamente e minimize o impacto nas operações.
Para a visualização de dados históricos, o Priax possui uma interface visual intuitiva para exibir informações de desempenho e disponibilidade de forma clara e compreensível, sempre vinculado ao IC correlacionado. Além disso é possível gerar relatórios personalizados para acompanhar tendências, identificar gargalos e tomar decisões informadas sobre a capacidade do sistema além de realizar previsões de capacidade futura, ajudando a identificar possíveis gargalos ou necessidades de expansão antes que se tornem problemas reais. Além disso, o Priax é integrável com outros sistemas de gerenciamento e monitoramento, sistemas de gerenciamento de serviços (ITSM) e plataformas de automação, para permitir ações rápidas e automatizadas com base nos dados coletados. -
Coleta e Análise de Logs
Uma ferramenta de coleta e análise de logs de TI é fundamental para monitorar e investigar eventos em hosts, sistemas, aplicativos e dispositivos de TI. O módulo de coleta e análise de Logs do Priax coleta logs de diferentes fontes, como servidores, roteadores, firewalls, sistemas operacionais e aplicativos, e envia para uma base de dados centralizada, vinculando cada log com o Item de Configuração correspondente facilitando o acesso, filtragem e a análise dos logs em um único local. Com os logs centralizados, são oferecidos mecanismos de filtragem e pesquisa avançada para localizar logs específicos com base em critérios como data, hora, origem, tipo de evento ou palavras-chave. Isso facilita a análise de eventos relevantes e a solução de problemas.
O Priax ainda é capaz de realizar análise estatística, identificar tendências, padrões ou anomalias nos logs ao longo do tempo além de correlacionar eventos de diferentes fontes para ajudar a identificar relações de causa e efeito entre diferentes registros. Isso é especialmente útil para investigar incidentes e entender melhor o contexto em que ocorreram e revelar insights valiosos sobre o desempenho, a segurança e a conformidade dos sistemas. Além disso, o Priax permite a configuração de alertas e notificações com base em determinados eventos ou padrões nos logs. Isso ajuda a detectar problemas em tempo real e a responder rapidamente a eventos críticos. -
Detecção de Eventos de Segurança
Através da análise de logs com regras Sigma, o Priax pode identificar padrões que caracterizam ameaças conhecidas de segurança fornecendo uma visão em tempo real das atividades de segurança em uma rede, host ou sistema. Ele pode gerar alertas imediatos quando eventos suspeitos ou maliciosos são detectados. Atuando, portanto, como um SIEM, o Priax armazena logs e eventos de segurança em base de dados OpenSearch, permitindo a análise retrospectiva e a investigação de incidentes passados oferecendo recursos de pesquisa e análise avançados para identificar padrões e anomalias nos dados de segurança.
Os eventos são correlacionados, independente da fonte onde foi coletado para fornecer contexto e insights sobre as atividades de segurança, correlacionando cada evento de segurança detectado com o respectivo Item de Configuração ao qual ele se refere na CMDB sendo capaz de identificar relacionamentos entre eventos aparentemente não relacionados, ajudando a detectar ameaças avançadas e ataques complexos. -
Mudanças em Configurações e Atributos dos ICs
A Auditoria de Configurações é a capacidade de uma ferramenta coletar, armazenar histórico e gerar alertas sobre alterações nos atributos e nas configurações dos ICs. O Priax realiza estas tarefas sobre os elementos cadastrados na CMDB, criando o controle necessário para implementar na práticas as políticas de mudanças e para facilitar o diagnóstico em casos de eventos causados por mudanças mal sucedidas. Com o armazenamento do histórico de cada mudança ocorrida em cada IC, podem ser realizadas análises retrospectiva, investigação e diagnóstico de eventos e incidentes, além de permitir a restauração de configurações anteriores para reestabelecer o funcionamento adequado de sistemas. -
Application Performance Monitoring (APM)
Além disso, o módulo de APM (Application Performance Monitoring) que permite o monitoramento de cada transação ocorrida internamente em cada aplicação e, alimenta o Discovery com dados que possibilitam o automático mapeamento das dependências das Aplicações monitoradas, correlacionando os Itens de Configuração consumidos cada aplicação.
O Priax possui um módulo de APM (Application Performance Monitoring) com capacidade de monitorar e gerenciar o desempenho de aplicativos em tempo real, coletando e analisando métricas relevantes, como tempo de resposta, taxa de erros, utilização de recursos (CPU, memória, disco), latência de rede e outros indicadores de desempenho. Além disso, realiza o monitoramento de transações e rastreamento de chamada de sistema, permitindo identificar gargalos e problemas de desempenho em chamadas de serviço, operações de banco de dados e outros componentes envolvidos nas transações. Todos esses dados alimentam também o Discovery com dados que possibilitam o automático mapeamento das dependências das Aplicações monitoradas, correlacionando os Itens de Configuração consumidos cada aplicação.
Todas essas funcionalidades oferecem recursos de detecção e diagnóstico de problemas de desempenho, ajudando a identificar a causa-raiz de problemas, como lentidão, erros ou falhas no aplicativo. Isso inclui a capacidade de rastrear a sequência de eventos e correlacionar dados de várias fontes para uma análise mais profunda e permitir a identificação de tendências e a capacidade para ajudar a prever e planejar o desempenho futuro do aplicativo. Isso inclui a identificação de padrões de uso, demanda de recursos e estimativas de crescimento para garantir uma infraestrutura escalável e adequada.
Para entregar tais resultados o APM se utiliza das seguintes funcionalidades:
a. Coleta e Análise de Logs, Traces e Métricas
O Priax APM realiza uma coleta e análise abrangente de logs, traces e métricas, realizando a observação Fim-a-Fim das Aplicações, registrando e avaliando os seguintes pontos:
- Requisição do usuário: Captura as ações do usuário no navegador, incluindo clicks e carga de páginas, gerando tráfego no servidor e registrando os tempos de atendimento de requisições ao navegador do usuário.
- Execução de métodos e trechos de códigos fontes: Monitora a execução do código nos servidores de aplicação.
- Consultas a bancos de dados: Analisa as consultas realizadas aos servidores de banco de dados.
- Identificação de comunicação HTTP(s): Detecta webservices e chamadas a serviços externos das transações de uma aplicação.
- Contexto de execução de métodos e transações: Correlaciona e contextualiza as transações das aplicações com os logs monitorados.
- Suporte a Diferentes Tipos de Métricas: A solução suporta métricas como tempo de resposta, latência e throughput, permitindo uma análise detalhada de métricas específicas (drill-down).
- Armazenamento e Análise de Histórico de Métricas: O histórico de métricas é armazenado para permitir análises retroativas, identificando padrões e tendências de desempenho.
- Análise Detalhada de Traces: A ferramenta permite um drill-down para análise detalhada de traces específicos, facilitando a investigação aprofundada de eventos.
- Rastreamento de Dados em Tempo Real: Os dados (traces) são rastreados em tempo real a partir de diferentes fontes, permitindo a identificação automática e inteligente do impacto do problema e sua causa raiz.
- Configuração Automática de Limites e Alertas: A ferramenta configura automaticamente os limites de cada indicador para os quais devem ser gerados alertas. Tal aprendizado é baseado em dados históricos do comportamento do ambiente e suas aplicações que são usados para ajustar automaticamente o comportamento da ferramenta. Este baseline de comportamento permite detectar desvios no comportamento das aplicações/transações, evitar falsos positivos e falsos negativos.
- Definição Inteligente de Critérios para Problemas e Incidentes: A solução define automaticamente e de forma inteligente os critérios para problemas e incidentes, considerando o histórico e o comportamento do ambiente.
Identificação de Problemas e Erros: A solução identifica problemas e erros no ambiente, analisando automaticamente os incidentes e os relacionamentos entre os componentes. Utiliza inteligência artificial para separar causa e efeito, apontando problemas agrupados em tempo real e mantendo um histórico dos problemas ocorridos.
b. Coleta e Análise de Comportamento do Usuário
A solução de observabilidade oferece funcionalidades avançadas para a coleta e análise do comportamento dos usuários das aplicações, atendendo a diversos requisitos específicos tais como:
- Identificação do Perfil dos Usuários: A solução coleta e identifica o perfil dos usuários das aplicações, considerando dados como localização física do usuário, tipo de dispositivo navegador, sistema operacional, tempo de acesso, quantidade de requisições, tempo médio de permanência, registro de cliques e uso de serviços.
- Identificação de Usuários que regressam à aplicação.
- Correlação de Dados de Comportamento: Os dados de comportamento dos usuários são correlacionados com métricas de negócio e de desempenho, proporcionando uma visão integrada do impacto do comportamento do usuário nas operações.
- Integração com Ferramentas de Análise de Experiência: A solução permite a integração com ferramentas de análise de experiência do usuário, como mapas de calor, para uma análise visual detalhada.
- Análise das Atividades de Acesso: A solução coleta e analisa a forma de acesso às aplicações, identificando atividades de entrada e atividades de saída, registrando o volume e o tempo médio de duração dessas atividades.
- Verificação da Performance das Ações dos Usuários: A ferramenta verifica a performance das ações dos usuários, exibindo na linha do tempo a quantidade de ações, a duração, a situação e o tempo de execução das ações.
- Informações sobre Ações dos Usuários: Disponibiliza informações detalhadas sobre as principais ações dos usuários nas aplicações, indicando o total de ações executadas por período e exibindo informações sobre o tempo de contribuição das ações, incluindo o tempo total da experiência, tempo de execução do servidor, tempo de renderização do HTML, tempo de DNS e tempo de conexão com o servidor.
- Informações sobre Erros de JavaScript: Para erros de JavaScript identificados nas aplicações, a solução apresenta informações detalhadas como sistema operacional de origem, navegador, localidade e ação que gerou o erro, indicando a quantidade de erros ocorrida por categoria.
- Compatibilidade com com métricas de experiência de usuários baseados no Google Core Web Vitals.
c. Monitoramento e Análise de Desempenho da Aplicação
A solução oferece funcionalidades abrangentes para monitoramento e análise de desempenho das aplicações hospedadas em um Data Center incluindo: - Monitoramento de Performance de Servidores de Aplicação (APM): Monitora a performance de servidores de aplicação conforme as características e tecnologias especificadas.
- Identificação de Problemas e Causa Raiz: A solução identifica problemas ou incidentes nas aplicações, apontando automaticamente a causa raiz e indicando a camada onde o problema ocorreu (ex.: aplicação, serviço, webservice, servidor, web, rede, usuário).
- Suporte à ampla lista de tecnologias: Monitora aplicações construídas com a maioria de pilhas tecnológicas de back-end e front-end.
- Comparação de Desempenho: Permite a comparação do desempenho das aplicações pela perspectiva do usuário.
- Informações sobre Aplicações: Proporciona informações sobre número de sessões, requisições HTTP, tempo de atendimento, volume de falhas dos serviços e dependências do serviço.
- Tempo de Carregamento de Página: Coleta e analisa o tempo exato de carregamento da página até que esteja completamente pronta para uso, separando a métrica por localidade, tipo de dispositivo, localização, sistema operacional ou tipo de navegador.
- Análise de performance de aplicações adjacentes: Verifica automaticamente a performance e disponibilidade dos principais serviços acessados pela aplicação instrumentada, mesmo que tais aplicações adjacentes não estejam instrumentadas, extraindo dados a respeito de médias de latência, transferência de dados e taxa de transações com falhas.
- Descoberta Automática de Processos e Dependências: Descobre automaticamente todos os processos, serviços, aplicações e suas respectivas dependências entre hosts e processos.
- Topologia Dinâmica da Aplicação: Descobre automaticamente a topologia da aplicação, apresentando um mapa completo e atualizado das dependências entre componentes sem intervenção manual.
- Visualização da Performance do Ambiente: Acompanha a performance do ambiente de forma visual, verificando latência, transferência de dados e taxa de erros por serviço, identificando o código-fonte dos erros.
- Análise Detalhada de Serviços e Métodos: Verifica a performance dos serviços e métodos, monitorando tempos de resposta, utilização de CPU, requisições por período, taxas e quantidade de falhas.
- Identificação de Dependências de Serviços: Identifica as aplicações que usam serviços específicos e os bancos de dados e comandos SQL acessados.
- Fluxo Gráfico das Requisições: Apresenta um fluxo gráfico das requisições que chamam e que são chamadas por um serviço em análise.
- Verificação de Performance de Garbage Collection: Monitora a execução e a performance dos processos de Garbage Collection.
- Distribuição dos Tempos de Resposta: Produz gráficos de tempos de resposta detalhando a distribuição por fases da transação e pelo métodos do código fonte para identificar a distribuição do tempo total utilizado para atendimento de cada requisição.
- Visão Gráfica do Ambiente: Apresenta uma visão gráfica da aplicação monitorada, contendo mapas, painéis e gráficos personalizados das principais métricas e análises, permitindo filtros por períodos históricos.
- Mapeamento Automático de Componentes: Mapeia automaticamente os componentes e seus relacionamentos que sustentam as aplicações, incluindo serviços, processos e infraestrutura.
- Métricas de Ações indexados por Usuários: Apresenta métricas como volume de dados baixados, tempo médio de interatividade do usuário, tempo no servidor, tempo no navegador e tempo de tráfego de rede.
- Monitoramento de Recursos de Infraestrutura: Correlaciona dados de infraestrutura com os dados da aplicação monitorada na mesma escala de tempo.
- Monitoramento de execuções SQL: Monitora a execução das instruções SQL, apresentando quantidade de execuções, taxa de falhas e tempo médio de resposta criando gráficos da distribuição dos tempos de resposta das consultas a banco de dados.
- Rastreamento de Aplicações e Serviços: Permite rastreamento das aplicações e serviços que executaram comandos de banco de dados.
- Correlacionamento de Problemas com Deploy: Disponibiliza informações sobre eventos como restart ou deploy, correlacionando problemas com possíveis problemas no processo de deploy.
- Identificação e Análise de Falhas: Oferece funcionalidades para identificar e analisar falhas das aplicações, avaliando automaticamente os níveis de qualidade, gerando alertas, reduzindo a quantidade de eventos em ambientes críticos, e correlacionando subeventos.
- Detalhamento de Tempos de Execução: Apresenta detalhamento de tempos de execução em nível de classe, método e comandos SQL para transações com desvios de comportamento.
- Identificação Automática de Problemas: Identifica automaticamente transações, queries SQL e serviços de backend com baixa performance ou indisponíveis.
- Detalhamento de Métodos Executados: Exibe os métodos executados nas transações com problemas de performance sem necessidade de configuração manual.
- Impacto dos Problemas: Aponta o número de aplicações e componentes de infraestrutura afetados pelos problemas identificados.
d. Monitoramento e Análise dos Acessos e Segurança de Aplicações
A solução proporciona funcionalidades detalhadas para monitoramento e análise dos acessos e da segurança de aplicações tais como: - Identificação de Usuários Autenticados: Identifica o usuário que está acessando a aplicação, identificando a região de origem, qualidade do acesso, tipo de navegador, versão do sistema operacional, IP de origem e comportamento temporal das ações.
- Registro de estatísticas: Registra o número simultâneo de usuários e o tempo médio de permanência dos usuários às aplicações.
- Detecção Automática de Transações Críticas: Detecta automaticamente transações críticas para o negócio que apresentam problemas ou desempenho abaixo do esperado.
- Controle de Acesso e Permissões: Possui controle de acesso e permissões, permitindo criar e modificar grupos de perfis de acesso.
- Armazenamento e Indexação de Dados de Acesso: Armazena e indexa os dados de acesso de forma eficiente e escalável.
- Correlacionamento de Dados de Acesso: Correlaciona dados de acesso com métricas de infraestrutura, logs de erros e eventos para identificar possíveis causas raiz.
- Identificação de Vulnerabilidades em Tempo Real: Identifica vulnerabilidades em tempo real, sem a necessidade de um scanner periódico.
- Integração com Ferramentas de Segurança: Integra-se nativamente ou via APIs com ferramentas de análise de segurança, scanners de vulnerabilidades e ferramentas de análise estática de código.
- Regras personalizáveis de segurança: Define regras e política de análise de segurança personalizadas atendendo necessidades específicas das aplicações.
- Monitoramento em Tempo Real: Monitora a aplicação em tempo real para detectar possíveis violações de segurança ou atividades suspeitas.
- Integração com Provedores de Inteligência de Ameaças: Integra-se com provedores de inteligência de ameaças para receber informações atualizadas sobre ameaças conhecidas e novas.
- Exportação de Dados de Segurança: Permite a exportação de dados de segurança para outras ferramentas de análise ou armazenamento.
- Análise de criticidade de Risco de Vulnerabilidades: Gera automaticamente uma classificação de risco para cada vulnerabilidade.
- Detalhamento de Problemas de Segurança: Exibe o número de problemas de segurança abertos, as aplicações monitoradas com vulnerabilidades encontradas e as tentativas de acesso nessas vulnerabilidades.
- Listagem de Vulnerabilidades: Lista todas as vulnerabilidades detectadas no ambiente monitorado, pontuando-as de acordo com o nível de risco.
- Detecção e Alertas de Segurança: Permite o envio de alertas de segurança às equipes para fins de alerta e correção.
- Integração com Ferramentas de Segurança: Integra-se com firewalls de aplicação, soluções de detecção de intrusão e sistemas de gerenciamento de informações e eventos de segurança (SIEM).
e. Coleta e Análise de Transações de Negócios
O Priax oferece funcionalidades avançadas para coleta e análise de transações com interpretação de lógicas de negócio possibilitando uma análise com uma visão interpretativa que ofereça insights valiosos.
Neste sentindo o Priax oferece: - Análise em Tempo Real: A solução possibilita a análise de transações de negócio em tempo real para identificar ações relevantes de usuários executadas nas aplicações. Isso inclui evolução em etapas de processos, conversões, assinaturas, vendas, matrículas e qualquer outra ação que faça sentido para o negócio, podendo ser essas ações customizáveis.
- Correlação de Métricas: É possível realizar correlação de indicadores do negócio com métricas de desempenho de transações e infraestrutura proporcionando uma visão unificada do desempenho de negócios e de sistemas.
- Exportação de Dados: A solução permite a exportação de dados de transações de negócio para análise em outras ferramentas, facilitando a integração com sistemas de análise externa.
- Detecção Automática de Transações: A detecção de transações de negócio ocorre automaticamente ou via Opentelemetry, baseando-se em protocolos e tecnologias como HTTP/HTTPS, webservices, serviços de mensageria (Kafka, MQ), chamadas externas à sistemas externos, spring, entre outros métodos.
- Visão Gráfica da Topologia: Podem ser criados dashboards que representam a topologia de um processo de negócio, oferecendo uma representação visual do fluxo de negócios e da dependência, precedência e sucessão entre componentes.
- Monitoramento de Execuções: O monitoramento das execuções das transações de negócio inclui métricas mínimas como quantidade de execuções, tempos de resposta e volume de erros. Oferece um drilldown detalhado do código executado (classes e métodos) para transações que se desviam do padrão normal de funcionamento.
- Classificação e Quantificação de Execuções: A solução classifica e quantifica a execução das transações de acordo com o tempo de resposta e eventuais erros, fornecendo essa análise em nível de aplicação, transação de negócio e servidor de aplicação.
Gerenciamento da Continuidade de Negócios
Em um mundo onde praticamente todas as atividades humanas estão cada vez mais dependentes de tecnologias devemos estar preparados para agir no caso de algum evento inesperado interromper o fornecimento de tais recursos por determinado período. Para podermos ter um plano de ação com o intuito de continuar a operar sem determinado recurso tecnológico, precisamos entes de mais nada entender quais são os recursos utilizados em cada atividade, como estes recursos são fornecidos, suas dependências na infraestrutura de TI e identificar quais são os eventos que podem ocorrer e prejudicar seu fornecimento. Depois disso, precisamos documentar o plano de ação para continuar operando e para recuperar o funcionamento de acordo com seus níveis de serviços ideais.
Um sistema de BCP ajuda você a realizar essas atividades, e manter esses planos atualizados ao longo do tempo. Com esse intuito o Priax oferece:
- Análise de impacto nos negócios: Análise abrangente do impacto que diferentes incidentes ou interrupções podem ter nas operações e nos processos de negócios. Isso ajuda a identificar e priorizar as áreas críticas e as funções de negócios que requerem atenção especial durante uma crise.
- Avaliação de riscos: Permite a identificação e avaliação dos riscos que podem causar interrupções nos negócios, como desastres naturais, falhas de infraestrutura, ciberataques, entre outros. Isso ajuda a estabelecer medidas de mitigação adequadas para minimizar os impactos.
- Desenvolvimento de estratégias de continuidade: Facilita o desenvolvimento de estratégias e planos de ação para garantir a continuidade das operações durante uma interrupção. Isso inclui a definição de planos de resposta a emergências, planos de recuperação de desastres, planos de comunicação e outros planos específicos para diferentes cenários.
- Documentação de processos e procedimentos: Possibilita a documentação clara e detalhada dos processos e procedimentos necessários para implementar as estratégias de continuidade de negócios. Essa documentação deve ser facilmente acessível durante uma crise e servir como um guia para a equipe de resposta.
- Testes e exercícios: Auxilia na execução de testes e exercícios regulares para avaliar a eficácia dos planos de continuidade, identificar áreas de melhoria e familiarizar a equipe com os processos de resposta a incidentes. Isso ajuda a garantir que a organização esteja pronta para lidar com situações reais.
- ]Atualização e revisão contínua: Fornece os recursos para acompanhar e revisar os planos de continuidade e recuperação regularmente, levando em consideração as mudanças no ambiente, nos riscos, nas operações e nos requisitos regulatórios. Isso garante que os planos estejam alinhados com as necessidades atuais e efetivamente protejam os negócios.
- Gerenciamento de comunicação: Inclui recursos para gerenciar a comunicação durante uma crise, tanto internamente, com a equipe e funcionários, quanto externamente, com os clientes, fornecedores, parceiros e autoridades regulatórias. Isso ajuda a manter as partes interessadas informadas e a mitigar potenciais danos à reputação.
Priax IT Operation Manager (ITOM)
O ITOM e AIOps são conceitos que estão revolucionando a forma como ambientes de TI são gerenciados. A crescente complexidade dos ambientes de TI e sistemas e a dinamicidade cada vez mais veloz em que os ambientes se transformam exigem que se forneça ferramentas de gerenciamento que sejam capazes de fazer com que as equipes de TI consigam dar conta de todas as suas atividades, mantendo o custo sob controle. Atualmente é comum que equipes de TI estejam dispersas geograficamente, mas a necessidade de agir de forma coordenada e sem barreiras de comunicação é cada vez maior.
Neste contexto, o Priax ITOM oferece um ambiente de trabalho para profissionais de TI que atentem justamente estas necessidades de apresentação, interpretação e análise de dados além da automatização de processos, comunicação e registro de atividades realizadas para solução das mais diversas demandas que o ambiente de TI necessite. Com ele é possível realizar:
- Análise avançada dos dados de Observabilidade: permite analisar grandes volumes de informações operacionais de TI em tempo real pois apresenta dados correlacionados e interpretados, com análise de causa raiz e de impactos. Além disso apresenta eventos relevantes correlacionados, incluindo logs, métricas de desempenho, eventos, dados de monitoramento e outros registros relevantes para identificar padrões, anomalias e tendências que possam afetar a operação.
- Correlação de eventos e análise de causa-raiz: Correlaciona eventos e dados de várias fontes para identificar a causa-raiz de problemas de TI. Ele deve ser capaz de analisar relações complexas entre eventos e identificar as causas subjacentes para acelerar o diagnóstico e a resolução de problemas.
- Automação de tarefas e criação de Runbooks: capaz de aprender ações corretivas eficientes e sugeri-las ou até mesmo aplicá-las de forma automatizada, monitorando a eficiência de cada ação aplicada e repetindo as ações mais eficientes. Permite também a criação de runbooks para eventos conhecidos para que possam ser aplicados automática ou manualmente em eventos futuros de mesma característica.
- Automação de tarefas e workflows: Automatiza tarefas operacionais rotineiras, como monitoramento de eventos, triagem de incidentes, gerenciamento de tickets, aprovações, execução de fluxos de trabalho, provisionamento e escalonamento. Isso reduz a carga de trabalho manual e aumenta a eficiência das operações de TI.
- Análise preditiva e preventiva: aplica técnicas de aprendizado de máquina e análise preditiva e sugere medidas proativas para evitar falhas, possíveis problemas e interrupções de TI antes que ocorram ou reduzir o tempo de inatividade.
- Gerência de Demandas de TI e Registro de Atividades: Permite a Gerência de Eventos, Incidentes, Problemas e Mudanças de forma integrada e interativa entre múltiplas equipes e pessoas, permitindo o registro de atividades, documentação das soluções e do processo de diagnóstico realizado, a comunicação via chat e realização de reuniões com gravação de todas as comunicações vinculadas ao ticket que representa a solução da demanda.
Instalação e Primeiros Passos
Instalação do Agente Priax
Funções dos diferentes agentes
Os agentes do Priax são responsáveis por um conjunto diferente de funções onde cada uma delas serve a um proposito diferente. A definição de quais pacotes devem ser instalados em cada ambiente é uma definição do projeto alinhada ao licenciamento do produto.
O agente PCM é o agente responsável pelo monitoramento de configurações. Para versões de sistema operacional Linux a coleta de sockets de comunicação é feita por este agente.
O agente PIA é o responsável pela coleta de sockets de comunicação e realização do inventario local do host onde está instalado.
O agente PPA é o responsável pelo monitoramento de capacidade/performance do Priax.
Sistemas operacionais suportados por agente
|
Sistema Operacional |
PCM |
PIA |
PPA |
Versão Pacote |
|
Sistemas operacionais Linux |
||||
|
RHEL 6 |
X |
O |
X |
6 |
|
RHEL 7 |
X |
X |
X |
7 |
|
RHEL 8 |
X |
X |
X |
7 |
|
RHEL 9 |
X |
X |
X |
7 |
|
Centos 6 |
X |
O |
X |
6 |
|
Centos 7 |
X |
X |
X |
7 |
|
Centos 8 |
X |
X |
X |
7 |
|
Oracle Linux 6 |
X |
O |
X |
6 |
|
Oracle Linux 7 |
X |
X |
X |
7 |
|
Oracle Linux 8 |
X |
X |
X |
7 |
|
Ubuntu 14 |
X |
O |
X |
6 |
|
Ubuntu 16 |
X |
X |
X |
7 |
|
Ubuntu 18 |
X |
X |
X |
7 |
|
Ubuntu 20 |
X |
X |
X |
7 |
|
Ubuntu 22 |
X |
X |
X |
7 |
|
Debian 7 |
X |
O |
X |
6 |
|
Debian 8 |
X |
X |
X |
7 |
|
Debian 9 |
X |
X |
X |
7 |
|
Debian 10 |
X |
X |
X |
7 |
|
Debian 11 |
X |
X |
X |
7 |
|
Debian 12 |
X |
X |
X |
7 |
|
Amazon Linux AMI |
X |
X |
X |
7 |
|
Amazon Linux 2 |
X |
X |
X |
7 |
|
Suse 12 |
X |
X |
X |
7 |
|
Kali Linux 2019 |
X |
X |
X |
7 |
|
Kali Linux 2023 |
X |
X |
X |
7 |
|
Rocky Linux 8 |
X |
X |
X |
7 |
|
Rocky Linux 9 |
X |
X |
X |
7 |
|
Sistemas operacionais Windows |
||||
|
Windows Server 2008 |
X |
X |
X |
Nda |
|
Windows Server 2012 |
X |
X |
X |
Nda |
|
Windows Server 2016 |
X |
X |
X |
Nda |
|
Windows Server 2019 |
X |
X |
X |
Nda |
|
Windows Server 2022 |
X |
X |
X |
Nda |
|
Windows 7 |
X |
X |
X |
Nda |
|
Windows 8 |
X |
X |
X |
Nda |
|
Windows 10 |
X |
X |
X |
Nda |
|
Windows 11 |
X |
X |
X |
Nda |
-
Matriz de compatibilidade
Sistemas operacionais não incluídos na lista não tem suporte dos agentes e havendo necessidade entrar em contato com a equipe de suporte do Priax.
Arquivos de instalação
Dependendo da versão do Sistema Operacional diferentes pacotes são utilizados para diferentes instalações.
Windows
O pacote de instalação para sistemas operacionais Windows é um arquivo .msi que possui embutido no mesmo pacote todos os agentes.
Para sistemas operacionais Windows x86 não são mais suportados.
Para sistemas operacionais Windows x64 deve-se utilizar o pacote PriaxAgent.msi
Sistemas operacionais Linux
Para instalação em sistemas operacionais Linux cada versão deve fazer uso de um pacote específico para cada agente onde a instalação do agente do PPA para Linux utiliza o pacote PPAClient, o agente do PCM utiliza o pacote PCMClient e o PIA utiliza o pacote PIAgent.
Considerando a versão do pacote descrita na tabela Matriz de compatibilidade o nome do pacote a ser utilizado é determinado por ela.
EXEMPLOS:
Para instalação do agente do PPA em um Ubuntu 14 deve-se utilizar o pacote PPAClient6 da mesma forma que em um Centos 6;
Para instalação do agente do PCM em um RHEL 8 utiliza-se o pacote PCMClient7 assim como em um Debian 9.
Requisitos de instalação
Antes de iniciar a instalação é necessário garantir que o sistema operacional atenda um conjunto mínimo de requisitos para que a instalação e funcionamento dos agentes ocorra de forma esperada.
Windows
Para sistemas operacionais Windows os requisitos para funcionamento do agente são:
Possuir privilégio administrativo para a instalação do agente se realizada de forma manual;
Ao menos versão 4.6.2 do .Net Framework;
Ao menos versão 3.0 do Powershell;
Sistemas operacionais Linux
Para instalação em sistemas operacionais Linux os requisitos são:
Possuir acesso privilegiado ao host para instalação manual;
Quando instalando agentes de pacote 6 o host deve possuir ao menos a versão 1.10 da lib krb5 ou correspondente do sistema operacional;
Pacote “tar” instalado pois o pacote de instalação é compactado usando tar;
Sudo instalado.
Fluxos de comunicação dos agentes
De forma geral o agente quando instalado, precisa se comunicar com a API do servidor de gerência do agente e com o servidor de mensageria. Está comunicação é sempre partindo do agente para o servidor. Abaixo segue um exemplo de configuração possível mas vale lembrar que ela é especifica de cada ambiente.
Neste exemplo a API onde os agentes conectam esta configurada para utilizar o protocolo HTTP na porta 9090.
|
Agente |
Origem |
Destino |
Porta TCP |
|
PPA |
Agente |
Servidor |
9090 |
|
5672 |
|||
|
PCM |
Agente |
Servidor |
9090 |
|
PIA |
Agente |
Servidor |
9090 |

Para que o agente funcione, quando utilizando nomes de host é necessário que o nome seja possível de ser resolvido para IP.
Processo de instalação
Windows
Para instalação em sistemas operacionais Windows, após garantir que o host possua os requisitos, deve-se executar o arquivo MSI disponível para a versão do sistema operacional.
Instalação de forma manual
Iniciando a instalação de forma manual executando o arquivo MSI dentro do host onde se deseja instalar o agente será exibida uma janela de boas-vindas. Clicar em Next para iniciar a instalação.

-
Welcome Priax Agente Setup
O próximo passo é a seleção do local onde deseja-se instalar o agente. O padrão é C:\Program Files\Priax Agent\
Manter a seleção de instalação para todos usuários e clicar em Next para prosseguir.

-
Local de instalação
Na tela de configuração da API deve-se ter atenção para os valores cadastrados onde eles devem ser os nomes de host/endereços IP dos servidores da API. Após definir os valores clicar em Next para prosseguir.
Em Endereço deve-se definir o endereço http/https para comunicação com a API considerando a configuração do ambiente assim como a porta onde a API responde.
Em endereço do serviço de fila definir o endereço para a o servidor de mensageria considerando a configuração do ambiente.
Abaixo um EXEMPLO de configuração.

-
Priax API
Na próxima janela são selecionados quais os agentes serão instalados.
Selecionar os necessários e clicar em Next para prosseguir.
Vale lembrar que esta configuração depende de quais módulos do agente são utilizados onde a imagem abaixo é apenas um EXEMPLO.

-
Priax Agents
Será exibida uma tela informando que o agente está pronto para ser instalado, e clicando em Next a instalação será iniciada.

-
Confirmar instalação
Finalizada a instalação será exibida uma janela informando que a instalação ocorreu com sucesso.

-
Finalizada a instalação
Instalação em linha de comando
O mesmo pacote MSI possibilita também a instalação via linha de comando com o objetivo de possibilitar o uso de soluções de distribuição de software ou instalação automatizada.
Para realizar a instalação via linha de comando os seguintes parâmetros devem ser passados para a execução do MSI.
URL = endereço da API;
RMQ = endereço do servidor de mensageria;
PPA = se deve ser instalado ou não agente do PPA. Deve ser 1 caso queira instalar e 0 em caso negativo;
PIA = se deve ser instalado ou não agente do PIA. Deve ser 1 caso queira instalar e 0 em caso negativo;
PCM = se deve ser instalado ou não o agente do PCM. Deve ser 1 caso queira instalar e 0 em caso negativo;
Path do arquivo MSI.
Sintaxe da execução via linha de comando
msiexec /quiet /i pathdoarquivomsi URL="enderecoAPI" PPA=0/1 PCM=0/1 PIA=0/1 RMQ="enderecoMensageria"
Exemplo de linha de comando lendo o arquivo MSI localizado em c:\temp\PriaxAgent.msi, instalando somente o PCM utilizando endereço da API https://srvpriax.priax.io:9090 e servidor de mensageria srvpriax.priax.io:5672
msiexec /quiet /i c:\temp\PriaxAgent.msi URL="https://srvpriax.priax.io:9090" PPA=0 PCM=1 PIA=0 RMQ="srvpriax.priax.io:5672"
Sistemas operacionais Linux
Em sistemas operacionais Linux durante o processo de instalação é criado um usuário local no host onde está sendo instalado o agente sendo este o usuário que roda a aplicação.
Abaixo usuários que são criados considerando cada pacote instalado.
|
Agente |
Usuário |
|
PPA |
PriaxPPAClient |
|
PCM |
PriaxPCMClient |
|
PIA |
PriaxPIAgent |
Para instalação em sistemas operacionais Linux basta copiar o arquivo de instalação para o host, tornar ele executável e executar.
Para tornar o arquivo executável executar chmod +x nomedoarquivo
EXEMPLO: # chmod +x /tmp/PriaxAgent/PPAClient7
Quando a instalação é iniciada será exibido o processo da validação de integridade do arquivo assim como da instalação.
# /tmp/PPAClient7
Verifying archive integrity... 100% MD5 checksums are OK. All good.
Uncompressing Priax Agents Setup 100%
#
Instalação remota
Existe um processo que possibilita a instalação dos agentes em hosts de forma remota e em massa possibilitando assim uma rápida distribuição dos agentes em conjuntos de hosts.
Este processo foi criado a fim de possibilitar a instalação dos agentes do Priax em hosts que o Priax consegue gerenciar como alternativa a outras soluções de distribuição de software como o System Center, Ansible entre outros.
Este processo inicia-se no host do PPAServer, lê conjuntos de informações de acesso que já devem estar cadastradas no Priax e tenta conexão aos hosts para em primeiro lugar avaliar se é necessário ou não a instalação do agente no host e em caso positivo, valida os requisitos e instala se possível.
Fluxos de comunicação para instalação remota
Considerando os fluxos de comunicação necessários para este processo poder ser executado, eles diferem dependendo do tipo de host onde se está tentando instalar o agente, mas são os mesmos utilizados para o Discover. Em ambos os casos a comunicação inicia-se no servidor onde o processo está rodando com destino onde o agente deve ser instalado.
|
Origem |
Destino |
Protocolos/Portas utilizadas |
|
Servidor PPAServer |
Servidores/estacoes Windows |
WMI; Mais informações no link abaixo |
|
Servidor PPAServer |
Servidores Linux |
SSH; TCP 22 |
Sendo hosts Windows, a comunicação toda é feira via WMI e a descrição do funcionamento do protocolo WMI em relação a rede esta descrita no link https://learn.microsoft.com/en-us/windows/win32/wmisdk/connecting-to-wmi-on-a-remote-computer
Permissões necessárias para instalação remota
Em relação a hosts Windows, é necessário que o usuario utilizado seja ao menos membro do grupo local dos hosts Administrators ou Power Users;
Em relação a hosts Linux, o usuário não precisa ser “root” mas deve ter permissão de execução do pacote de instalação do agente de forma privilegiada.
Permissão esta pode ser concedida de diversas formas mas é importante saber que durante o processo em relação a hosts Linux não é possível interação de usuário com credenciais como acontece quando em sessão interativa (usando o putty por exemplo). Isto significa que as permissões requeridas para os processos rodarem devem ser possíveis sem que seja necessário digitar a senha novamente, de forma interativa.
Se o usuario utilizado é “root” a instalação acontece de forma direta e caso não seja, com uso do sudo.
Durante a execução do processo de instalação em host Linux, é criado no diretório /tmp o diretório PriaxAgent e os pacotes de instalação necessários copiados para este diretório. Ao final do processo eles são removidos.
Exemplo de configuração que pode ser aplicada é de ajustar a configuração do sudoers como o exemplo abaixo. Atenção ao usuario utilizado.
Cmnd_Alias PRIAXPERMISSIONSAGENTINSTALL /tmp/PriaxAgent/PPAClient6, /tmp/PriaxAgent/PCMClient6, /tmp/PriaxAgent/PPAClient7, /tmp/PriaxAgent/PCMClient7, /tmp/PriaxAgent/PIAgent7
Defaults!PRIAXPERMISSIONSAGENTINSTALL !requiretty
usuarioUtilizadoParaConexao ALL=(ALL) NOPASSWD: PRIAXPERMISSIONSAGENTINSTALL
Discovery, CMDB e Gestão de Ativos
Introdução ao discovery do Priax
O Módulo de Discovery identifica Itens de Configuração (ICs), seus atributos essenciais e suas relações com outros ICs diretamente do ambiente administrado, mantendo-os atualizados na CMDB. Ele é dividido em submódulos, licenciados separadamente, que realizam o discovery em diferentes classes de tecnologias e fontes de dados.
Funcionalidades do Discovery
Discovery de Rede e Domínios LDAP/Active Directory
Esse submódulo utiliza redes e domínios LDAP como fontes de dados para identificar hosts, seus sistemas operacionais e realizar varreduras internas, detectando itens de configuração e suas dependências. Os hosts descobertos passam a ser monitorados regularmente, e as alterações são refletidas na CMDB. Opcionalmente, servidores com tecnologias Windows e Linux podem receber agentes que aceleram o processo de discovery de mudanças, inserções e exclusões de ICs.
Discovery de Hypervisors
Compatível com Microsoft Hyper-V e VMware, este submódulo descobre componentes de clusters, armazenamento de dados, hosts virtuais, componentes de rede virtual e suas inter-relações.
Discovery Cloud
Especializado em plataformas de nuvem, descobre máquinas virtuais, bancos de dados gerenciados, sistemas de arquivos, armazenamento e outros elementos instanciáveis em Amazon AWS, Microsoft Azure e Google GCP. Também identifica relações entre elementos na nuvem e em ambientes on-premises.
Discovery Kubernetes e OpenShift
Capaz de mapear automaticamente toda a infraestrutura Kubernetes na CMDB, mantendo-a sincronizada com o ambiente real. Descobre elementos como nodes, storages, namespaces, deployments, replica sets e pods, além de suas relações de dependência.
Discovery e Inventário de Estações de Trabalho
Permite inventariar dispositivos de usuários, realizando o levantamento de hardware, software e outros itens de configuração. O processo pode ser feito sem agentes, utilizando redes e domínios Active Directory, ou com agentes para garantir o inventário mesmo de equipamentos externos, como notebooks em uso remoto.
Características Gerais dos submódulos de Discovery
Os módulos de Discovery apresentam um conjunto de funcionalidades robustas e flexíveis que facilitam a identificação, o monitoramento e a gestão dos Itens de Configuração (ICs) na CMDB. Essas características incluem:
Discovery de Itens de Configuração a partir de diferentes origens
Os módulos permitem configurar diversas fontes de dados para identificar e mapear ICs no ambiente de TI. As fontes possíveis incluem:
- Redes e credenciais associadas: Endereços de rede e suas respectivas credenciais, para varreduras que identificam dispositivos conectados, sistemas operacionais e outros atributos.
- Domínios Active Directory: Uso de credenciais LDAP para acessar informações sobre hosts e seus ICs, como sistemas operacionais, configurações de hardware e software instalado.
- Datacenters VMware: Endereços e credenciais de datacenters para descobrir clusters, máquinas virtuais, hosts e componentes relacionados.
- APIs de provedores de nuvem: Amazon AWS, Microsoft Azure e Google GCP, com credenciais para acessar configurações de máquinas virtuais, bancos de dados, sistemas de arquivos e outros serviços.
- Clusters Kubernetes: Endereços e credenciais para identificar nós, pods, namespaces e outros elementos da infraestrutura Kubernetes.
Automação e simplificação da gestão da CMDB
Os módulos incluem ferramentas que aceleram a implementação e reduzem a complexidade da manutenção, como:
- Discovery contínuo e automatizado: A CMDB é mantida atualizada automaticamente, com inserção e remoção de ICs em tempo real, de acordo com as mudanças no ambiente.
- Varredura sem agentes: A descoberta inicial pode ser realizada sem a necessidade de instalar agentes nos dispositivos, simplificando a configuração inicial.
- Compatibilidade com múltiplas assinaturas em ambientes cloud: Suporte para varreduras de múltiplos tenants e subscriptions em uma única instância, cobrindo ambientes híbridos ou complexos.
Personalização com modelos de IC adicionais
Os usuários podem criar modelos personalizados de ICs, permitindo o discovery e a gestão de itens que não são nativamente suportados pela ferramenta. Esses modelos podem ser associados a fontes de dados específicas, como APIs ou configurações customizadas.
Flexibilidade na descoberta de ICs personalizados
A ferramenta oferece mecanismos para expandir sua capacidade de descoberta, permitindo:
- Adicionar novos modelos de ICs.
- Configurar fontes de dados customizadas.
- Automatizar o mapeamento de dependências e relações para modelos personalizados.
Identificação e classificação de relações entre ICs
Os módulos detectam automaticamente as relações entre ICs e classificam essas dependências, com base em critérios como:
- Armazenamento de dados: Um IC armazena informações de outro.
- Fluxo de dados: Um IC envia ou recebe dados de outro.
- Dependência funcional: Um IC depende de outro para operar corretamente.
Descoberta automatizada de dependências
A ferramenta identifica relações intrínsecas ou funcionais entre ICs, como:
- Relações de composição: Um IC é parte integrante de outro.
- Relações de funcionamento: Um IC depende de outro para operar.
Visualização hierárquica de dependências
As dependências entre ICs e aplicações de negócios são representadas em árvores hierárquicas. Essas visualizações facilitam o entendimento das relações e oferecem painéis analíticos para análise de impacto e funcionamento.
Identificação de Single Points of Failure (SPFs)
O sistema detecta SPFs, ou seja, ICs cuja falha pode causar interrupções significativas em aplicações ou processos críticos. Essa análise é apresentada em relatórios específicos, fáceis de gerar e interpretar.
Análise de impactos de falhas
A ferramenta identifica os possíveis impactos de uma falha em um IC sobre outros ICs e aplicações relacionadas. Assim como os SPFs, essa análise é documentada em relatórios específicos, sem necessidade de procedimentos manuais.
Consideração de redundâncias entre ICs
A CMDB permite configurar clusters de ICs redundantes, detalhando:
- A quantidade mínima de ICs ativos necessários para o funcionamento do cluster.
- A lógica de redundância aplicada nos relatórios de SPFs e impactos.
- Grupos de tipos de ICs.
- Atributos específicos.
- Relações entre ICs.
Esses filtros permitem criar listagens personalizadas para análises específicas.
Painéis customizados para visualização da CMDB
A ferramenta oferece suporte à criação de painéis personalizados, permitindo que os usuários configurem visualizações adaptadas às suas necessidades de monitoramento e gestão.
Gestão de Ativos
O Priax é uma solução completa e integrada para o controle eficiente de todos os recursos tecnológicos de uma organização. Projetada para atender às necessidades das áreas de infraestrutura, suporte e governança de TI, a ferramenta centraliza as informações de hardware e software, oferecendo visibilidade, controle e rastreabilidade de ativos ao longo de seu ciclo de vida.
Gestão de Hardware
-
Inventário de Equipamentos: Registro detalhado de estações de trabalho, notebooks, celulares e outros dispositivos, com informações como modelo, fabricante, número de série, localização física e status.
-
Gestão Patrimonial: Acompanhamento do patrimônio de TI com controle de tombamento, movimentações internas, cessões e baixas.
-
Controle de Garantias: Registro e monitoramento automático de prazos de garantia de cada equipamento, com alertas para vencimentos iminentes.
-
Histórico de Manutenções e Trocas: Registro de intervenções técnicas, substituições e movimentações de equipamentos por usuário, local ou setor.
Inventário de Equipamentos (Hardware)
A funcionalidade de Inventário de Hardware da Priax oferece uma visão completa, automatizada e em tempo real de todos os ativos físicos de tecnologia da informação da organização. Por meio de mecanismos de varredura e coleta inteligente de dados, a Priax realiza um mapeamento detalhado de computadores, impressoras e outros dispositivos conectados à infraestrutura corporativa.
Coleta Automática de Informações Técnicas
A Priax realiza a coleta automatizada de informações técnicas por meio de agentes locais, protocolos padrão (como WMI, SNMP, etc.) ou integração com soluções de gerenciamento já existentes. Esse processo permite capturar e registrar com precisão os seguintes dados:
-
Identificação do Equipamento
-
Fabricante
-
Nome e modelo do equipamento
-
Número de série (Serial Number)
-
Etiqueta de patrimônio (se aplicável)
-
Tipo de dispositivo (notebook, desktop, servidor, impressora, etc.)
-
Localização física e unidade organizacional
-
-
Componentes de Hardware
-
Processador (CPU): modelo, fabricante, número de núcleos, arquitetura e velocidade de clock
-
Placa-mãe: modelo, fabricante, revisão, número de série
-
Memória RAM: capacidade total instalada, quantidade de pentes, tipo (DDR3, DDR4 etc.), slots ocupados
-
Disco Rígido / SSD: capacidade, tipo, fabricante, uso atual, número de série e status SMART (se disponível)
-
Placa de Vídeo: modelo, memória dedicada, fabricante
-
Placa de Rede: interfaces detectadas, endereços MAC, velocidades suportadas
-
Monitor(es): modelo, resolução nativa, tamanho e número de série (quando disponível)
-
-
Outros Equipamentos
-
Impressoras (locais ou em rede): modelo, fabricante, status, tipo (jato de tinta, laser), contador de páginas (via SNMP)
-
Dispositivos periféricos: teclado, mouse, dispositivos USB e outros dispositivos PNP relevantes
-
Rastreabilidade e Histórico
Cada item de hardware registrado na Priax mantém um histórico completo de alterações, incluindo:
- Troca de componentes
- Movimentações entre unidades ou usuários
- Alterações de configuração ou upgrade
- Manutenções realizadas
Gestão de Software
-
Inventário de Softwares Instalados: Detecção automática de aplicativos instalados nos dispositivos, com identificação de versão, fornecedor e frequência de uso.
-
Gestão de Licenças: Controle centralizado de contratos, chaves de ativação e número de licenças adquiridas versus utilizadas, com alertas para vencimentos ou não conformidades.
-
Controle de Uso de Software: Monitoramento da utilização de softwares críticos ou licenciados, com dados analíticos para apoiar decisões de renovação, remoção ou realocação de licenças.
Inventário de Softwares
A funcionalidade de Inventário de Softwares da Priax oferece visibilidade completa e contínua sobre todos os aplicativos instalados nos dispositivos da organização, abrangendo ambientes Windows e Linux. Por meio de uma varredura inteligente e não intrusiva, a ferramenta identifica, cataloga e mantém atualizado o repositório de softwares em uso, promovendo governança, segurança e compliance com políticas de licenciamento.
Descoberta e Coleta de Informações
A Priax realiza a coleta de dados por meio de agentes locais ou acesso remoto via protocolos nativos do sistema operacional, como:
-
Windows Management Instrumentation (WMI)
-
Linux package managers (APT, RPM, DPKG, YUM, Zypper, etc.)
-
Scripts personalizados e comandos shell
Essa abordagem permite identificar:
-
Nome do software/aplicativo
-
Versão instalada
-
Fornecedor / fabricante
-
Data de instalação
-
Caminho de instalação
-
Chave de licença (quando disponível)
-
Tipo de instalação (usuário ou sistema)
-
Frequência e data do último uso (opcional)
Catálogo e Normalização de Aplicações
Os dados coletados são organizados automaticamente em um catálogo de softwares com normalização de nomes e versões, evitando duplicidades e inconsistências. Isso facilita a visualização em relatórios e a análise gerencial, além de permitir a categorização por tipo de aplicação, finalidade, criticidade ou compliance.
Controle e Medição de Uso de Software
A funcionalidade de Medição de Uso de Software da Priax vai além do inventário tradicional, oferecendo um monitoramento preciso e detalhado da utilização real dos softwares instalados em cada estação de trabalho ou servidor. Essa capacidade permite à organização identificar padrões de uso, justificar investimentos, otimizar licenciamento e promover a governança eficaz de seu parque de aplicações.
Coleta Inteligente de Dados de Uso
Por meio de agentes leves instalados em dispositivos Windows e Linux, a Priax monitora de forma contínua os seguintes parâmetros:
-
Execução de Aplicativos: Detecção de quando um determinado software é iniciado e encerrado.
-
Duração de Uso Ativo: Tempo total em que o software permaneceu em execução, considerando apenas períodos em que o usuário estava ativo (interações reais com o sistema).
-
Usuário e Estação Associada: Identificação precisa do usuário logado e da máquina em que o software foi utilizado.
-
Contagem de Sessões: Número de vezes que o software foi executado em um determinado período.
-
Registro em Tempo Real: Dados podem ser enviados em tempo real para o servidor central ou armazenados localmente para sincronização posterior, ideal para ambientes com rede instável ou dispositivos móveis.
Exemplos de Métricas Capturadas
| Software | Usuário | Estação | Execuções (mês) | Duração Total (hh:mm) |
|---|---|---|---|---|
| Microsoft Excel | j.silva | WS-019 | 24 | 12:35 |
| AutoCAD | a.rocha | NB-042 | 3 | 4:20 |
| Adobe Photoshop | m.almeida | NB-113 | 0 | 0:00 |
Análises e Aplicações Práticas
A Priax utiliza os dados de uso para gerar insights estratégicos e operacionais, tais como:
-
Identificação de Softwares Subutilizados: Aplicativos com baixíssima ou nenhuma frequência de uso, candidatos à remoção ou redistribuição de licenças.
-
Justificativa de Investimentos: Base objetiva para renovação, expansão ou encerramento de contratos de software.
-
Compliance e Governança: Evidência concreta de conformidade ou violação de políticas de uso de software.
-
Planejamento de Treinamentos: Identificação de usuários que pouco utilizam ferramentas essenciais para suas funções, indicando possíveis lacunas de capacitação.
-
Mapeamento de Cargas de Trabalho: Apoio na redistribuição de licenças flutuantes e de alto custo, como softwares de engenharia ou design.
Relatórios e Dashboards
A Priax apresenta os dados de uso em dashboards interativos e relatórios que podem ser filtrados por:
-
Usuário, estação, grupo ou departamento
-
Nome do software ou categoria
-
Período (diário, semanal, mensal, customizado)
-
Faixas de tempo de uso (ex.: >20h/mês, entre 1-5h, etc.)
Os relatórios podem ser exportados em PDF, Excel ou enviados automaticamente por e-mail para áreas como TI, Compras, Auditoria ou Gestão de Riscos.
Gestão de Licenciamento
A Priax oferece uma robusta funcionalidade de Gestão de Licenças, permitindo à organização manter total controle sobre os contratos de software adquiridos, sua vigência, utilização real e conformidade com os limites de uso. Combinando dados do inventário de software e do monitoramento de uso, a solução proporciona uma gestão preventiva, inteligente e auditável do licenciamento.
Registro Centralizado de Licenças
A Priax permite o cadastro completo das licenças adquiridas para cada software, com os seguintes campos:
-
Nome do software e versão
-
Tipo de licença (perpétua, por assinatura, por usuário, por dispositivo, flutuante, etc.)
-
Quantidade de licenças adquiridas
-
Número(s) de série ou chave(s) de ativação
-
Fornecedor ou fabricante
-
Data de aquisição
-
Data de expiração ou renovação (se aplicável)
-
Unidade, centro de custo ou projeto vinculado
Vinculação com Dispositivos e Usuários
Cada licença registrada pode ser vinculada de forma automática ou manual aos computadores e/ou usuários onde o software correspondente está instalado e/ou em uso. A Priax mantém um mapeamento preciso de:
-
Quais estações estão utilizando cada licença
-
Quem são os usuários atribuídos
-
Quando cada licença foi ativada ou instalada
Controle de Utilização de Licenças
A ferramenta realiza a conciliação contínua entre o número de licenças adquiridas e o número de instalações ou execuções registradas no ambiente. Isso permite:
-
Contabilizar licenças em uso: Com base no inventário e no uso ativo do software
-
Detectar licenças ociosas: Equipamentos com softwares instalados que não foram utilizados recentemente
-
Gerenciar excedentes: Alertas automáticos sempre que o número de instalações ultrapassar a quantidade licenciada
Alertas e Notificações
A Priax gera alertas configuráveis em diversos cenários críticos:
-
Excesso de uso: Mais softwares em uso do que o permitido pela licença
-
Vencimento de licenças: Avisos antecipados por e-mail ou dashboard para licenças próximas à expiração
-
Risco de não conformidade: Sinalização de softwares instalados sem vínculo com uma licença válida
-
Distribuição ineficiente: Licenças atribuídas a máquinas ou usuários sem uso efetivo
Relatórios e Auditoria
A solução oferece relatórios completos sobre:
-
Licenças por software (adquiridas, utilizadas, ociosas)
-
Histórico de alocação e utilização
-
Conformidade por unidade ou departamento
-
Projeções de renovação e necessidades futuras
-
Alertas e desvios detectados
Esses relatórios podem ser exportados, agendados e integrados a ferramentas externas, como sistemas ERP, ITSM ou plataformas de auditoria.
Discovery de Mapas de Aplicações
O Priax Application Mapping
O Priax Application Mapping tem em sua base o conceito de rastreamento distribuído (Distributed Tracing) que é usado por diversas ferramentas de Application Performance Monitoring (APM) para solucionar o problema de entender o fluxo de execução de uma solicitação em sistemas distribuídos, nos quais uma única solicitação é processada por vários componentes ou serviços.
A ideia central do rastreamento distribuído é que uma solicitação pode ser dividida em várias operações menores, conceitualmente chamadas de "spans", que representam unidades de trabalho individuais dentro de um sistema distribuído. Cada span registra informações sobre a operação, como seu início, duração, identificador exclusivo e quaisquer metadados relevantes. Os spans são conectados em uma árvore hierárquica, na qual o span raiz representa a solicitação inicial e os spans filhos representam operações dependentes ou subprocessos.
Essa estrutura hierárquica de spans permite visualizar o fluxo de execução completo de uma solicitação, identificar gargalos de desempenho, analisar o tempo gasto em cada operação e depurar problemas em sistemas distribuídos complexos. Além disso, cada span pode conter anotações adicionais, como logs e tags, que fornecem informações contextuais para facilitar a compreensão do comportamento do sistema.
A teoria relacionada às spans no rastreamento distribuído é fortemente influenciada por conceitos de observabilidade, como causalidade, transparência e correlação de eventos. Ao coletar e correlacionar spans de diferentes componentes, é possível reconstruir a trajetória completa de uma solicitação e obter insights valiosos sobre o desempenho e a eficiência do sistema distribuído. O rastreamento distribuído e o uso de spans tornaram-se fundamentais para a observabilidade e o monitoramento de sistemas distribuídos modernos, permitindo aos desenvolvedores e operadores uma compreensão mais profunda do comportamento e do desempenho de suas aplicações.
Com base nessas tecnologias, o Application Mapping, que é um módulo do Priax, visa o mapeamento automático de dependências de Aplicações, correlacionando os Itens de Configuração da CMDB em função do uso que as Aplicações, ao longo de seus funcionamentos, fazem desses recursos. Para tal, o Application Mapping analisa as spans geradas pela aplicação, buscando informações sobre o uso ou consumo de recursos externos à aplicação (Itens de Configuração), para gerar o correlacionamento de dependência. Desta forma o Priax é capaz de identificar, entre outros tipos de Itens de Configuração os seguintes tipos de recursos:
- Bases (schemas ou databases) de dados em Bancos de Dados Relacionais;
- Bancos de dados não-relacionais;
- WebServices e outras aplicações web consultadas;
- Sockets de rede consultados;
- Processos (executáveis em execução) locais e remotos com os quais a aplicação troca informação;
- Tópicos ou filas de serviços de mensagens ou fluxo de dados como Kafka e RabbitMQ.
O resultado dessas análises são mapas de dependências, que correlacionam os Itens de Configuração diretamente e indiretamente consumidos pelas transações executadas pela Aplicação, formando uma árvore de dependências que explica exatamente o que cada aplicação precisa para funcionar, podendo ser usadas posteriormente para simulações de impactos e de dependências, na análise em tempo real de impactos no caso de uma falha de algum IC ou para o planejamento de continuidade de negócios e recuperação de desastres. Abaixo um exemplo de mapa gerado pelo Application Mapping.
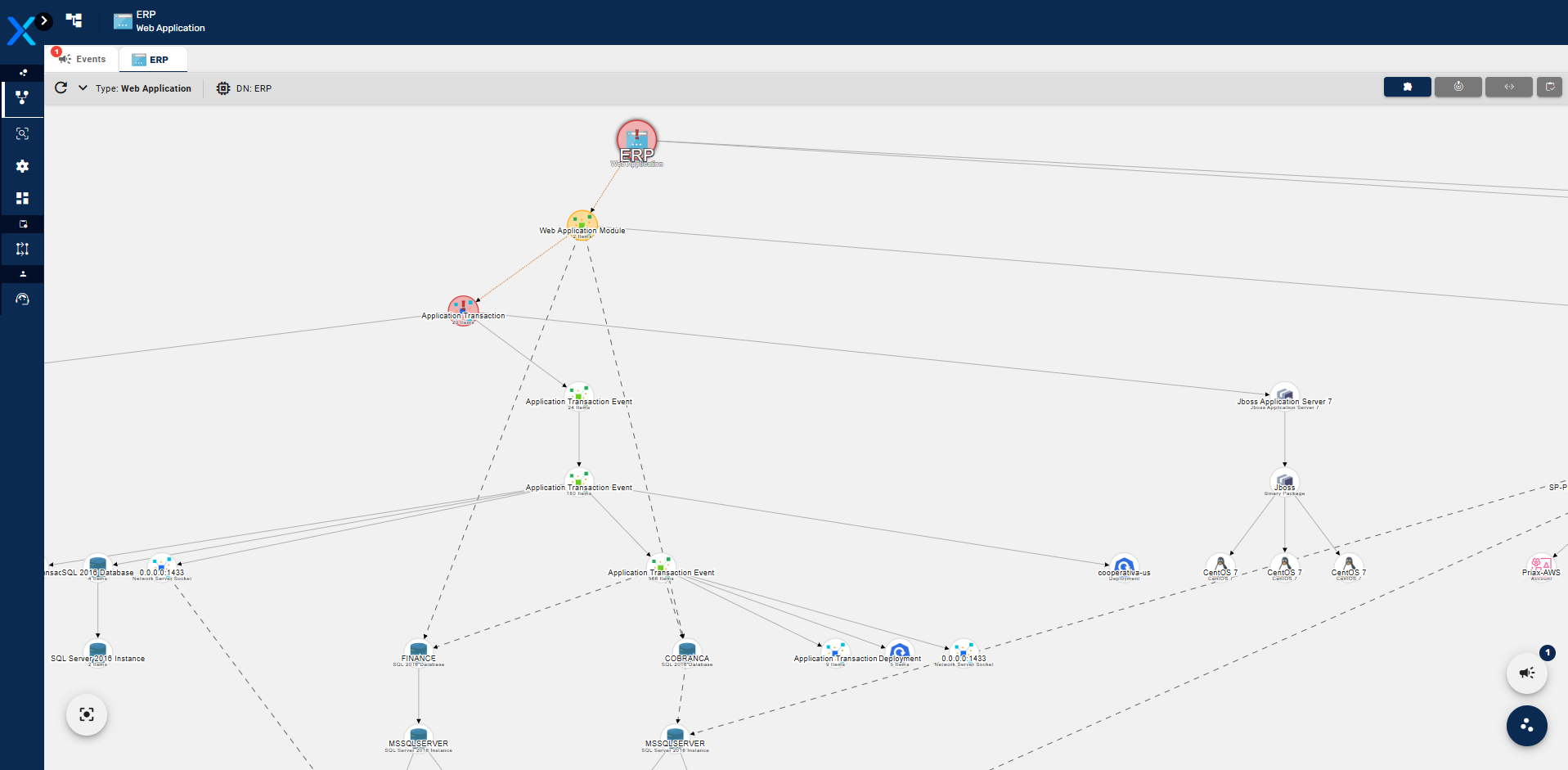
O Application Mapping realiza também a remoção de vínculos de dependência que não mais estão presentes na aplicação, removendo as dependências que não mais se apresentaram por tempo determinado e configurável.
Funcionamento do Application Mapping
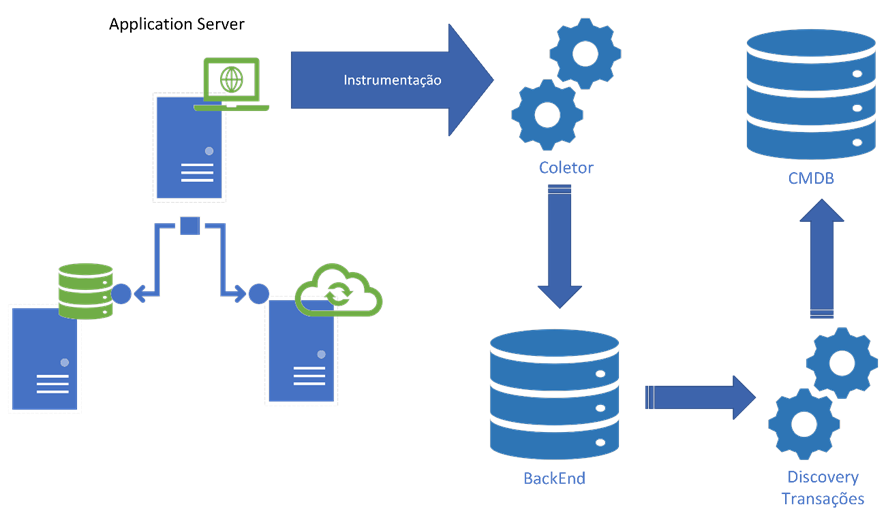
O Priax se beneficia-se do Rastreamento Distribuído de aplicações para realizar o mapeamento de Aplicações, tendo como base as spans que podem ser capturadas de diversas formas utilizando quatro componentes básicos:
- Instrumentação: A instrumentação é o ato de adicionar bibliotecas de telemetria ao código-fonte ou em camadas inferiores de sua infraestrutura (servidores de aplicação, proxies máquinas virtuais Java, etc.). Essas bibliotecas são projetadas para diferentes linguagens de programação e fornecem APIs para instrumentar pontos específicos do seu código. Por exemplo, você pode instrumentar chamadas de função, solicitações HTTP ou consultas de banco de dados. A instrumentação gera dados de telemetria, como spans (para rastreamento) e métricas. Para instrumentar uma aplicação podemos fazer uso de bibliotecas prontas ou alterar o código fonte das aplicações para realizar uma instrumentação própria.
- Coletores: Os coletores são responsáveis por coletar os dados de telemetria gerados pela instrumentação. Existem coletores específicos para diferentes tipos de dados, como rastreamento, métricas e logs. Os coletores podem ser executados como agentes no mesmo host da sua aplicação ou podem ser configurados como serviços independentes.
- BackEnds: Os dados coletados pelos coletores são enviados para backends de armazenamento, onde podem ser processados e analisados posteriormente. Os backends podem ser serviços de terceiros, como provedores de nuvem ou sistemas de armazenamento de dados internos. Eles oferecem recursos para consultar, visualizar e analisar os dados de telemetria, fornecendo insights sobre o desempenho e o comportamento do seu aplicativo. Os dados fornecidos nessa camada são utilizados para descobrir as relações entre as Aplicações e os itens de configuração presentes na CMDB Priax.
- Discovery de Transações: O sistema de Discovery de transações é um componente do Priax que consulta e analisa os dados das spans presentes nos BackEnds utilizando inteligência artificial e análise de dados, relaciona os Itens de Configuração na CMDB, criando as transações das aplicações na CMDB como Itens de Configuração que interligam os ICs.
No desenho abaixo pode-se observar como estes componentes se relacionam.
O Priax é compatível com os seguintes mecanismos de Instrumentação:

Devido aos melhores resultados obtidos, é recomendado a pilha OpenTelemetry, visto que a quantidade de informações coletadas é mais abundante e devido à melhor anonimização dos dados obtidas por essas bibliotecas de instrumentação.
Na camada de Instrumentação o Priax também é compatível com instrumentações proprietárias, desde que utilizem Coletores e BackEnds compatíveis. Desta forma é possível instrumentar uma aplicação para funcionar com o Priax sem depender diretamente de bibliotecas de terceiros em seu código-fonte. As tecnologias compatíveis com o Priax possuem especificações e API aberta que permitem implementações personalizadas para integrar a telemetria em sua aplicação.
Aqui estão algumas abordagens que você pode seguir para instrumentar sua aplicação sem utilizar bibliotecas de terceiros:
- Implementação manual: Você pode criar sua própria implementação personalizada das APIs do OpenTelemetry em seu código-fonte. Isso envolve a criação de classes, métodos e estruturas de dados necessários para capturar e enviar os dados de telemetria, como spans, métricas e logs. No entanto, essa abordagem requer um esforço significativo de desenvolvimento e manutenção, pois você precisará lidar com aspectos como a geração de IDs de rastreamento exclusivos, a propagação do contexto de rastreamento e a integração com os coletores compatíveis.
- Adaptação de código-fonte aberto: Se você preferir não desenvolver uma implementação personalizada do zero, pode considerar adaptar e modificar um código-fonte aberto existente que seja compatível com o Priax. Existem várias implementações de referência e bibliotecas de código aberto que você pode usar como base e personalizar de acordo com as necessidades da sua aplicação. Recomendamos neste caso as bibliotecas OpenTelemetry.
- Integração proxies: Uma alternativa é utilizar proxies que atuam como intermediários entre sua aplicação e os coletores. Esses agentes podem interceptar as chamadas da sua aplicação, gerar spans automaticamente e enviá-los para os coletores. Essa abordagem pode ser útil se você deseja evitar a modificação direta do código-fonte da sua aplicação.
Independentemente da abordagem escolhida, é importante garantir que você esteja seguindo as especificações compatíveis com uma das pilhas compatíveis com o Priax e fornecendo as informações de telemetria necessárias, como spans, metadados e contexto de rastreamento, para obter uma visão completa do comportamento e desempenho da sua aplicação distribuída.
Aplicações, Serviços e Transações
O Priax Application Mapping, através do discovery de transações cria no Priax as transações das aplicações. As transações são os Itens de Configuração que representam as spans encontradas no BackEnd que apresentam funcionamento similar. Cada diferente perfil de spans gera diferentes transações no Priax. Consultas em bancos de dados com mesmo endereço de servidor, database e query e consultas à webservices com mesmo endereço e estrutura são exemplos de perfis de spans que são transformados em transações na CMDB Priax pelo Discovery de Transações. Uma transação representa centenas e milhares de repetições de execução do mesmo trecho de código fonte dentro da aplicação.
Além de detectar as diferentes transações nos BackEnds, o discovery de transações detecta quais os Itens de Configuração que foram utilizados na execução de cada transação. Desta forma se uma transação consumir uma base de dados, um tópico de um sistema Kafka, uma fila de um sistema RabbitMQ, um socket de rede com um serviço específico ou ainda um webservice, estes componentes serão relacionados com as transações.
Abaixo um exemplo de transações detectada em um cluster Kubernetes.
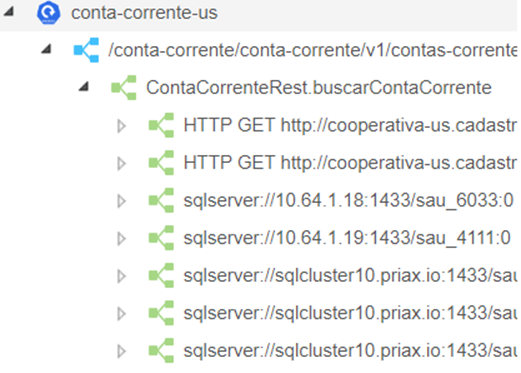
No topo do desenho, é representado um Deployment do Kubernetes, o qual foi instrumentado. Os elementos abaixo representam hierarquicamente as transações executadas nestes containers. Cada uma das transações consomem ICs que estão na CMDB, portanto cada transação é relacionada com tais ICs, como pode-se ver no exemplo abaixo para uma transação de consulta a um webservice, hospedado por outro container instrumentado.
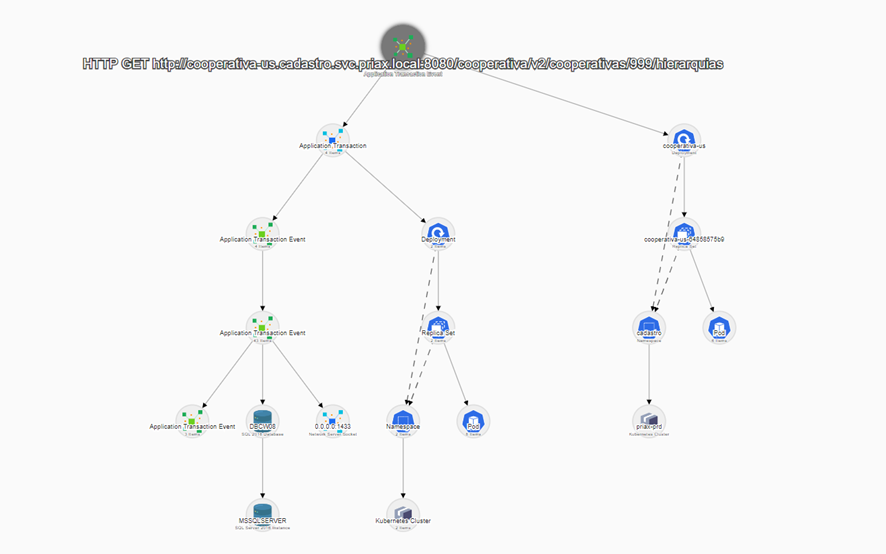
Como a transação consome um Deployment também instrumentado, veja que este Deployment também irá apresentar suas transações e dependências, chegando em uma base de dados MS SQL e nas suas respectivas dependências. A sucessão desta lógica, cria o mapa completo de dependência da aplicação.
Exibição de Dados e Navegação na CMDB
ICs e seus filhos
Após descobrir os Itens de Configurações (ICs) e suas relações, o Priax os cadastra em sua CMDB interna e fornece recursos de navegação para que você compreenda as descobertas, entenda a composição de cada tecnologia e também a cadeia de dependência e impacto entre esses ICs. Quando monitorados o Priax ainda fornece a capacidade de exibir os indicadores e suas coletas realizadas ao longo do tempo, exibindo gráficos do tipo Time Series para que se consiga compreender o funcionamento ativo desses elementos.
Ao autenticar, na página principal do Priax, é exibida a no painel da esquerda a árvore de ICs. A árvore de ICs, em sua raiz apresenta as famílias de ICs que é o primeiro nível de classificação. No segundo nível temos as categorias de ICs, essas subdivisões existem para organizar logicamente os ICs e facilitar a navegação na CMDB.
Na imagem acima, estão expandidas duas das principais famílias de ICs: Cloud Resources e On-Premises Resources. Nessas duas famílias vamos encontrar os principais tipos de ICs que estão relacionados à Infraestrutura de TI. Dentro dessas categorias temos por exemplo os Dispositivos presentes nos datacenters, os hosts e além de recursos independentes armazenados em cloud.
Expandindo a categoria Servers por exemplo, vamos encontrar os servidores do ambiente on-premises. Neste terceiro nível começamos a encontrar os Itens de Configuração Raiz, que são aqueles que não possuem um pai. Essa relação pai e filho é crada entre dois ICs que compõe um ao outro. Um IC pai é composto de seus filhos. Essa relação de composição presume que um filho possui apenas um pai.

Na imagem acima pode ser visto um servidor chamado srvdb07, composto de discos C:, E:, N:, V:, de uma interface de rede chamada Ethernet e também de uma árvore de processos. Esse host representa a estrutura básica de relacionamento entre ICs no Priax. Cada IC em nível inferior na árvore compõe o seu pai no nível imediatamente acima.
Detalhes dos ICs
Ao clicar em um IC, no painel da direita são exibidas suas informações detalhadas.
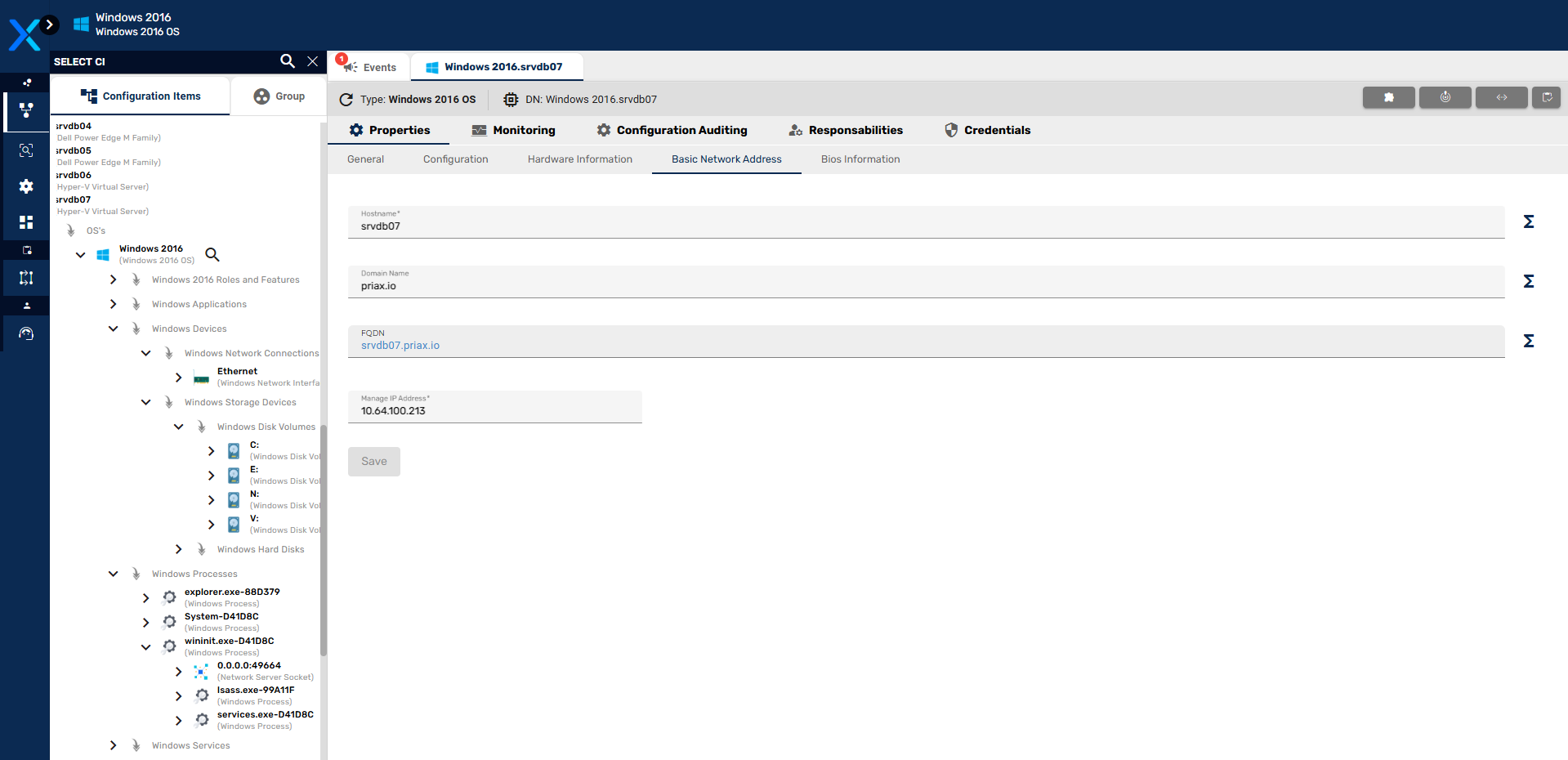
Conforme destacado na tela acima, as áreas principais nessa exibição são:
- Árvore de ICs: Árvore de composição do IC selecionado.
- Atributos do IC selecionado, cada aba representa uma classe de atributos. Cada classe de IC possui uma gama específica de atributos de acordo com sua natureza.
- Indicadores do IC: Dados históricos de cada indicador relacionado ao IC.
- Botões que levam às árvores de Impacto e Dependência de cada IC.
Impactos e Dependências de um IC
Ao clicar no botão Impact Analisys:

É exibida a árvore de impactos do IC, sendo que são utilizados as relações diretas e indiretas do IC para exibir quais ICs seriam afetados no caso do IC selecionado sofrer com algum tipo de mal-funcionamento.
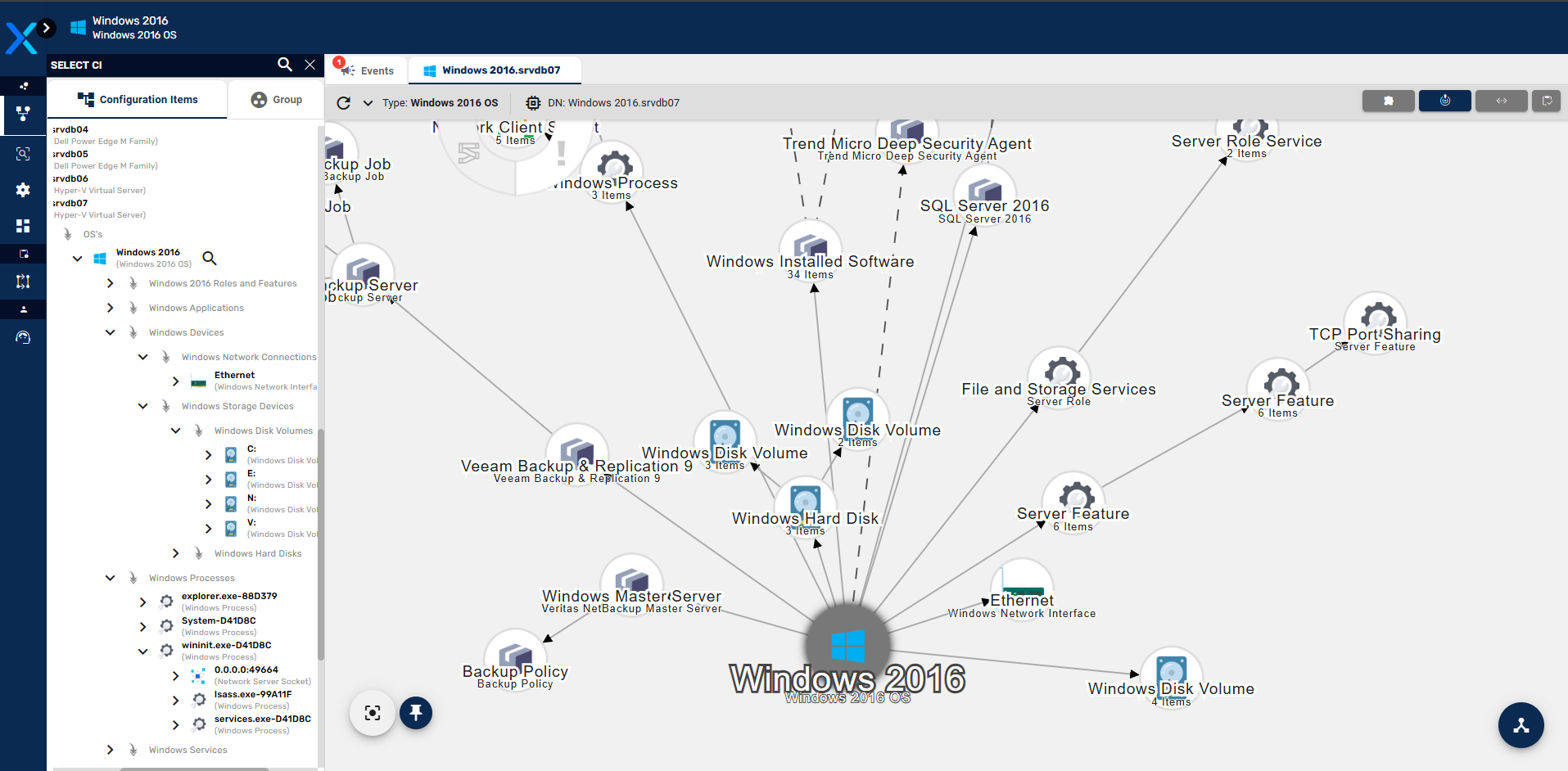
Da mesma forma, ao clicar no botão Dependency Analisys:

É exibida a árvore de dependências do IC.
Importante perceber que as árvores de impacto e dependência representam mais do que as relações de composição de um IC. Um website, por exemplo, que depende de um banco de dados, apesentará essa dependência na árvore de dependências porém um website apenas depende de um banco da dados mas não o compõe. Essas relações são descobertas como parte do processo de discovery ou com o Priax Application Mapping através da interpretação dos dados de traces e transações.
Dependências de uma Aplicação
Para o Priax, uma Aplicação é representado como um tipo de Item de Configuraçao. Assim sendo, quando precisamos saber do que depende uma aplicação, basta navegar na árvore de ICs até onde as aplicações são armazenadas e realizar o procedimento acima para ver a árvore completa de dependências da Aplicação específica desejada.
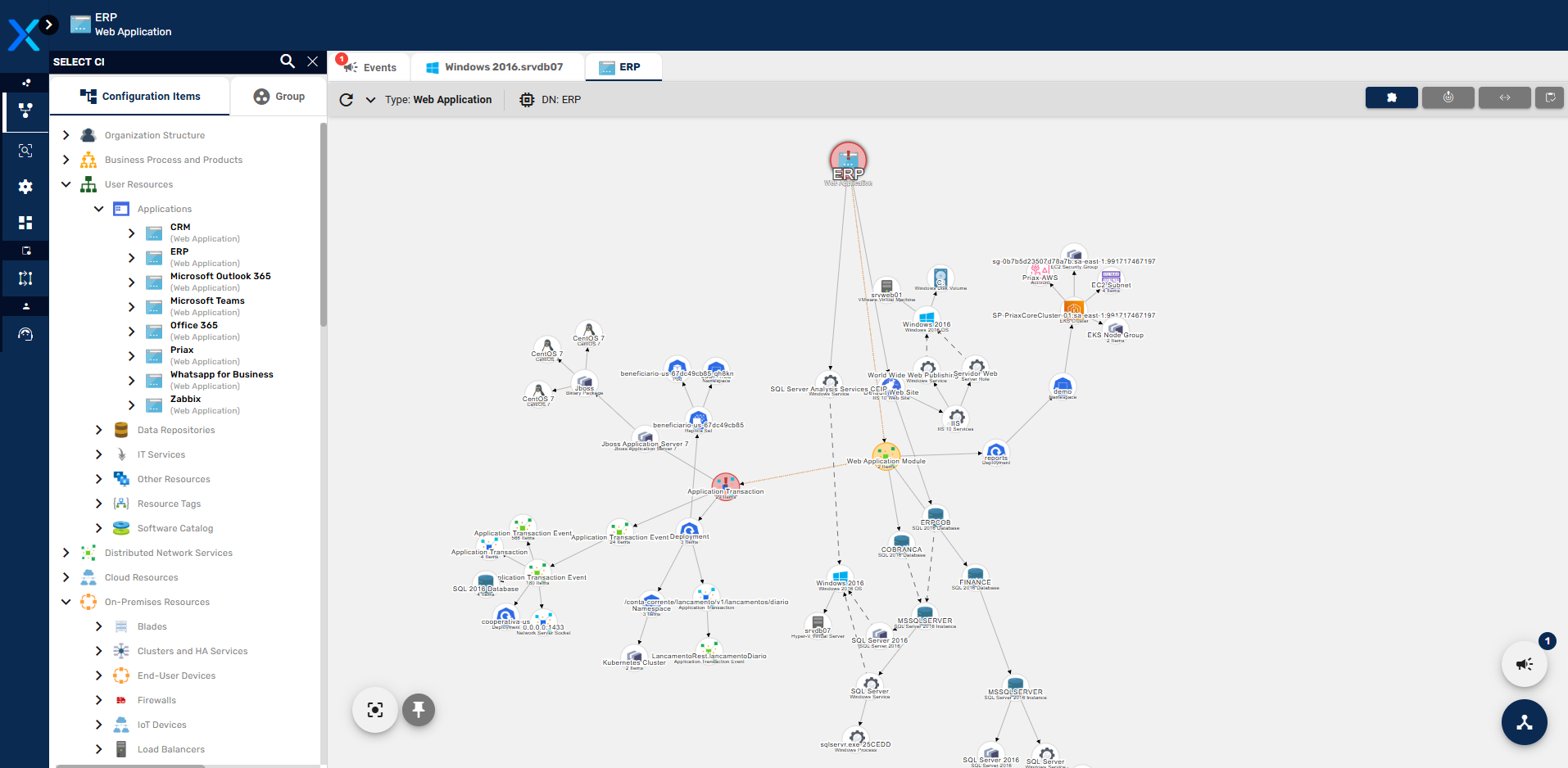
Na imagem acima, podemos ver as dependências de ima aplicação chamada ERP. Veja que a aplicação ERP está armazenada na árvore de ICs em User Resources\Applications\.
É importante entende que as relações entre a Aplicação e os componentes dos quais elas dependem são automaticamente criadas pelo componente Priax Application Mapping, que é um módulo especial de Discovery. Para entender mais sobre esse módulo veja o capítulo deste manual dedicado à esse módulo.
Análise de Indicadores em uma árvore de Dependências
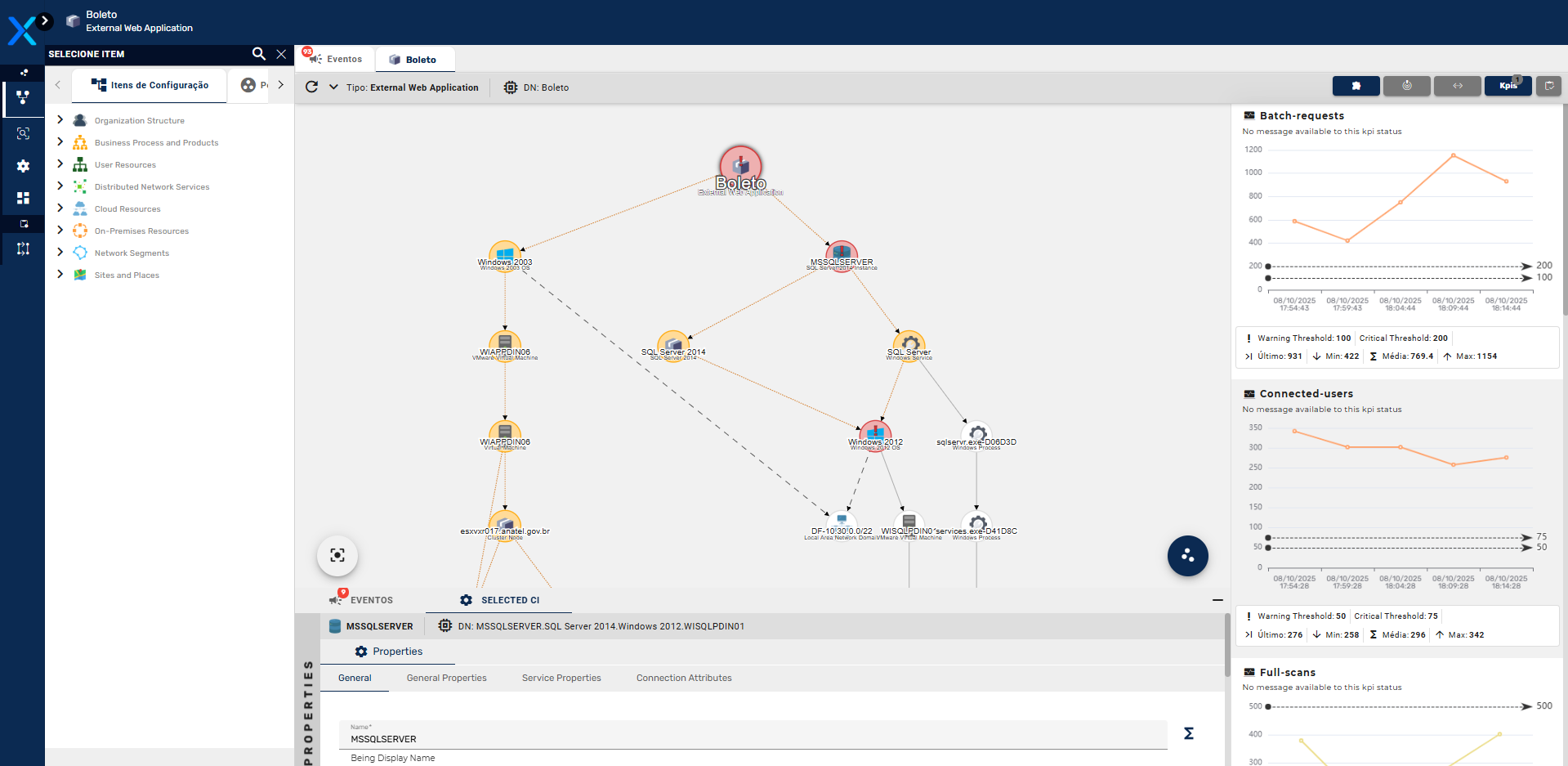
Ao clicar em qualquer componente da árvore de dependências seus indicadores são exibidos no lado direito da tela. Sempre que um IC apresentar um indicador que esteja fora da normalidade, pintará o IC na tela de amarelo, laranja ou vermelho de acordo com a gravidade da anormalidade.
Todos os indicadores podem ser analisados de forma detalhada, customizando o período de tempo e o tipo de visualização desejado. Para isso, use o botão de expansão dentro do gráfico do indicador. Abaixo exemplo de Gráfico de linha exibido para 6 meses par ao indicador de tempo médio de execução de ima transação em 5 minutos.
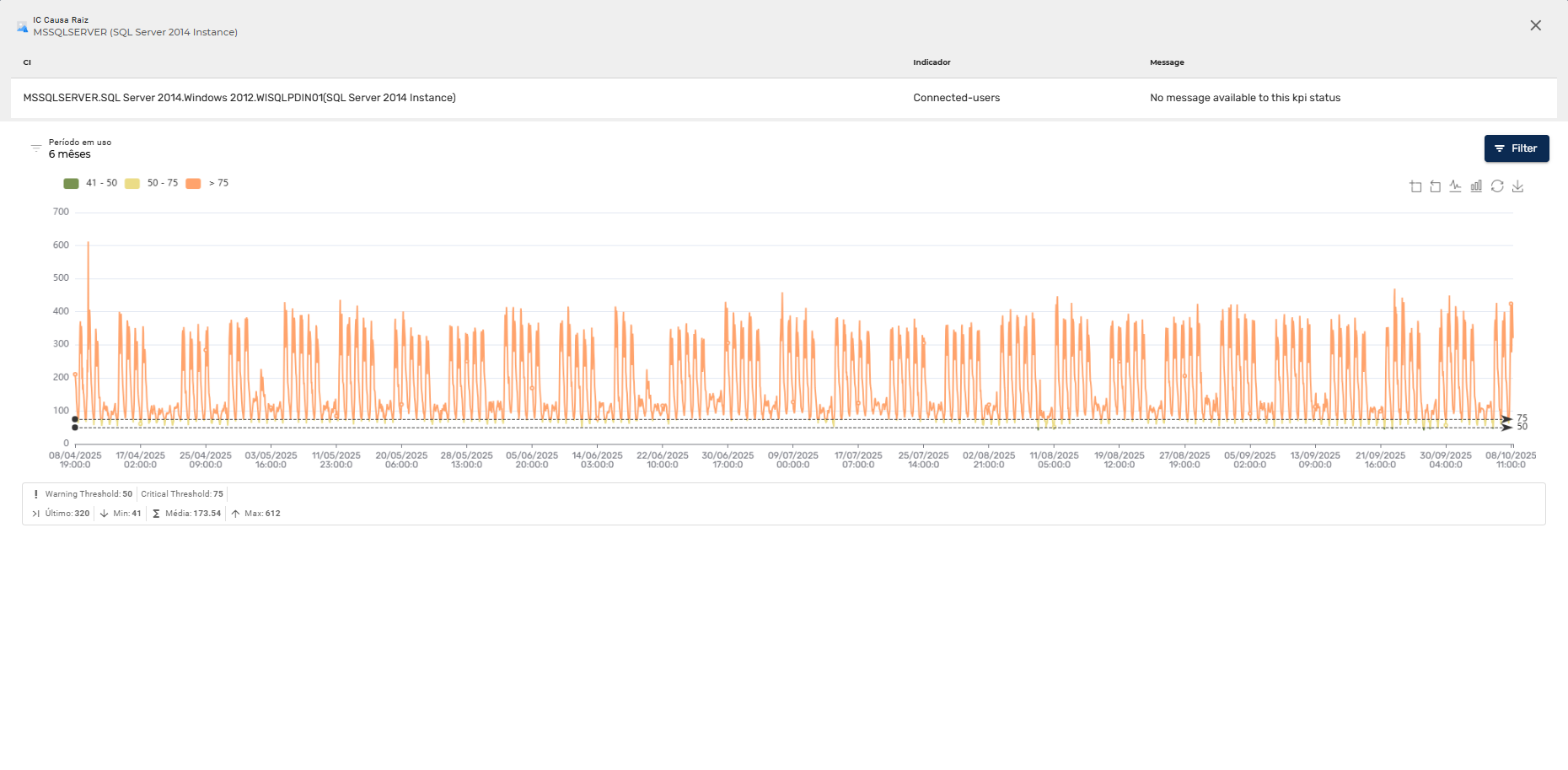
E abaixo o mesmo indicador exibido em gráfico de barras para um período curto de algumas horas.
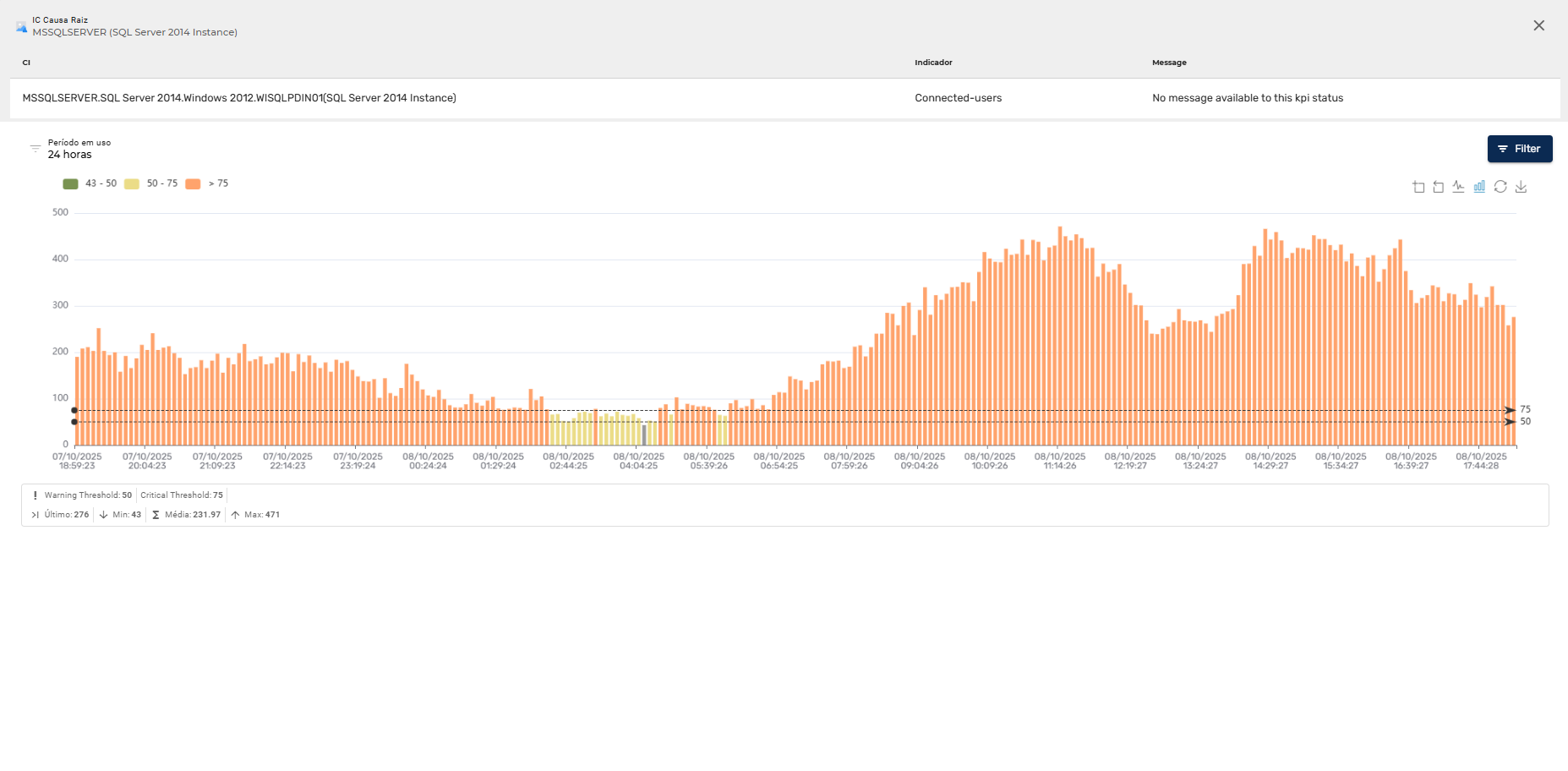
Tipos de IC Nativos e Templates
O Priax permite a detecção de Itens de Configuração customizados de forma muito flexíve. Tipos de Itens de Configuração customizados podem ser criados e scripts de reconhecimento podem ser utilizados para detectar esses novos tipos de IC. Esse nível de customização praticamente torna possível que o Priax detecte todo o tipo de IC da infraestrutura e a partir e de diversos executores com diferentes tecnologias base. No entanto, nativamente são detectados mais de oito mil tipos de ICs.
Segue uma lista de alguns dos principais Itens de Configuração detectados pelo Priax, lembrando que a lista completa possui mais de 8 mil tipos de itens de configuração:
- Sistemas Operacionais Microsoft Windows Server (Todos com suporte ativo)
- Indicadores do Sistema Operacional
- Memória e Paginação
- CPU física e Virtual
- Discos Físicos do Sistema Operacional
- Discos lógicos do Sistema Operacional
- Interfaces de rede
- Atividade por protocolo de camada 2 e 3
- Erros
- Tráfego in e out
- Socket de Rede
- Atividade TCP e UDP (Camada 4 de rede)
- Serviços do Sistema Operacional
- Processos do Sistema Operacional
- Programas Instalados no Sistema Operacional
- Todas as funcionalidades nativas (Roles) do sistema operacional
- Indicadores do Sistema Operacional
- Sistemas Operacionais Linux (Distros: Oracle Linux, RedHat, Debian, Suse, Ubuntu, entre outras)
- Indicadores do Sistema Operacional
- Memória e Paginação
- CPU física e Virtual
- Discos Físicos do Sistema Operacional
- Discos lógicos do Sistema Operacional
- Interfaces de rede
- Atividade por protocolo de camada 2 e 3
- Erros
- Tráfego in e out
- Socket de Rede
- Atividade TCP e UDP (Camada 4 de rede)
- Serviços do Sistema Operacional
- Processos do Sistema Operacional
- Programas Instalados no Sistema Operacional
- Pacotes de Software nativas do Sistema Operacional (DEB, RPM)
- Indicadores do Sistema Operacional
- Hypervisors, seus cluters, Sites, Máquinas Virtuais, Storages
- VMWare
- Hyper-V
- Xen Server
- Tecnologia VmWare (SNMP e API)
- Datacenters
- Clusters
- Servidores Físicos
- Máquinas Virtuais
- Storages
- Networks e Port Groups
- Bancos de Dados (Postgre SQL MySQL, Microsoft SQL Server, Oracle DB, Oracle RAC, Mongo DB, IBM DB2, Cassandra)
- Instância do Banco de Dados
- Database
- Tabelas
- Campos de Tabelas
- Instâncias de Servidores de Aplicação, seus deployments, websites, aplicações ou equivalente
- Microsoft IIS
- NGINX
- Apache
- Tomcat
- Wildfly
- JBoss
- Oracle WebLogic
- Serviços de Mensagens e Filas
- Kafka
- RabbitMQ
- JMS
- MQ
- Outros dispositivos
- Servidores Físicos (Dell, HP, IBM, HUAWEI, CISCO, etc.)
- Componentes de Hardware
- Discos lógicos e físicos
- Interface de Rede
- Periféricos
- Interfaces de Gerenciamento
- Switches (Cisco, Dell, 3Com, Extreme, EdgeCore, HPE, etc.)
- Interfaces (portas)]
- Roteadores
- Interfaces do Roteador
- Equipamentos relacionados à Segurança da Informação:
- Soluções de Antivírus
- Soluções de AntiSpam
- Soluções de Unified Threat Management
- Soluções Network Access Control
- Equipamentos de Firewall
- Storages (EMC, HP, DELL, HUAWEI, ETC)
- Discos Físicos
- Grupos de Disco
- Discos Lógicos
- Servidores Físicos (Dell, HP, IBM, HUAWEI, CISCO, etc.)
- Rede
- Monitoramento de tráfego, consumo e latência de Rede de forma passiva e ativa, utilizando técnicas que independem de fabricantes ou utilizando protocolos proprietários e Open Source.
- Soluções de Backups e Rotinas de Backups
- Containers
- Docker
- Kubernetes e OpenShift
- Namespaces
- Deployments
- Replicasets
- Statefulsets
- Daemonsets
- Pods
- Services
- Ingress
- PV
- PVC
- Cloud Computing
- Discovery AWS
- Discovery Azure
- Discovery GPC
- OpenStack (Serviços cloud que utilizam tecnologia OpenStack)
- OCI - Oracle Cloud Interprise
- IBM Cloud
Observabilidade de Capacidade e Disponibilidade da Infraestrutura de TI
Introdução à Observabilidade de Infraestrutura de TI
Conceitos da Observabilidade de Infraestrutura com Priax
O Priax é projetado para fornecer visibilidade e insights sobre o desempenho, a saúde e a integridade dos sistemas e da Infraestrutura de TI. O Priax realiza estas tarefas sobre os elementos cadastrados na CMDB de maneira manual ou automaticamente pelo Discovery, criando vantagens para diversos processos ligados à gestão do ambiente. A respeito do Monitoramento de Disponibilidade e Capacidade são características essenciais do Priax:
Coleta de Dados Abrangente
- Suporte a Múltiplas Fontes: Coleta informações sobre indicadores com agentes próprios porém é capaz de coletar métricas, logs e traces de servidores, containers, aplicações, redes e dispositivos de diversas fontes de dados, incluindo ferramentas de observabilidade de terceiros, inserindo ao processo de gestão de eventos a capacidade de correlação de eventos, análise de causa-raiz, análise de impactos e dependências dentro de um processo de gestão de eventos integrado.
- Integração com Serviços de Nuvem: Capacidade de coletar indicadores sobre recursos nativos de provedores como AWS, Azure, GCP, entre outros.
- Apoio a Protocolos Padrão: Compatibilidade com formatos e protocolos como SNMP, OTLP, WMI, etc.
- Armazenamento de Históricos: O Priax pode armazenar dados históricos em diversos tipos de backends de armazenamento, de acordo com a preferência do usuário (Mysql, InfluxDB, OpenSearch) e suas necessidades de integração com ferramentas de terceiros.
Capacidade de Correlação
- Identificação de Causa-raiz em tempo real: O Priax, através de técnicas de IA, Machine Learning e analise de dados a respeito das relações entre ICs e mapas de aplicação realiza em tempo real, durante a detecção de eventos a análise de causa-raiz com o intuito de agrupar eventos que representam o mesma causa, resultando em um monitoramento mais assertivo, limpo e com agregação de informações de causa-efeito o que reduz o tempo de solução.
- Integração de Logs, Métricas e Traces: Combinação de diferentes tipos de dados para identificar rapidamente a causa raiz de problemas.
- Análise de Dependências: Mapeamento das dependências entre os serviços para entender como problemas em um sistema afetam os outros.
Escalabilidade
- Apoio a Ambientes de Grande Escala: Capacidade de lidar com grandes volumes de dados em infraestruturas distribuídas.
- Suporte a Ambientes Multicloud e Híbridos: Monitoramento eficaz em ambientes complexos.
Alertas e Notificações Inteligentes
- Detecção de Anomalias Baseada em IA/ML: Identificação automática de padrões incomuns sem a necessidade de definição de limites manualmente.
- Configuração Personalizável: Capacidade de definir regras e limites para alertas.
- Notificação flexíveis: Capacidade de notificar as equipes e usuários em aplicativo próprio mas também em Whatsapp, SMS, Telegram, MS Teams, e-mail e qualquer ferramenta que suporte webhook.
- Integração com Ferramentas de Gerenciamento de Incidentes: Compatibilidade com ferramentas que possuem integração viável via email, webservice e/ou webhook além de integração nativa com ferramentas de mercado como Jira, Helix, CA ServiceNow, etc.
Dashboards e Relatórios
- Dashboards e Relatórios Flexíveis: Capacidade de exibição de dados a respeito de indicadores em dashboards e relatórios customizados e de forma dinâmica, de acordo com a necessidade do momento.
- Tendências e Previsões: Relatórios históricos e preditivos para identificar tendências e prevenir falhas futuras.
- Relatórios Personalizados: Dados apresentados de acordo com as necessidades do negócio.
- Integração: Com o Priax você não precisa abrir mão da utilização de ferramentas consagradas para exibição de dashboards e dados de time series como o Grafana por exemplo. Suas bases de dados mantém padrões de mercado e podem ser integradas facilmente à qualquer ferramenta de exibição de dados.
Seleção e Customização de ICs e Indicadores a serem Observados
O Priax, ao detectar um IC automaticamente habilita os indicadores que são selecionados como indicador padrão do IC. Porém, podemos customizar, habilitar ou desabilitar o monitoramento de qualquer indicador de qualquer IC, conforma a necessidade de cada situação.
Habilitando e desabilitando Indicadores
Para isso, na tela principal do Priax, podemos navegar na árvore de ICs, selecionar o item desejado e na aba Monitoring selecionar ou deselecionar os indicadores desejados.
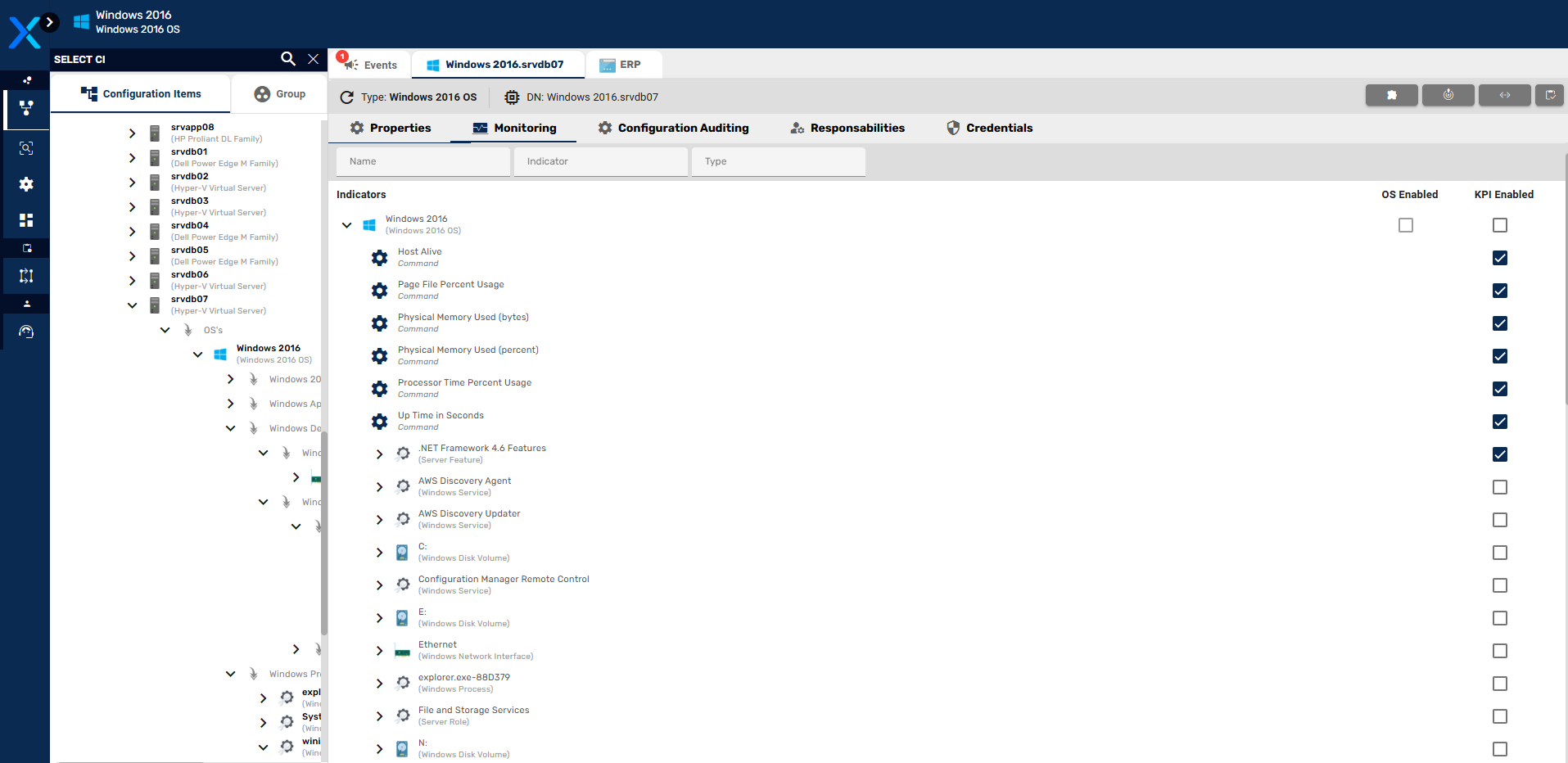
Customização de Indicadores
Para customizar o indicador, pode-se clicar no ícone  no indicador do IC desejado. Será exibida a tel abaixo:
no indicador do IC desejado. Será exibida a tel abaixo:
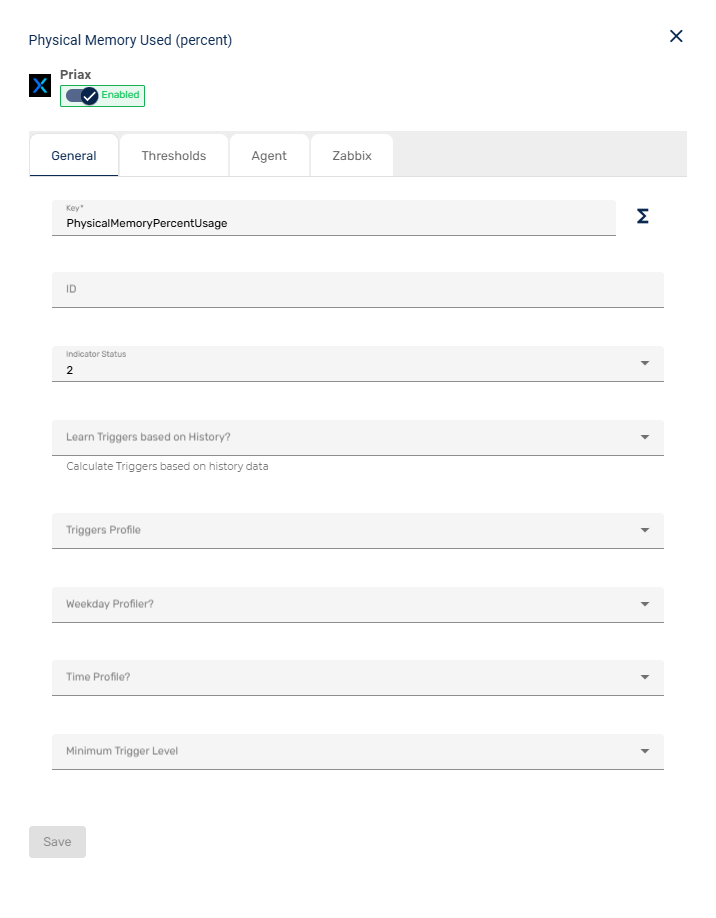
Ao passar o mouse em cada uma das opções, as instruções de preenchimento serão exibidas, com uma pequena documentação individual por atributo.
Definindo Triggers estáticas
Triggers são os limites que podem ser definidos para que, ao coletar os valores de um indicador, o Priax avalie se deve ou não gerar um evento e seus respectivos alertas e notificações. Para definir estaticamente esses limites customize vá para a aba Thresholds.
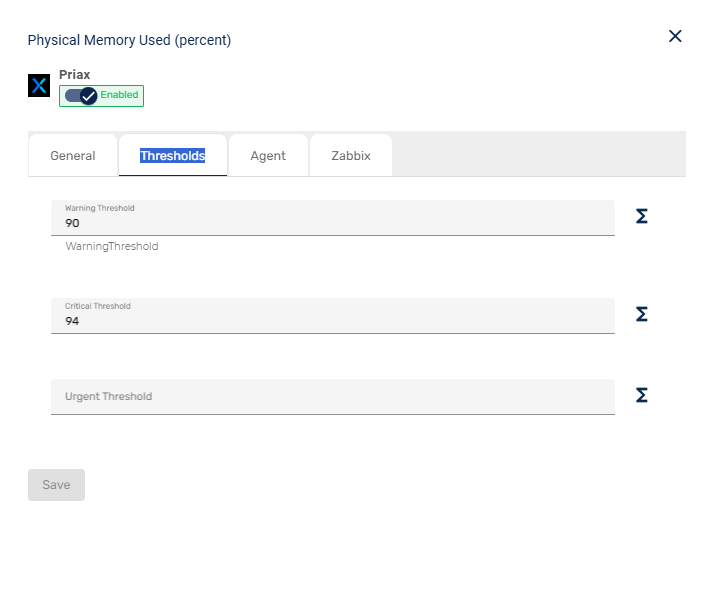
Configure os limites conforme seu desejo:
- Warning Threshold: Primeiro limite que pode ser ativado.
- Average Threshold: Segundo nível de criticidade de alerta que pode ser ativado.
- Urgent Threshold: Terceiro e mais crítico nível de alerta que pode ser ativado.
Esses três níveis de alerta podem ser utilizados no atributo Check Parameters para que sejam efetivamente utilizados
Habilitando o Cálculo de automático de Triggers (Linha Base)
O Priax suporta a geração de alertas baseado em cálculo automatizado de linha base. Para que os indicadores passem a gerar alertas sem a necessidade de explicitar os limites fixos você pode habilitar o cálculo de trigger baseado em histórico.
Para isso localize a opção Learn "Triggers based on History" na tela de configuração do indicador e habilite essa opção. Depois configure as opções conforme descrito abaixo.
- Triggers Profile: Selecione se as triggers devem ser calculadas para limites superiores, inferiores ou para ambos. Quando um indicador cuja a normalidade fica abaixo dos valores que podem causar problemas, então selecione a opção Upper Limits. Para indicador cuja a normalidade se situa acima de valores que podem causar problemas, selecione Botton Limits. E para indicador cuja a normalidade não pode se afastar de uma média, selecione Upper and Botton Limits.
- Weekday Profile: Selecione True se você deseja ter um cálculo de trigger diferenciado para dia da semana.
- Time Profile: Selecione True se você deseja ter um cálculo de trigger diferenciado para cada horário do dia.
- Minimum Trigger Level: Selecione o nível mínimo de trigger que será criado para o indicador. Se você selecionar High, apenas um nível de trigger será calculado. Se você selecionar Average, serão criados dois níveis e se você selecionar Warning serão criados três níveis.
- Time Window: Selecione quanto tempo de dados serão considerados para criar as triggers, as opções são: 24 horas, 7 dias, 30 dias, 180 dias, 365 dias.
Importante, os indicadores serão coletados pelos PPA Agents. Eles devem ser instalados conforme explicado em seção específica deste manual.
Criação do Indicador no Discovery
O Priax pode auto-habilitar um indicador para um Item de Configuração quando ele for descuberto pelo processo de Discovery. Para isso, basta editar o tipo de IC, navegando na árvore de categorias (Grupos) de ICs, selecionar a aba "KPI's Default Values".
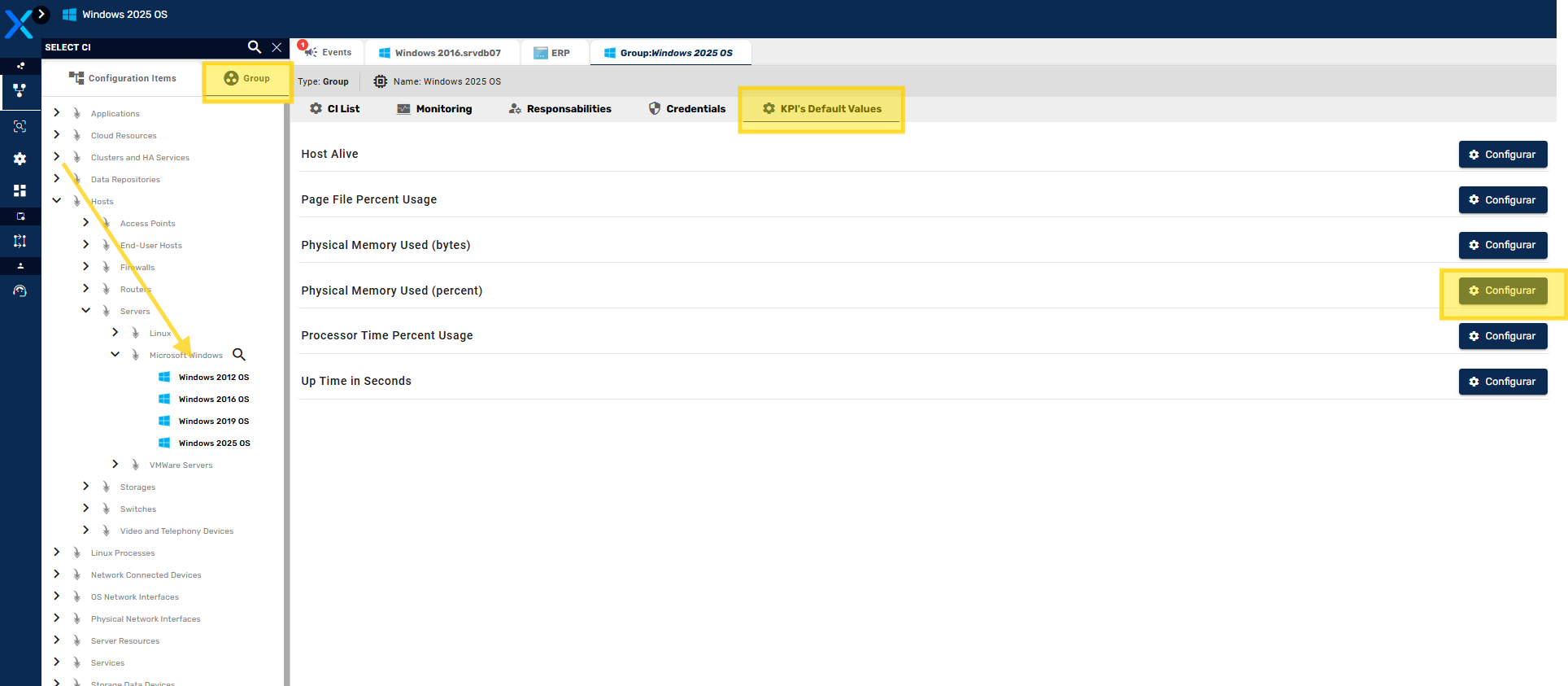
Localize o Indicador desejado e clique em Configurar no indicador desejado.
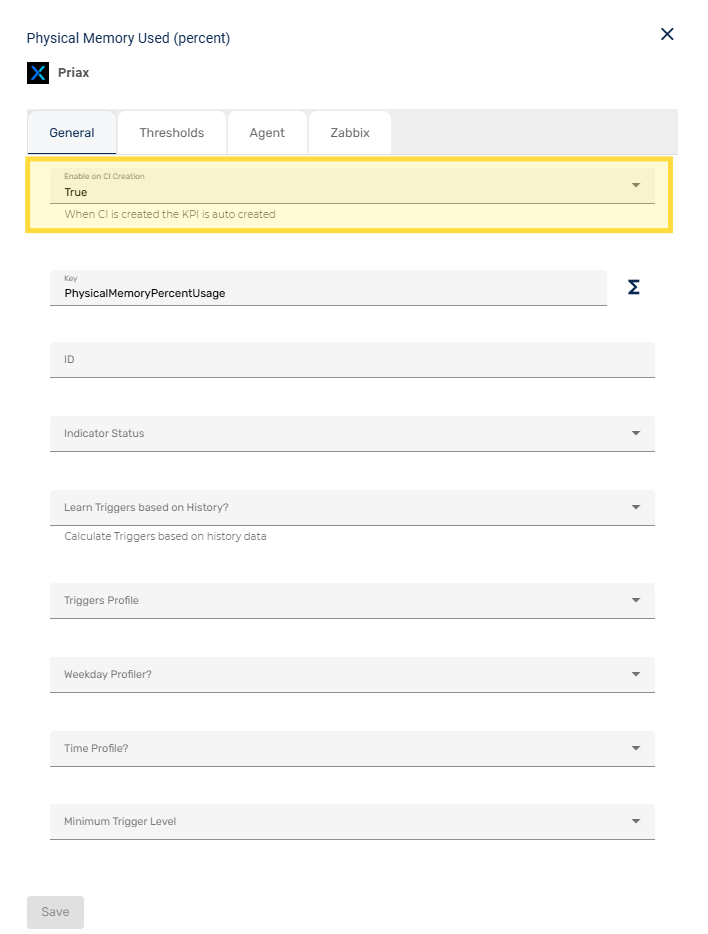
Na primeira opção "Enable on CI Creation" selecione a opção "True".
Priax Performance and Availability Agent
Funções dos diferentes agentes
Os agentes do Priax são responsáveis por um conjunto diferente de funções onde cada uma delas serve a um proposito diferente. A definição de quais pacotes devem ser instalados em cada ambiente é uma definição do projeto alinhada ao licenciamento do produto.
O agente PPA é o responsável pelo monitoramento de capacidade/performance do Priax.
Sistemas operacionais suportados por agente
| Sistema Operacional | PPA | Versão Pacote |
| Sistemas operacionais Linux | ||
| RHEL 6 | X | 6 |
| RHEL 7 | X | 7 |
| RHEL 8 | X | 7 |
| RHEL 9 | X | 7 |
| Centos 6 | X | 6 |
| Centos 7 | X | 7 |
| Centos 8 | X | 7 |
| Oracle Linux 6 | X | 6 |
| Oracle Linux 7 | X | 7 |
| Oracle Linux 8 | X | 7 |
| Ubuntu 14 | X | 6 |
| Ubuntu 16 | X | 7 |
| Ubuntu 18 | X | 7 |
| Ubuntu 20 | X | 7 |
| Ubuntu 22 | X | 7 |
| Debian 7 | X | 6 |
| Debian 8 | X | 7 |
| Debian 9 | X | 7 |
| Debian 10 | X | 7 |
| Debian 11 | X | 7 |
| Debian 12 | X | 7 |
| Amazon Linux AMI | X | 7 |
| Amazon Linux 2 | X | 7 |
| Suse 12 | X | 7 |
| Kali Linux 2019 | X | 7 |
| Kali Linux 2023 | X | 7 |
| Rocky Linux 8 | X | 7 |
| Rocky Linux 9 | X | 7 |
| Sistemas operacionais Windows | ||
| Windows Server 2008 | X | Nda |
| Windows Server 2012 | X | Nda |
| Windows Server 2016 | X | Nda |
| Windows Server 2019 | X | Nda |
| Windows Server 2022 | X | Nda |
| Windows 7 | X | Nda |
| Windows 8 | X | Nda |
| Windows 10 | X | Nda |
| Windows 11 | X | Nda |
Sistemas operacionais não incluídos na lista não tem suporte dos agentes e havendo necessidade entrar em contato com a equipe de suporte do Priax.
Arquivos de instalação
Dependendo da versão do Sistema Operacional diferentes pacotes são utilizados para diferentes instalações.
Windows
O pacote de instalação para sistemas operacionais Windows é um arquivo .msi que possui embutido no mesmo pacote todos os agentes.
Para sistemas operacionais Windows x86 não são mais suportados.
Para sistemas operacionais Windows x64 deve-se utilizar o pacote PriaxAgent.msi
Sistemas operacionais Linux
Para instalação em sistemas operacionais Linux cada versão deve fazer uso de um pacote específico para cada agente onde a instalação do agente do PPA para Linux utiliza o pacote PPAClient, o agente do PCM utiliza o pacote PCMClient e o PIA utiliza o pacote PIAgent.
Considerando a versão do pacote descrita na tabela Matriz de compatibilidade o nome do pacote a ser utilizado é determinado por ela.
EXEMPLOS:
Para instalação do agente do PPA em um Ubuntu 14 deve-se utilizar o pacote PPAClient6 da mesma forma que em um Centos 6;
Para instalação do agente do PCM em um RHEL 8 utiliza-se o pacote PCMClient7 assim como em um Debian 9.
Requisitos de instalação
Antes de iniciar a instalação é necessário garantir que o sistema operacional atenda um conjunto mínimo de requisitos para que a instalação e funcionamento dos agentes ocorra de forma esperada.
Windows
Para sistemas operacionais Windows os requisitos para funcionamento do agente são:
Possuir privilégio administrativo para a instalação do agente se realizada de forma manual;
Ao menos versão 4.6.2 do .Net Framework;
Ao menos versão 3.0 do Powershell;
Sistemas operacionais Linux
Para instalação em sistemas operacionais Linux os requisitos são:
Possuir acesso privilegiado ao host para instalação manual;
Quando instalando agentes de pacote 6 o host deve possuir ao menos a versão 1.10 da lib krb5 ou correspondente do sistema operacional;
Pacote “tar” instalado pois o pacote de instalação é compactado usando tar;
Sudo instalado.
Fluxos de comunicação dos agentes
De forma geral o agente quando instalado, precisa se comunicar com a API do servidor de gerência do agente e com o servidor de mensageria. Está comunicação é sempre partindo do agente para o servidor. Abaixo segue um exemplo de configuração possível mas vale lembrar que ela é especifica de cada ambiente.
Neste exemplo a API onde os agentes conectam esta configurada para utilizar o protocolo HTTP na porta 9090.
|
Agente |
Origem |
Destino |
Porta TCP |
|
PPA |
Agente |
Servidor |
9090 |
|
5672 |
Para que o agente funcione, quando utilizando nomes de host é necessário que o nome seja possível de ser resolvido para IP.
Processo de instalação
Windows
Para instalação em sistemas operacionais Windows, após garantir que o host possua os requisitos, deve-se executar o arquivo MSI disponível para a versão do sistema operacional.
Instalação de forma manual
Iniciando a instalação de forma manual executando o arquivo MSI dentro do host onde se deseja instalar o agente será exibida uma janela de boas-vindas. Clicar em Next para iniciar a instalação.
-
Welcome Priax Agente Setup
O próximo passo é a seleção do local onde deseja-se instalar o agente. O padrão é C:\Program Files\Priax Agent\
Manter a seleção de instalação para todos usuários e clicar em Next para prosseguir.
-
Local de instalação
Na tela de configuração da API deve-se ter atenção para os valores cadastrados onde eles devem ser os nomes de host/endereços IP dos servidores da API. Após definir os valores clicar em Next para prosseguir.
Em Endereço deve-se definir o endereço http/https para comunicação com a API considerando a configuração do ambiente assim como a porta onde a API responde.
Em endereço do serviço de fila definir o endereço para a o servidor de mensageria considerando a configuração do ambiente.
Abaixo um EXEMPLO de configuração.
-
Priax API
Na próxima janela são selecionados quais os agentes serão instalados.
Selecionar os necessários e clicar em Next para prosseguir.
Vale lembrar que esta configuração depende de quais módulos do agente são utilizados onde a imagem abaixo é apenas um EXEMPLO.
-
Priax Agents
Será exibida uma tela informando que o agente está pronto para ser instalado, e clicando em Next a instalação será iniciada.
-
Confirmar instalação
Finalizada a instalação será exibida uma janela informando que a instalação ocorreu com sucesso.
-
Finalizada a instalação
Instalação em linha de comando
O mesmo pacote MSI possibilita também a instalação via linha de comando com o objetivo de possibilitar o uso de soluções de distribuição de software ou instalação automatizada.
Para realizar a instalação via linha de comando os seguintes parâmetros devem ser passados para a execução do MSI.
URL = endereço da API;
RMQ = endereço do servidor de mensageria;
PPA = se deve ser instalado ou não agente do PPA. Deve ser 1 caso queira instalar e 0 em caso negativo;
PIA = se deve ser instalado ou não agente do PIA. Deve ser 1 caso queira instalar e 0 em caso negativo;
PCM = se deve ser instalado ou não o agente do PCM. Deve ser 1 caso queira instalar e 0 em caso negativo;
Path do arquivo MSI.
Sintaxe da execução via linha de comando
msiexec /quiet /i pathdoarquivomsi URL="enderecoAPI" PPA=0/1 PCM=0/1 PIA=0/1 RMQ="enderecoMensageria"
Exemplo de linha de comando lendo o arquivo MSI localizado em c:\temp\PriaxAgent.msi, instalando somente o PCM utilizando endereço da API https://srvpriax.priax.io:9090 e servidor de mensageria srvpriax.priax.io:5672
msiexec /quiet /i c:\temp\PriaxAgent.msi URL="https://srvpriax.priax.io:9090" PPA=0 PCM=1 PIA=0 RMQ="srvpriax.priax.io:5672"
Sistemas operacionais Linux
Em sistemas operacionais Linux durante o processo de instalação é criado um usuário local no host onde está sendo instalado o agente sendo este o usuário que roda a aplicação.
Abaixo usuários que são criados considerando cada pacote instalado.
|
Agente |
Usuário |
|
PPA |
PriaxPPAClient |
|
PCM |
PriaxPCMClient |
|
PIA |
PriaxPIAgent |
Para instalação em sistemas operacionais Linux basta copiar o arquivo de instalação para o host, tornar ele executável e executar.
Para tornar o arquivo executável executar chmod +x nomedoarquivo
EXEMPLO: # chmod +x /tmp/PriaxAgent/PPAClient7
Quando a instalação é iniciada será exibido o processo da validação de integridade do arquivo assim como da instalação.
# /tmp/PPAClient7
Verifying archive integrity... 100% MD5 checksums are OK. All good.
Uncompressing Priax Agents Setup 100%
#
Instalação remota
Existe um processo que possibilita a instalação dos agentes em hosts de forma remota e em massa possibilitando assim uma rápida distribuição dos agentes em conjuntos de hosts.
Este processo foi criado a fim de possibilitar a instalação dos agentes do Priax em hosts que o Priax consegue gerenciar como alternativa a outras soluções de distribuição de software como o System Center, Ansible entre outros.
Este processo inicia-se no host do PPAServer, lê conjuntos de informações de acesso que já devem estar cadastradas no Priax e tenta conexão aos hosts para em primeiro lugar avaliar se é necessário ou não a instalação do agente no host e em caso positivo, valida os requisitos e instala se possível.
Fluxos de comunicação para instalação remota
Considerando os fluxos de comunicação necessários para este processo poder ser executado, eles diferem dependendo do tipo de host onde se está tentando instalar o agente, mas são os mesmos utilizados para o Discover. Em ambos os casos a comunicação inicia-se no servidor onde o processo está rodando com destino onde o agente deve ser instalado.
|
Origem |
Destino |
Protocolos/Portas utilizadas |
|
Servidor PPAServer |
Servidores/estacoes Windows |
WMI; Mais informações no link abaixo |
|
Servidor PPAServer |
Servidores Linux |
SSH; TCP 22 |
Sendo hosts Windows, a comunicação toda é feira via WMI e a descrição do funcionamento do protocolo WMI em relação a rede esta descrita no link https://learn.microsoft.com/en-us/windows/win32/wmisdk/connecting-to-wmi-on-a-remote-computer
Permissões necessárias para instalação remota
Em relação a hosts Windows, é necessário que o usuario utilizado seja ao menos membro do grupo local dos hosts Administrators ou Power Users;
Em relação a hosts Linux, o usuário não precisa ser “root” mas deve ter permissão de execução do pacote de instalação do agente de forma privilegiada.
Permissão esta pode ser concedida de diversas formas mas é importante saber que durante o processo em relação a hosts Linux não é possível interação de usuário com credenciais como acontece quando em sessão interativa (usando o putty por exemplo). Isto significa que as permissões requeridas para os processos rodarem devem ser possíveis sem que seja necessário digitar a senha novamente, de forma interativa.
Se o usuario utilizado é “root” a instalação acontece de forma direta e caso não seja, com uso do sudo.
Durante a execução do processo de instalação em host Linux, é criado no diretório /tmp o diretório PriaxAgent e os pacotes de instalação necessários copiados para este diretório. Ao final do processo eles são removidos.
Exemplo de configuração que pode ser aplicada é de ajustar a configuração do sudoers como o exemplo abaixo. Atenção ao usuario utilizado.
Cmnd_Alias PRIAXPERMISSIONSAGENTINSTALL /tmp/PriaxAgent/PPAClient6, /tmp/PriaxAgent/PCMClient6, /tmp/PriaxAgent/PPAClient7, /tmp/PriaxAgent/PCMClient7, /tmp/PriaxAgent/PIAgent7
Defaults!PRIAXPERMISSIONSAGENTINSTALL !requiretty
usuarioUtilizadoParaConexao ALL=(ALL) NOPASSWD: PRIAXPERMISSIONSAGENTINSTALL
Exibição de Indicarores dos Itens de Configuração
ICs e seus filhos
Após descobrir os Itens de Configurações (ICs) e suas relações, o Priax os cadastra em sua CMDB interna e fornece recursos de navegação para que você compreenda as descobertas, entenda a composição de cada tecnologia e também a cadeia de dependência e impacto entre esses ICs. Quando monitorados o Priax ainda fornece a capacidade de exibir os indicadores e suas coletas realizadas ao longo do tempo, exibindo gráficos do tipo Time Series para que se consiga compreender o funcionamento ativo desses elementos.
Ao autenticar, na página principal do Priax, é exibida a no painel da esquerda a árvore de ICs. A árvore de ICs, em sua raiz apresenta as famílias de ICs que é o primeiro nível de classificação. No segundo nível temos as categorias de ICs, essas subdivisões existem para organizar logicamente os ICs e facilitar a navegação na CMDB.
Na imagem acima, estão expandidas duas das principais famílias de ICs: Cloud Resources e On-Premises Resources. Nessas duas famílias vamos encontrar os principais tipos de ICs que estão relacionados à Infraestrutura de TI. Dentro dessas categorias temos por exemplo os Dispositivos presentes nos datacenters, os hosts e além de recursos independentes armazenados em cloud.
Expandindo a categoria Servers por exemplo, vamos encontrar os servidores do ambiente on-premises. Neste terceiro nível começamos a encontrar os Itens de Configuração Raiz, que são aqueles que não possuem um pai. Essa relação pai e filho é crada entre dois ICs que compõe um ao outro. Um IC pai é composto de seus filhos. Essa relação de composição presume que um filho possui apenas um pai.
Na imagem abaixo pode ser visto um servidor. Ao expandir, podemos ver o Sistema Operacional desse servidor. Ao clicar no servidor podemos ver além de seus atributos, no painel da direita podemos ver seus indicadores.
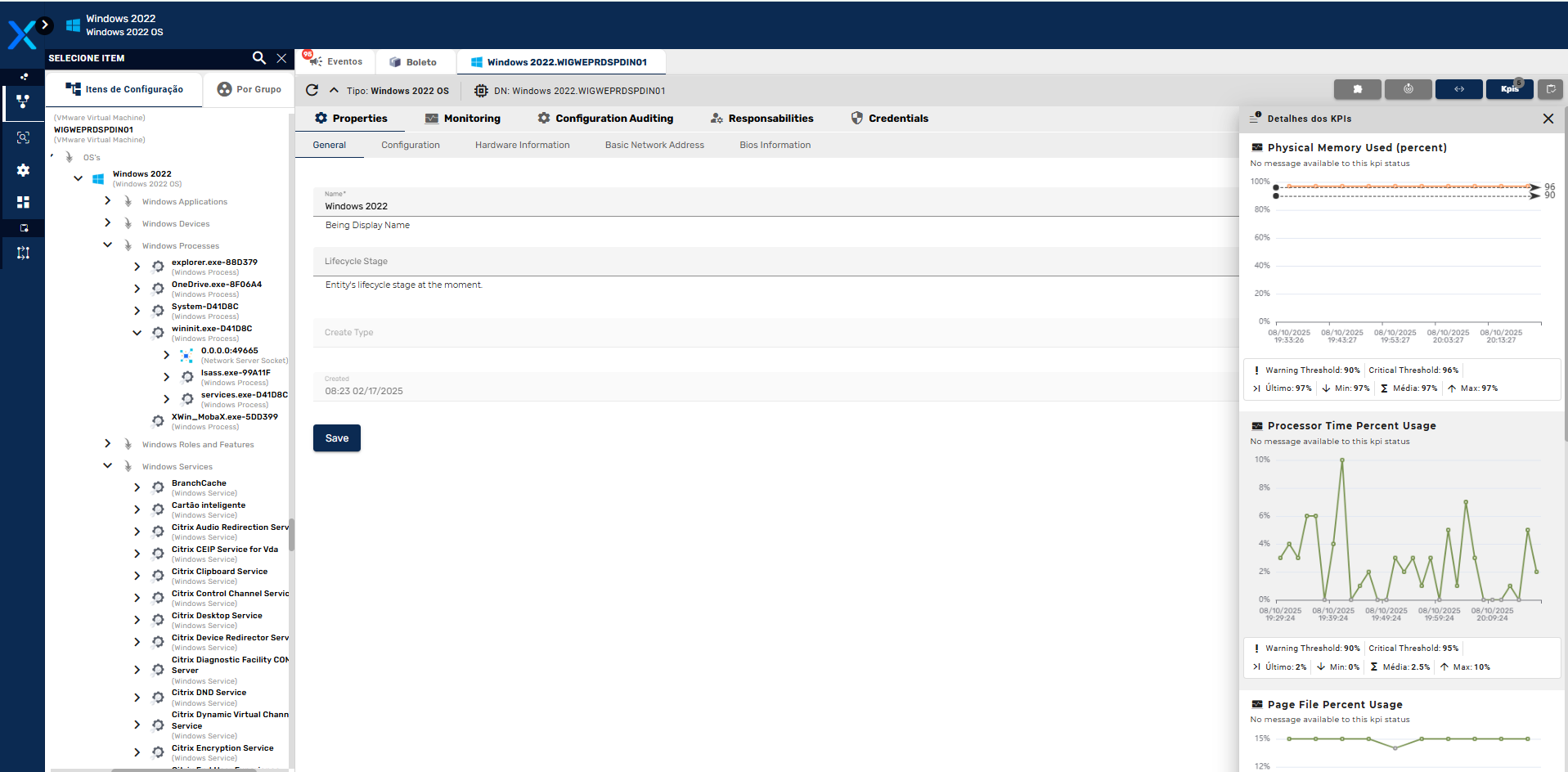
Detalhes dos Indicadores
Ao clicar no gráfico de um indicador podemos navegar nos dados, filtrá-los, dar zoom em um período de tempo.
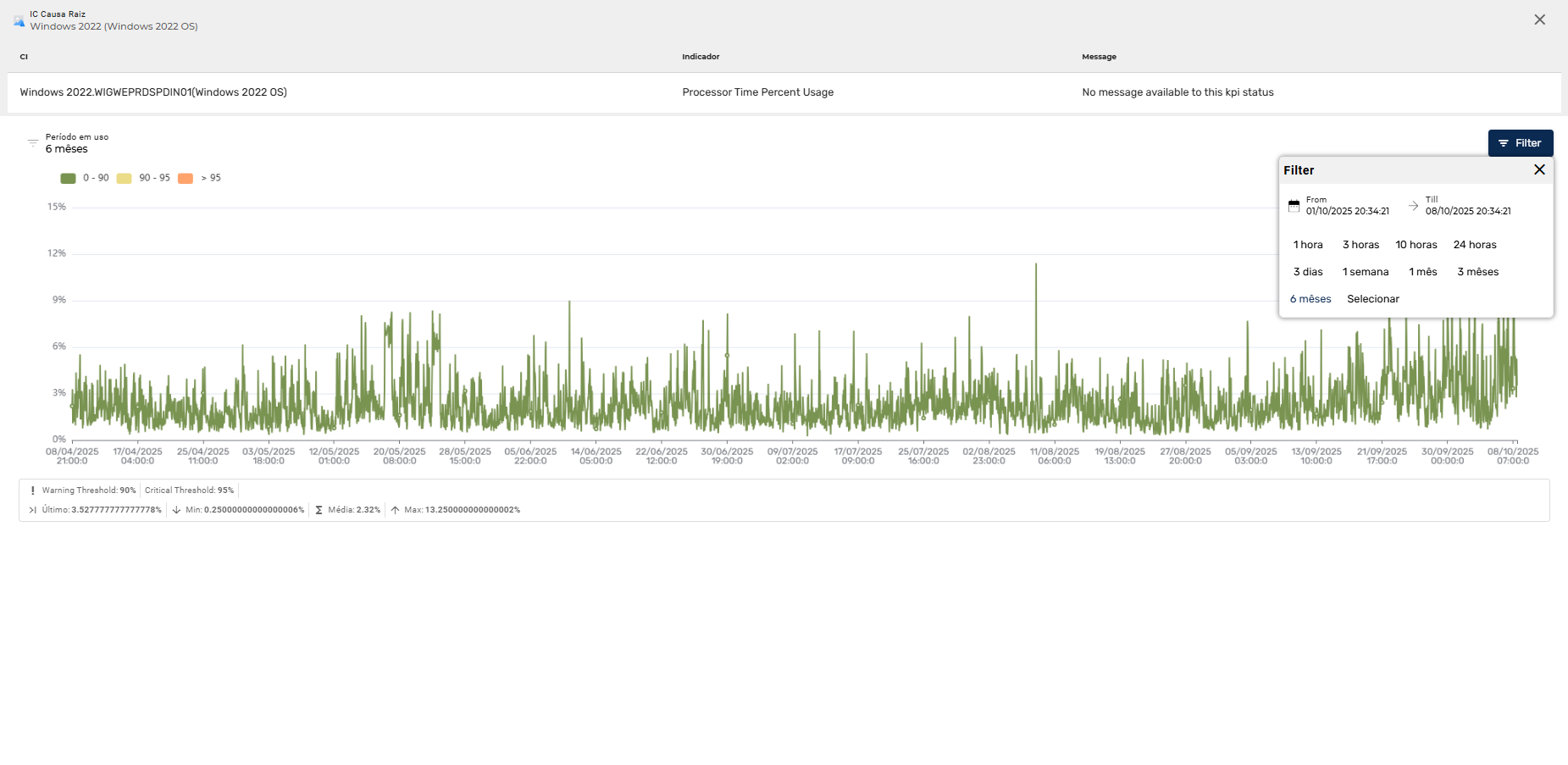
Indicadores Nativos e Templates
O Priax permite a criação de Indicadores customizados de forma muito flexível, permitindo a definição de scripts, executáveis e procedimentos complexos. Esse nível de customização praticamente torna possível que o Priax colete informações sobre qualquer componente de qualquer componente da infraestrutura e a partir e de diversos executores com diferentes tecnologias base. No entanto, nativamente são suportados mais de oito mil tipos de ICs com milhares de indicadores disponíveis com habilitação através de um simples clique.
Segue uma lista de alguns dos principais Itens de Configuração suportados, lembrando que a lista completa possui mais de 8 mil tipos de itens de configuração:
- Sistemas Operacionais Microsoft Windows Server (Todos com suporte ativo)
- Indicadores do Sistema Operacional
- Memória e Paginação
- CPU física e Virtual
- Discos Físicos do Sistema Operacional
- Discos lógicos do Sistema Operacional
- Interfaces de rede
- Atividade por protocolo de camada 2 e 3
- Erros
- Tráfego in e out
- Socket de Rede
- Atividade TCP e UDP (Camada 4 de rede)
- Serviços do Sistema Operacional
- Processos do Sistema Operacional
- Programas Instalados no Sistema Operacional
- Todas as funcionalidades nativas (Roles) do sistema operacional
- Indicadores do Sistema Operacional
- Sistemas Operacionais Linux (Distros: Oracle Linux, RedHat, Debian, Suse, Ubuntu, entre outras)
- Indicadores do Sistema Operacional
- Memória e Paginação
- CPU física e Virtual
- Discos Físicos do Sistema Operacional
- Discos lógicos do Sistema Operacional
- Interfaces de rede
- Atividade por protocolo de camada 2 e 3
- Erros
- Tráfego in e out
- Socket de Rede
- Atividade TCP e UDP (Camada 4 de rede)
- Serviços do Sistema Operacional
- Processos do Sistema Operacional
- Programas Instalados no Sistema Operacional
- Pacotes de Software nativas do Sistema Operacional (DEB, RPM)
- Indicadores do Sistema Operacional
- Tecnologia VmWare (SNMP e API)
- Datacenters
- Clusters
- Servidores Físicos
- Máquinas Virtuais
- Storages
- Networks e Port Groups
- Bancos de Dados MySQL, Oracle, MS SQL Server, PostgreSQL
- Instância do Banco de Dados
- Database
- Tabelas
- Campos de Tabelas
- Instâncias de Servidores de Aplicação, seus Deplyments, Aplicações e Websites
-
- Microsoft IIS
- NGINX
- Apache
- Tomcat
- Wildfly
- JBoss
- Oracle WebLogic
-
- Serviços de Mensagens e Filas (Servidor, Filas, Tópicos, Exchanges)
- Kafka
- RabbitMQ
- JMS
- MQ
- Outros dispositivos
- Servidores Físicos (Dell, HP, IBM, HUAWEI, CISCO, etc.)
- Componentes de Hardware
- Discos lógicos e físicos
- Interface de Rede
- Periféricos
- Interfaces de Gerenciamento
- Switches (Cisco, Dell, 3Com, Extreme, EdgeCore, HPE, etc.)
- Interfaces (portas)]
- Roteadores
- Interfaces do Roteador
- Equipamentos relacionados à Segurança da Informação:
- Soluções de Antivírus
- Soluções de AntiSpam
- Soluções de Unified Threat Management
- Soluções Network Access Control
- Equipamentos de Firewall
- Storages (EMC, HP, DELL, HUAWEI, ETC)
- Discos Físicos
- Grupos de Disco
- Discos Lógicos
- Servidores Físicos (Dell, HP, IBM, HUAWEI, CISCO, etc.)
- Rede
- Monitoramento de tráfego, consumo e latência de Rede de forma passiva e ativa, utilizando técnicas que independem de fabricantes ou utilizando protocolos proprietários e Open Source.
- Soluções de Backups e Rotinas de Backups
- Containers
- Docker
- Kubernetes e OpenShift
- Namespaces
- Deployments
- Replicasets
- Statefulsets
- Daemonsets
- Pods
- Services
- Ingress
- PV
- PVC
- Cloud Computing
- Discovery AWS
- Discovery Azure
- Discovery GPC
- OCI - Oracle Cloud Enterprise
- IBM Cloud
- OpenStack (Serviços cloud que utilizam tecnologia OpenStack)
Observabilidade de Aplicações (APM)
Introdução à Observabilidade de Aplicações
O que é a Observabilidade de Aplicações?
Observabilidade de Aplicações permite entender um sistema externamente, possibilitando fazer perguntas sobre ele sem precisar conhecer seu funcionamento interno. Além disso, facilita a solução de problemas desconhecidos e imprevistos . A observabilidade ajuda a responder à pergunta: “Por que isso está acontecendo?”
Para fazer perguntas sobre um sistema, é necessário que sua aplicação esteja devidamente instrumentada. Isso significa que o código da aplicação ou algum componente intimamente ligado à aplicação como o Application Server, máquina virtual da linguagem da aplicação ou intepretador de comandos da linguagem devem emitir sinais, como rastreamentos (traces), métricas e logs. Uma aplicação está bem instrumentada quando os desenvolvedores não precisam adicionar mais instrumentação para investigar problemas, pois já possuem todas as informações necessárias.
O Priax, além de possuir mecanismos de instrumentação próprios pode é compatível com mecanismos consagrados do mercado como OpenTelemetry, Jaeger ou Opensearch APM. Todos esses mecanismos são usados para instrumentar o código da aplicação e tornar um sistema observável.
Telemetria, métricas e confiabilidade de Aplicações
Telemetria se refere aos dados emitidos por um sistema e seu comportamento. Esses dados podem ser apresentados na forma de rastreamentos, métricas e logs.
A confiabilidade responde à pergunta: “O serviço está fazendo o que os usuários esperam que ele faça?”. Por exemplo, um sistema pode estar disponível 100% do tempo, mas, se ao clicar em "Adicionar ao Carrinho" para incluir um par de sapatos pretos, o sistema não adicionar sempre os sapatos pretos, ele é considerado não confiável.
Métricas são agregações ao longo do tempo de dados numéricos sobre sua infraestrutura ou aplicação. Exemplos incluem:
- Taxa de erro do sistema
- Uso da CPU
- Taxa de solicitações de um serviço
SLI (Service Level Indicator) é uma medida do comportamento de um serviço. Um bom SLI mede o serviço do ponto de vista dos usuários. Um exemplo de SLI é a velocidade de carregamento de uma página web.
SLO (Service Level Objective) é a forma como a confiabilidade é comunicada dentro da organização ou para outras equipes, vinculando um ou mais SLIs ao valor de negócio.
Entendendo o Rastreamento Distribuído
O rastreamento distribuído permite observar solicitações conforme elas se propagam por sistemas distribuídos e complexos. Ele melhora a visibilidade sobre a saúde de uma aplicação ou sistema e ajuda a depurar comportamentos difíceis de reproduzir localmente.
O rastreamento distribuído é essencial para sistemas distribuídos, que frequentemente apresentam problemas não determinísticos ou complexos demais para serem reproduzidos em um ambiente local.
Para entender o rastreamento distribuído, é importante conhecer seus principais componentes: logs, spans e traces.
Logs
Um log é uma mensagem com carimbo de tempo emitida por serviços ou componentes. Diferente dos rastreamentos, os logs não estão necessariamente associados a uma solicitação ou transação específica. Eles estão presentes em praticamente todo software e foram amplamente utilizados por desenvolvedores e operadores para entender o comportamento dos sistemas.
Exemplo de log:
I, [2021-02-23T13:26:23.505892 #22473] INFO -- : [6459ffe1-ea53-4044-aaa3-bf902868f730] Started GET "/" for ::1 at 2021-02-23 13:26:23 -0800
No entanto, os logs não são suficientes para rastrear a execução do código, pois geralmente carecem de informações contextuais, como o local de origem da chamada.
Os logs se tornam muito mais úteis quando são incluídos como parte de um span ou quando estão correlacionados a um trace e um span.
Spans
Um span representa uma unidade de trabalho ou uma operação. Ele rastreia operações específicas de uma solicitação, fornecendo uma visão detalhada do que ocorreu durante sua execução.
Um span inclui:
- Nome
- Dados temporais
- Mensagens de log estruturadas
- Metadados (Atributos) que fornecem mais informações sobre a operação rastreada.
Atributos de Span
Os atributos são metadados associados a um span.
| Chave | Valor |
| http.request.method | GET |
| network.protocol.version | 1.1 |
| url.path | /webshop/articles/4 |
| url.query | ?s=1 |
| server.address | example.com |
| server.port | 8080 |
| url.scheme | https |
| http.route | /webshop/articles/:article_id |
| http.response.status_code | 200 |
| client.address | 192.0.2.4 |
| client.socket.address | 192.0.2.5 (o cliente passa por um proxy) |
| user_agent.original | Mozilla/5.0 (Windows NT 10.0; Win64; ...) |
Rastreamentos Distribuídos
Um rastreamento distribuído (trace) registra os caminhos percorridos por solicitações (feitas por uma aplicação ou usuário final) enquanto atravessam arquiteturas multi-serviço, como aplicações baseadas em microsserviços ou serverless.
Um trace é composto por um ou mais spans:
- O span raiz representa o início e o fim de uma solicitação.
- Os spans filhos fornecem um contexto detalhado sobre o que ocorre durante a solicitação.
Sem rastreamento, identificar a causa raiz de problemas de desempenho em sistemas distribuídos pode ser desafiador. O rastreamento simplifica a depuração e facilita o entendimento de sistemas complexos, detalhando o que acontece com uma solicitação enquanto ela se propaga pelo sistema.
Muitos backends de observabilidade visualizam os traces como diagramas de cascata (waterfall diagrams), que demonstram a relação entre spans pai e filhos, representando relações hierárquicas e aninhadas.
Propagação de Contexto
Entenda o conceito que viabiliza o Rastreamento Distribuído.
Com a propagação de contexto, os sinais podem ser correlacionados entre si, independentemente de onde são gerados. Embora não se limite apenas ao rastreamento, a propagação de contexto permite que os rastreamentos construam informações causais sobre um sistema que está distribuído de forma arbitrária entre processos e limites de rede.
Para entender a propagação de contexto, é necessário conhecer dois conceitos principais: contexto e propagação.
Contexto
O contexto é um objeto que contém as informações necessárias para que os serviços emissores e receptores, ou unidades de execução, possam correlacionar um sinal com outro.
Por exemplo: se o serviço A chama o serviço B, um span do serviço A, cujo ID está presente no contexto, será utilizado como span pai para o próximo span criado no serviço B. O ID do rastreamento (trace ID) também será incluído no contexto e utilizado para o próximo span criado no serviço B. Isso significa que esse novo span fará parte do mesmo rastreamento que o span do serviço A.
Propagação
A propagação é o mecanismo responsável por mover o contexto entre serviços e processos. Ela serializa ou desserializa o objeto de contexto e fornece as informações relevantes para que o contexto seja transferido de um serviço para outro.
Geralmente, a propagação é gerenciada automaticamente pelas bibliotecas de instrumentação e é transparente para o usuário. No entanto, caso seja necessário realizar a propagação de contexto manualmente, você pode utilizar a API de Propagadores (Propagators API) de cada biblioteca de instrumentação.
Sinais e Métricas das Aplicações
Tipos de Sinais
Conheça as categorias de telemetria suportadas pelo Priax e bibliotecas de instrumentação compatíveis:
O objetivo de uma biblioteca de instrumentação é coletar, processar e exportar sinais. Sinais são saídas do sistema que descrevem a atividade subjacente do sistema operacional e das aplicações em execução em uma plataforma. Um sinal pode representar algo que você deseja medir em um ponto específico no tempo, como a temperatura ou o uso de memória, ou um evento que percorre os componentes de um sistema distribuído e que você gostaria de rastrear.
Com o Priax você pode agrupar diferentes sinais para observar o funcionamento interno de uma mesma tecnologia sob diferentes perspectivas.
Atualmente, o Priax é capaz de exibir, detalhar, quantificar e detalhar as seguintes categorias de sinais:
- Rastreamentos (traces)
- Métricas
- Logs
- Baggage
Rastreamentos (Traces)
O caminho de uma solicitação através da sua aplicação.
Os rastreamentos nos dão uma visão geral do que acontece quando uma solicitação é feita a uma aplicação. Seja sua aplicação um monólito com um único banco de dados ou uma complexa malha de serviços, os rastreamentos são essenciais para entender o “caminho” completo que uma solicitação percorre na sua aplicação.
Vamos explorar isso com três unidades de trabalho representadas como Spans (faixas de execução):
Observação
Os exemplos de JSON a seguir não representam um formato específico, especialmente o OTLP/JSON, que é mais detalhado.
1. Span Hello:
{
"name": "hello",
"context": {
"trace_id": "5b8aa5a2d2c872e8321cf37308d69df2",
"span_id": "051581bf3cb55c13"
},
"parent_id": null,
"start_time": "2022-04-29T18:52:58.114201Z",
"end_time": "2022-04-29T18:52:58.114687Z",
"attributes": {
"http.route": "some_route1"
},
"events": [
{
"name": "Guten Tag!",
"timestamp": "2022-04-29T18:52:58.114561Z",
"attributes": { "event_attributes": 1 }
}
]
}Este é o span raiz, indicando o início e o fim da operação inteira. Observe que ele tem um campo trace_id, mas não tem parent_id, o que o caracteriza como a raiz do rastreamento.
2. Span hello-greetings:
{
"name": "hello-greetings",
"context": {
"trace_id": "5b8aa5a2d2c872e8321cf37308d69df2",
"span_id": "5fb397be34d26b51"
},
"parent_id": "051581bf3cb55c13",
"start_time": "2022-04-29T18:52:58.114304Z",
"end_time": "2022-04-29T22:52:58.114561Z",
"attributes": {
"http.route": "some_route2"
},
"events": [
{
"name": "hey there!",
"timestamp": "2022-04-29T18:52:58.114561Z",
"attributes": {
"event_attributes": 1
}
},
{
"name": "bye now!",
"timestamp": "2022-04-29T18:52:58.114585Z",
"attributes": {
"event_attributes": 1
}
}
]
}Este span encapsula tarefas específicas, como exibir saudações, e seu parent_id é o ID do span raiz hello. Ele compartilha o mesmo trace_id, indicando que faz parte do mesmo rastreamento.
3. Span hello-salutations:
{
"name": "hello-salutations",
"context": {
"trace_id": "5b8aa5a2d2c872e8321cf37308d69df2",
"span_id": "93564f51e1abe1c2"
},
"parent_id": "051581bf3cb55c13",
"start_time": "2022-04-29T18:52:58.114492Z",
"end_time": "2022-04-29T18:52:58.114631Z",
"attributes": {
"http.route": "some_route3"
},
"events": [
{
"name": "hey there!",
"timestamp": "2022-04-29T18:52:58.114561Z"
}
]
}Este span representa a terceira operação neste rastreamento e, assim como o anterior, é um filho do span raiz (hello). Isso também o torna um irmão do span hello-greetings
Esses três blocos de JSON compartilham o mesmo trace_id e utilizam o parent_id para representar a hierarquia. Isso cria o rastreamento completo!
Uma observação importante é que cada Span se assemelha a um log estruturado, com contexto, correlação e hierarquia embutidos. Contudo, esses “logs estruturados” podem vir de diferentes processos, serviços, VMs ou datacenters, permitindo que o rastreamento represente uma visão ponta a ponta de qualquer sistema.
Detalhamento de uma span
Uma span representa uma unidade de trabalho ou operação e inclui:
- Nome
- ID do Span pai (vazio para spans raiz)
- Timestamps de início e fim
- Contexto do Span
- Atributos
- Eventos
- Links
- Status do Span
Exemplo de span:
{
"name": "/v1/sys/health",
"context": {
"trace_id": "7bba9f33312b3dbb8b2c2c62bb7abe2d",
"span_id": "086e83747d0e381e"
},
"parent_id": "",
"start_time": "2021-10-22 16:04:01.209458162 +0000 UTC",
"end_time": "2021-10-22 16:04:01.209514132 +0000 UTC",
"status_code": "STATUS_CODE_OK",
"status_message": "",
"attributes": {
"net.transport": "IP.TCP",
"net.peer.ip": "172.17.0.1",
"net.peer.port": "51820",
"net.host.ip": "10.177.2.152",
"net.host.port": "26040",
"http.method": "GET",
"http.target": "/v1/sys/health",
"http.server_name": "mortar-gateway",
"http.route": "/v1/sys/health",
"http.user_agent": "Consul Health Check",
"http.scheme": "http",
"http.host": "10.177.2.152:26040",
"http.flavor": "1.1"
},
"events": [
{
"name": "",
"message": "OK",
"timestamp": "2021-10-22 16:04:01.209512872 +0000 UTC"
}
]
}Contexto do Span
Os spans podem ser aninhados, como é indicado pela presença de um ID de span pai: os spans filhos representam suboperações. Isso permite que os spans capturem com mais precisão o trabalho realizado em uma aplicação. O span pai terá um trace_Id idêntico ao seu filho indicando portanto que atende a uma mesma requisição ao sistema.
O contexto do span é um objeto imutável presente em todos os spans que contém as seguintes informações:
- Trace ID: identifica o trace ao qual o span pertence.
- Span ID: identifica o próprio span.
- Trace Flags: uma codificação binária com informações sobre o trace.
- Trace State: uma lista de pares chave-valor que podem conter informações específicas de fornecedores.
Atributos
Os atributos são pares chave-valor usados para adicionar metadados a um span, permitindo capturar informações sobre a operação monitorada.
Por exemplo, se um span acompanha a operação de adicionar um item ao carrinho de compras em um sistema de e-commerce, você pode registrar o ID do usuário, o ID do item e o ID do carrinho.
- Você pode adicionar atributos durante ou após a criação de um span.
- É recomendável adicionar os atributos no momento da criação para que possam ser aproveitados pelo SDK na amostragem. Caso precise adicionar valores posteriormente, atualize o span.
Regras para atributos:
- As chaves devem ser strings não nulas.
- Os valores devem ser uma string, booleano, número (ponto flutuante ou inteiro) ou um array desses tipos.
Além disso, existem Atributos Semânticos, que são convenções padronizadas para nomes de atributos comuns. Utilizar nomes semânticos facilita a padronização de metadados entre sistemas.
Eventos do Span
Um evento do span pode ser visto como uma mensagem de log estruturada (ou anotação) associada a um span. Geralmente é usado para marcar um ponto singular e significativo no tempo durante a duração de um span.
Exemplo prático em um navegador web:
- Carregamento da página → O span é mais apropriado, pois acompanha uma operação com início e fim.
- Página se torna interativa → Um evento do span é mais adequado, pois representa um ponto específico no tempo.
Quando usar eventos do span versus atributos?
Se o timestamp específico for relevante, use um evento do span. Caso contrário, use atributos.
Links do Span
Os links permitem associar um span a um ou mais spans, indicando uma relação causal.
Por exemplo, em um sistema distribuído, algumas operações são rastreadas por um trace. Em resposta a essas operações, uma nova tarefa pode ser enfileirada para execução assíncrona. Para associar o trace da operação subsequente ao trace original, criamos um link de span.
Links são opcionais, mas são uma maneira eficaz de relacionar spans de diferentes traces.
Status do Span
Cada span possui um status com três valores possíveis:
- Unset: (padrão) indica que a operação foi concluída sem erros.
- Error: indica que ocorreu algum erro, como um HTTP 500 em um servidor.
- Ok: explicitamente definido pelo desenvolvedor para marcar o span como bem-sucedido.
Nota: Quando não houver um status Ok para spans que concluíram sem erros, considera-se um evento bem sucedido, pois o valor padrão Unset já cobre esse caso. Ok é usado para deixar explícito que um span é considerado bem-sucedido, sem ambiguidades.
Tipo do Span (Span Kind)
Ao criar um span, ele pode ser classificado como Client, Server, Internal, Producer ou Consumer. O tipo de span informa ao backend de rastreamento como o trace deve ser montado.
- Client: Representa uma chamada remota síncrona de saída, como uma solicitação HTTP ou consulta ao banco de dados.
- Server: Representa uma chamada remota síncrona recebida, como uma solicitação HTTP ou RPC.
- Internal: Representa operações que não cruzam limites de processo (ex: chamadas de funções locais ou middlewares).
- Producer: Representa a criação de uma tarefa a ser processada de forma assíncrona (ex: inserção em uma fila).
- Consumer: Representa o processamento de uma tarefa criada por um producer. Pode ser iniciado muito tempo após o término do span do producer.
Se o tipo não for especificado, ele é considerado Internal.
Métricas
Uma métrica é uma medida de um serviço capturada em tempo de execução. O momento em que a medição é registrada é conhecido como um evento de métrica, que inclui não apenas o valor medido, mas também o horário da captura e os metadados associados.
Métricas de aplicação e requisição são indicadores importantes de disponibilidade e desempenho. Métricas personalizadas podem oferecer insights sobre como os indicadores de disponibilidade impactam a experiência do usuário ou o negócio. Os dados coletados podem ser utilizados para alertar sobre interrupções ou para acionar decisões de escalonamento automático durante períodos de alta demanda.
Para compreender como as métricas funcionam quando se utiliza as bibliotecas de instrumentação compatíveis com o Priax, vamos analisar os componentes principais que ajudam na instrumentação do código.
Provedor de Meter (Meter Provider)
O Meter Provider é uma fábrica de Meters. Em aplicações, geralmente é inicializado uma única vez e seu ciclo de vida corresponde ao ciclo de vida da aplicação. A inicialização de um Meter Provider também envolve a configuração de Recursos e Exportadores. Esse é, normalmente, o primeiro passo ao configurar métricas no Priax. Em alguns SDKs compatíveis, um Meter Provider global já é inicializado automaticamente.
Meter
Um Meter é responsável por criar instrumentos de métrica que capturam medições sobre um serviço em tempo de execução. Os Meters são criados a partir de Meter Providers.
Exportador de Métricas (Metric Exporter)
Os Exportadores de Métricas enviam dados de métricas para um consumidor. Esse consumidor pode ser uma saída padrão (para depuração durante o desenvolvimento), o Priax utiliza o Opentelemetry Collector, ou qualquer backend de código aberto ou proprietário de sua escolha.
Instrumentos de Métrica (Metric Instruments)
No Priax, as medições são capturadas por instrumentos de métrica, definidos pelos seguintes atributos:
- Nome
- Tipo
- Unidade (opcional)
- Descrição (opcional)
O nome, a unidade e a descrição são definidos pelo desenvolvedor ou por convenções semânticas para métricas comuns, como requisições e processos.
Os tipos de instrumentos compatíveis incluem:
- Counter: Valor acumulado ao longo do tempo (ex.: um odômetro, que só aumenta).
- Counter Assíncrono: Similar ao Counter, mas coletado uma vez por exportação, útil quando você tem acesso apenas ao valor agregado.
- UpDownCounter: Valor acumulado que pode aumentar ou diminuir (ex.: o tamanho de uma fila).
- UpDownCounter Assíncrono: Similar ao UpDownCounter, mas coletado uma vez por exportação.
- Gauge: Mede um valor atual no momento da leitura (ex.: marcador de combustível de um carro). É síncrono.
- Gauge Assíncrono: Similar ao Gauge, mas coletado uma vez por exportação.
- Histogram: Agrega valores no lado do cliente, como latências de requisições. Útil para estatísticas de valores, como quantas requisições levaram menos de 1s.
Agregação
Além dos instrumentos de métrica, a agregação é um conceito importante. A agregação combina uma grande quantidade de medições em estatísticas exatas ou estimadas sobre eventos de métrica em uma janela de tempo. O protocolo OTLP transporta essas métricas agregadas.
A API do Priax fornece uma agregação padrão para cada instrumento, que pode ser personalizada usando Views. O objetivo do projeto Priax é fornecer agregações padrão que sejam compatíveis com ferramentas de visualização e backends de telemetria.
Diferentemente do rastreamento de requisições, que captura o ciclo de vida de uma requisição, as métricas fornecem informações estatísticas em agregados. Exemplos de uso incluem:
- Total de bytes lidos por um serviço, por tipo de protocolo.
- Total de bytes lidos e bytes por requisição.
- Duração de chamadas de sistema.
- Tamanhos de requisição para identificar tendências.
- Uso de CPU ou memória de um processo.
- Valores médios de saldo em contas.
- Quantidade atual de requisições ativas.
Views
As Views oferecem flexibilidade para personalizar a saída de métricas pelo SDK. É possível:
- Escolher quais instrumentos de métrica serão processados ou ignorados.
- Configurar a agregação e os atributos a serem reportados nas métricas.
Suporte por Linguagem
O suporte às implementações específicas da API e do SDK de Métricas, por linguagem, está conforme a tabela abaixo:
| Linguagem | Status |
| C++ | Estável |
| C#/.NET | Estável |
| Erlang/Elixir | Em desenvolvimento |
| Go | Estável |
| Java | Estável |
| JavaScript | Estável |
| PHP | Estável |
| Python | Estável |
| Ruby | Em desenvolvimento |
| Rust | Beta |
| Swift | Em desenvolvimento |
Logs
Um log é um registro textual com marcação de tempo, podendo ser estruturado (recomendado) ou não estruturado, acompanhado de metadados opcionais. Entre todos os sinais de telemetria, os logs possuem o maior legado, já que a maioria das linguagens de programação inclui capacidades de logging nativas ou bibliotecas amplamente utilizadas.
Logs de Aplicação no Priax
O Priax não define uma API ou SDK específicos para criar logs. Em vez disso, os logs no Priax são aqueles já existentes, oriundos de frameworks de logging ou componentes de infraestrutura. Os SDKs e bibliotecas de instrumentação compatíveis com o Priax e a autoinstrumentação utilizam diversos componentes para correlacionar automaticamente logs com traces.
O suporte da biblioteca de instrumentação Priax para logs é projetado para ser totalmente compatível com sistemas existentes, oferecendo ferramentas para adicionar contexto adicional aos logs e manipulá-los em um formato comum, independentemente da origem.
Nas aplicações, os logs são criados usando qualquer biblioteca ou funcionalidade nativa de logging. Ao adicionar autoinstrumentação ou ativar um SDK de instrumentação compatível com o Priax, os logs são correlacionados automaticamente existentes com quaisquer traces e spans ativos, encapsulando o corpo do log com seus respectivos IDs.
Suporte por Linguagem
As bibliotecas de instrumentação atualmente compatíveis com o Priax suportam o envio de logs para as seguintes linguagens de programação:
| Linguagem | Status |
|---|---|
| C++ | Estável |
| C#/.NET | Estável |
| Erlang/Elixir | Em desenvolvimento |
| Go | Beta |
| Java | Estável |
| JavaScript | Em desenvolvimento |
| PHP | Estável |
| Python | Em desenvolvimento |
| Ruby | Em desenvolvimento |
| Rust | Beta |
| Swift | Em desenvolvimento |
Logs Estruturados, Não Estruturados e Semi-Estruturados
Logs Estruturados
Logs estruturados seguem um formato consistente e legível por máquina, como JSON.
Exemplo em aplicação:
{
"timestamp": "2024-08-04T12:34:56.789Z",
"level": "INFO",
"service": "autenticacao-usuario",
"mensagem": "Login do usuário bem-sucedido",
"contexto": {
"userId": "12345",
"ipAddress": "192.168.1.1"
}
}Logs Não Estruturados
Logs não estruturados não seguem um formato consistente. Apesar de serem mais legíveis para humanos, são difíceis de processar em larga escala.
Exemplo:[ERRO] 2024-08-04 12:45:23 - Falha ao conectar ao banco de dados. Timeout.
Logs Semi-Estruturados
Logs semi-estruturados utilizam padrões consistentes, mas com formatações variadas entre sistemas.
Exemplo:2024-08-04T12:45:23Z level=ERROR service=autenticacao-usuario action=login mensagem="Senha inválida"
Baggage
Informações contextuais propagadas entre sinais.
O Baggage representa informações contextuais que são mantidas junto ao contexto. O Baggage é uma estrutura de chave-valor que permite a propagação de dados arbitrários ao lado do contexto.
Com o Baggage, é possível transmitir dados entre serviços e processos, tornando essas informações acessíveis para serem adicionadas a traces, métricas ou logs nos serviços subsequentes.
Para que serve o Baggage
O Baggage é ideal para incluir informações que estão disponíveis no início de uma requisição, mas que precisam ser acessadas em estágios posteriores. Exemplos incluem:
- Identificação de Contas
- IDs de Usuários
- IDs de Produtos
- IPs de origem
Propagar essas informações usando o Baggage possibilita análises mais detalhadas na telemetria. Por exemplo, incluir um ID de Usuário em um span que monitora uma chamada ao banco de dados facilita responder perguntas como: “Quais usuários estão enfrentando as chamadas mais lentas ao banco de dados?”. Também é possível registrar informações de uma operação downstream e incluir o mesmo ID de Usuário nos dados de log.
Considerações de segurança do Baggage
Itens sensíveis no Baggage podem ser compartilhados com recursos não intencionais, como APIs de terceiros. Isso ocorre porque instrumentações automáticas incluem o Baggage na maioria das requisições de rede do seu serviço.
Especificamente, o Baggage e outras partes do contexto de trace são enviados em cabeçalhos HTTP, ficando visíveis para quem inspecionar o tráfego da rede. Se o tráfego estiver restrito à sua rede interna, esse risco pode não se aplicar, mas é importante lembrar que serviços downstream podem propagar o Baggage para fora da sua rede.
Além disso, não há verificações de integridade embutidas para garantir que os itens do Baggage sejam de sua origem. Por isso, tome cuidado ao acessá-los.
O Baggage não é o mesmo que atributos
Uma diferença importante é que o Baggage é um armazenamento separado de chave-valor, e não está associado diretamente aos atributos de spans, métricas ou logs, a menos que seja adicionado explicitamente.
Para adicionar entradas do Baggage como atributos, é necessário ler os dados do Baggage e incluí-los manualmente como atributos em spans, métricas ou logs.
Como um dos usos comuns do Baggage é adicionar dados como atributos de spans em um trace inteiro, várias linguagens oferecem Baggage Span Processors que automaticamente adicionam dados do Baggage como atributos na criação de spans.
Instrumentação com Bibliotecas OpenTelemetry
O envio de sinais para o Priax pode ser realizado através de instrumentação própria, alterando o código da aplicação a ser observada sem inserir componentes de terceiros à sua infraestrutura. Este processo, no entanto pode ser custoso e levar algum tempo. Para que se possa acelerar esse processo, recomendamos, apesar de não ser a única opção, as bibliotecas e SDKs open-source do OpenTelemetry. Tais bibliotecas seguem os padrões OpenTracing e se tornaram a mais difundida solução de instrumentação para o mercado de Observabilidade.
Como o OpenTelemetry facilita a instrumentação
Para tornar um sistema observável, é necessário instrumentá-lo: ou seja, o código dos componentes do sistema deve emitir traces, métricas e logs.
Com o OpenTelemetry, você pode instrumentar seu código de duas maneiras principais:
-
Soluções baseadas em código
Utilizando APIs e SDKs oficiais disponíveis para a maioria das linguagens de programação. -
Soluções sem código
Ideais para casos em que você não pode ou não deseja modificar o aplicativo que precisa de telemetria.
Soluções baseadas em código
Essas soluções permitem uma telemetria mais profunda e detalhada, gerada diretamente pela sua aplicação. Elas utilizam a API do OpenTelemetry para produzir telemetria personalizada, complementando as informações coletadas por soluções sem código.
Soluções sem código
Perfeitas para começar rapidamente ou quando o aplicativo não pode ser modificado. Essas soluções oferecem uma telemetria rica baseada em bibliotecas utilizadas ou no ambiente em que a aplicação está sendo executada. Elas fornecem dados sobre o que está acontecendo nas "bordas" da aplicação, como interações externas e dependências.
Nota: É possível usar ambas as abordagens ao mesmo tempo para maximizar a observabilidade.
Benefícios adicionais do OpenTelemetry
O OpenTelemetry vai além de oferecer soluções com e sem código. Ele também inclui os seguintes recursos:
- Bibliotecas compatíveis: Bibliotecas podem usar a API do OpenTelemetry como dependência, sem impactar aplicações que não importem o SDK.
- Sinais flexíveis: Para cada tipo de sinal (traces, métricas, logs), existem várias formas de criá-los, processá-los e exportá-los.
- Correlação de sinais: Com a propagação de contexto integrada, é possível correlacionar sinais, independentemente de onde foram gerados.
- Recursos e Escopos de Instrumentação: Permitem agrupar sinais por diferentes entidades, como o host, sistema operacional ou cluster Kubernetes.
- Padrões e especificações: Cada implementação de linguagem do OpenTelemetry segue os requisitos e expectativas definidos pela especificação oficial.
- Convenções semânticas: Fornecem um esquema de nomenclatura comum para padronizar métricas, logs e traces entre diferentes bases de código e plataformas.
Formas de Instrumentação
Instrumentação sem código
A instrumentação sem código adiciona as capacidades da API e SDK do OpenTelemetry à sua aplicação, geralmente por meio de uma instalação de agente ou algo semelhante a um agente. Os mecanismos específicos variam conforme a linguagem, incluindo manipulação de bytecode, monkey patching ou eBPF, para injetar chamadas à API e ao SDK do OpenTelemetry diretamente na aplicação.
Como funciona
Normalmente, a instrumentação sem código adiciona suporte para bibliotecas que sua aplicação utiliza. Isso significa que requisições e respostas, chamadas a bancos de dados, chamadas de filas de mensagens, entre outros, serão instrumentados automaticamente. No entanto, o código da sua aplicação geralmente não é instrumentado. Para isso, é necessário utilizar instrumentação baseada em código.
Além disso, a instrumentação sem código permite configurar as bibliotecas de instrumentação e os exportadores que serão carregados.
Configuração
Você pode configurar a instrumentação sem código por meio de variáveis de ambiente e outros mecanismos específicos da linguagem, como propriedades do sistema ou argumentos passados para métodos de inicialização. Para começar, é necessário apenas configurar o nome do serviço para identificá-lo no backend de observabilidade escolhido.
Outras opções de configuração incluem:
- Configuração específica para fontes de dados.
- Configuração de exportadores.
- Configuração de propagadores.
- Configuração de recursos.
Suporte de linguagens para instrumentação automática
A instrumentação automática está disponível para as seguintes linguagens:
- .NET
- Go
- Java
- JavaScript
- PHP
- Python
Para realizar a instrumentação de sua aplicação, utilizando o método Zero Code, siga as instruções da página do OpenTelemetry.
Instrumentação Baseada em Código
A instrumentação baseada em código permite criar telemetria personalizada diretamente no código da sua aplicação. Abaixo estão os passos essenciais para configurar essa abordagem:
1. Importar a API e o SDK do OpenTelemetry
- Serviços: Dependem da API e do SDK do OpenTelemetry.
- Bibliotecas: Apenas dependem da API.
Para mais detalhes sobre a API e o SDK, consulte a especificação do OpenTelemetry.
2. Configurar a API do OpenTelemetry
-
Fornecedores de Tracer e Meter:
- Crie um TracerProvider para gerar traços.
- Crie um MeterProvider para gerar métricas.
-
Nomeação:
- Use um nome que identifique o componente sendo instrumentado.
- Exemplo: para uma biblioteca, use algo como
com.example.myLibrary. - Inclua uma versão no formato semver (ex.:
semver:1.0.0).
3. Configurar o SDK do OpenTelemetry
- Exportação de dados: Configure o SDK para exportar telemetria a um backend de análise.
- Opções específicas da linguagem: Verifique as opções de ajuste disponíveis para a sua linguagem.
A configuração pode ser feita programaticamente, por meio de arquivos de configuração ou outros mecanismos.
4. Criar Dados de Telemetria
- Traços e Métricas:
- Gere traços e eventos de métricas com os objetos
TracereMeter.
- Gere traços e eventos de métricas com os objetos
- Bibliotecas de Instrumentação:
- Use bibliotecas de instrumentação disponíveis para suas dependências.
- Consulte o repositório ou registro da sua linguagem para obter mais informações.
5. Exportar Dados de Telemetria
- Métodos de Exportação:
-
Exportação no processo:
- Importe e use exportadores para traduzir os objetos de telemetria do OpenTelemetry em formatos apropriados para ferramentas de análise (ex.: Jaeger ou Prometheus).
-
Exportação via OTLP e Collector:
- Use o protocolo OTLP para enviar dados ao OpenTelemetry Collector, que pode atuar como um proxy, sidecar ou processo separado.
- O Collector encaminha os dados para ferramentas de análise.
-
Para realizar a instrumentação de sua aplicação, utilizando o método baseado em código siga as instruções da página do OpenTelemetry.
Instrumentação de Bibliotecas
A instrumentação nativa de bibliotecas com OpenTelemetry oferece uma experiência aprimorada tanto para desenvolvedores quanto para usuários finais, eliminando a necessidade de expor e documentar hooks personalizados. Aqui está como funciona e os benefícios associados:
Como Adicionar Instrumentação Nativa
- Instrumentação via Hooks ou dynamic runtime patching:
OpenTelemetry fornece bibliotecas de instrumentação para várias linguagens, que tipicamente utilizam hooks de bibliotecas ou dynamic runtime patching do código.
Vantagens da Instrumentação Nativa
-
Melhoria na Observabilidade e Experiência do Usuário:
- Remove a necessidade de hooks personalizados, facilitando a integração.
- APIs do OpenTelemetry são fáceis de usar e consistentes para os usuários finais.
-
Telemetria Consistente e Correlação Aprimorada:
- Traços, logs e métricas provenientes do código da biblioteca e da aplicação são correlacionados, criando uma visão coesa dos eventos.
- Convenções comuns garantem uniformidade entre tecnologias, bibliotecas e linguagens.
-
Extensibilidade e Ajustes Fáceis:
- Sinais de telemetria podem ser ajustados (filtrados, processados, agregados) para atender a diferentes cenários de consumo.
- OpenTelemetry oferece extensibilidade bem documentada para personalização.
Para realizar a instrumentação de sua aplicação, utilizando as bibliotecas nativas OpenTelemetry, siga as instruções da página do OpenTelemetry.
Instrumentação com Kubernetes Operator
A instrumentação de aplicações que rodam em workloads Kubernetes é facilitada pelo Opentelemetry Kubernetes Operator que é uma implementação de um Operador Kubernetes que gerencia coletores e a auto-instrumentação das cargas de trabalho usando bibliotecas de instrumentação do OpenTelemetry.
Introdução
O Operador OpenTelemetry é uma implementação de um Operador Kubernetes.
O operador gerencia:
- Coletor OpenTelemetry
- Auto-instrumentação das cargas de trabalho (pods) usando bibliotecas de instrumentação do OpenTelemetry
Início Rápido
Para instalar o operador em um cluster existente, certifique-se de ter o cert-manager instalado e execute:
kubectl apply -f https://github.com/open-telemetry/opentelemetry-operator/releases/latest/download/opentelemetry-operator.yaml
Assim que a implantação do opentelemetry-operator estiver pronta, crie uma instância do Coletor OpenTelemetry (otelcol) como o exemplo abaixo:
kubectl apply -f - <<EOF
apiVersion: opentelemetry.io/v1alpha1
kind: OpenTelemetryCollector
metadata:
name: simplest
spec:
config: |
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
exporters:
# NOTA: Antes da versão v0.86.0, use `logging` ao invés de `debug`.
debug:
service:
pipelines:
traces:
receivers: [otlp]
processors: []
exporters: [debug]
EOFPara mais opções de configuração e para configurar a injeção de auto-instrumentação das cargas de trabalho usando as bibliotecas de instrumentação do OpenTelemetry, continue lendo aqui.
Injeção de Auto-instrumentação
Configurar Instrumentação Automática
Para gerenciar a instrumentação automática, o operador precisa ser configurado para identificar quais pods instrumentar e qual instrumentação automática usar nesses pods. Isso é feito por meio do CRD de Instrumentação.
A criação correta do recurso de Instrumentação é fundamental para que a instrumentação automática funcione. Certifique-se de que todos os endpoints e variáveis de ambiente estejam configurados corretamente.
.NET
O seguinte comando criará um recurso básico de Instrumentação configurado especificamente para serviços .NET:
kubectl apply -f - <<EOF
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: demo-instrumentation
spec:
exporter:
endpoint: http://demo-collector:4318
propagators:
- tracecontext
- baggage
sampler:
type: parentbased_traceidratio
argument: "1"
EOF
Por padrão, o recurso de Instrumentação para serviços .NET usa OTLP com o protocolo HTTP/Protobuf. O endpoint configurado deve ser capaz de receber OTLP via HTTP/Protobuf, como no exemplo: http://demo-collector:4318.
Excluindo bibliotecas de instrumentação
Se você não quiser usar determinadas bibliotecas, configure as variáveis de ambiente OTEL_DOTNET_AUTO_[SIGNAL]_[NAME]_INSTRUMENTATION_ENABLED=false.
Exemplo:
dotnet:
env:
- name: OTEL_DOTNET_AUTO_TRACES_GRPCNETCLIENT_INSTRUMENTATION_ENABLED
value: false
- name: OTEL_DOTNET_AUTO_METRICS_PROCESS_INSTRUMENTATION_ENABLED
value: falseJava
O seguinte comando criará um recurso básico de Instrumentação para serviços Java:
kubectl apply -f - <<EOF
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: demo-instrumentation
spec:
exporter:
endpoint: http://demo-collector:4318
propagators:
- tracecontext
- baggage
sampler:
type: parentbased_traceidratio
argument: "1"
EOFPor padrão, a instrumentação Java usa OTLP com HTTP/Protobuf.
Excluindo bibliotecas de instrumentação
Para desativar bibliotecas específicas:
- Use
OTEL_INSTRUMENTATION_[NAME]_ENABLED=false. - Para desativar todas por padrão e ativar somente algumas:
OTEL_INSTRUMENTATION_COMMON_DEFAULT_ENABLED=false
OTEL_INSTRUMENTATION_[NAME]_ENABLED=trueConfigurar Instrumentação Automática
Para gerenciar a instrumentação automática, o operador precisa ser configurado para identificar quais pods instrumentar e qual instrumentação automática usar nesses pods. Isso é feito por meio do CRD de Instrumentação.
A criação correta do recurso de Instrumentação é fundamental para que a instrumentação automática funcione. Certifique-se de que todos os endpoints e variáveis de ambiente estejam configurados corretamente.
.NET
O seguinte comando criará um recurso básico de Instrumentação configurado especificamente para serviços .NET:
Por padrão, o recurso de Instrumentação para serviços .NET usa OTLP com o protocolo HTTP/Protobuf. O endpoint configurado deve ser capaz de receber OTLP via HTTP/Protobuf, como no exemplo: http://demo-collector:4318.
Excluindo bibliotecas de instrumentação
Se você não quiser usar determinadas bibliotecas, configure as variáveis de ambiente OTEL_DOTNET_AUTO_[SIGNAL]_[NAME]_INSTRUMENTATION_ENABLED=false.
Exemplo:
Java
O seguinte comando criará um recurso básico de Instrumentação para serviços Java:
Por padrão, a instrumentação Java usa OTLP com HTTP/Protobuf.
Excluindo bibliotecas de instrumentação
Para desativar bibliotecas específicas:
Node.js
O seguinte comando criará um recurso básico de Instrumentação para serviços Node.js:
kubectl apply -f - <<EOF
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: demo-instrumentation
spec:
exporter:
endpoint: http://demo-collector:4317
propagators:
- tracecontext
- baggage
sampler:
type: parentbased_traceidratio
argument: "1"
EOFPor padrão, a instrumentação Node.js usa OTLP com gRPC.
Gerenciar bibliotecas de instrumentação
- Para ativar bibliotecas específicas:
nodejs:
env:
- name: OTEL_NODE_ENABLED_INSTRUMENTATIONS
value: http,nestjs-core- Para desativar específicas:
nodejs:
env:
- name: OTEL_NODE_DISABLED_INSTRUMENTATIONS
value: fs,grpcPython
O seguinte comando criará um recurso básico de Instrumentação para serviços Python:
kubectl apply -f - <<EOF
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: python-instrumentation
spec:
exporter:
endpoint: http://demo-collector:4318
propagators:
- tracecontext
- baggage
sampler:
type: parentbased_traceidratio
argument: "1"
EOFPor padrão, Python usa OTLP com HTTP/Protobuf.
Logs em Python
Para ativar a instrumentação automática de logs:
python:
env:
- name: OTEL_PYTHON_LOGGING_AUTO_INSTRUMENTATION_ENABLED
value: 'true'Excluindo bibliotecas de instrumentação
Defina OTEL_PYTHON_DISABLED_INSTRUMENTATIONS com os pacotes a serem excluídos.
Go
Para serviços Go, crie o recurso básico de Instrumentação:
kubectl apply -f - <<EOF
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: demo-instrumentation
spec:
exporter:
endpoint: http://demo-collector:4318
propagators:
- tracecontext
- baggage
sampler:
type: parentbased_traceidratio
argument: "1"
EOFA instrumentação Go usa um agente eBPF em um sidecar, que requer permissões elevadas.
Adicione anotações para ativar a instrumentação automática:
instrumentation.opentelemetry.io/inject-go: 'true'
instrumentation.opentelemetry.io/otel-go-auto-target-exe: '/path/to/executable'Habilitar Instrumentação Automática
Adicione anotações ao seu deployment para ativar a instrumentação automática:
- .NET:
instrumentation.opentelemetry.io/inject-dotnet: "true" - Java:
instrumentation.opentelemetry.io/inject-java: "true" - Node.js:
instrumentation.opentelemetry.io/inject-nodejs: "true" - Python:
instrumentation.opentelemetry.io/inject-python: "true" - Go:
instrumentation.opentelemetry.io/inject-go: "true"
Ingestão de Dados e Backend de Armazenamento
O Priax suporta diferentes backends de armazenamento para Traces, Logs e Métricas coletados e podendo trabalhar com Opensearch, ou Elasticsearch. Para que os dados sejam injetados nessas bases de dados, utilizamos o OpenTelemetry Collector, e pode ser combinado ou não com outras tecnologias de transporte e transformação de dados como o Data Prepper e o Kafka.
Apresentaremos aqui os conceitos básicos do Collector e cenários práticos de implantação para utilização destas tecnologias com o Priax.
Data Collector
O Collector oferece uma implementação independente de fornecedor para receber, processar e exportar dados de telemetria. Ele elimina a necessidade de operar e manter múltiplos agentes/coletores. O Collector funciona com escalabilidade aprimorada e suporta formatos de dados de observabilidade de código aberto (por exemplo, Jaeger, Prometheus, Fluent Bit, etc.), enviando para um ou mais backends de código aberto ou comerciais. O agente Collector local é o destino padrão para o qual as bibliotecas de instrumentação exportam seus dados de telemetria.
Objetivos
- Usabilidade: Configuração padrão prática, suporta protocolos populares, funciona e coleta dados imediatamente.
- Desempenho: Altamente estável e eficiente sob diferentes cargas e configurações.
- Observabilidade: Um exemplo de serviço observável.
- Extensibilidade: Personalizável sem necessidade de alterar o código principal.
- Unificação: Base de código única, implantável como agente ou coletor, com suporte para rastros, métricas e logs.
Em abbientes de desenvolvimento ou testes e para ter resultados rápido com a observabilidade de maneira pontual é possível enviar seus dados diretamente de sua aplicação para um backend. Em ambientes de produção, no entanto, recomendamos usar um coletor junto com seus serviços, pois ele permite que o serviço descarregue dados rapidamente, realize cache quando necessário e, além disso, o coletor pode lidar com tarefas adicionais, como tentativas de reenvio, agrupamento, criptografia ou até mesmo filtragem de dados sensíveis.
O Collector facilita a unificação de dados, visto que suporta diversas formas de ingestão (Receivers) e diversas formas de exportação de dados (Exporters). Abaixo podemos ver como o Collector trabalha e como ele pode ser utilizado para enviar dados para os Backends de Armazenamento compatíveis com o Priax.
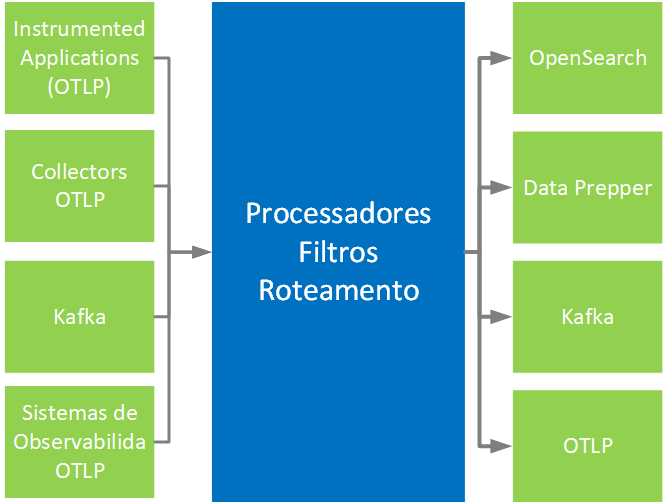
Como se pode observar o Collector pode receber dados diretamente das aplicações instrumentadas, de outros sistemas de observabilidade como o Prometheus ou o Jaeger mas também pode receber dados de outros Collectors ou buscar dados em sistemas Kafka, que podem ter sido alimentados por outros Collectors. Dessa forma pode-se criar um layout de implantação flexível onde os Collectors podem atuar como gateways concentradores ou como agentes de simples transmissão de dados para os BackEnds de Armazenamento. Para enviar dados para o Backend de armazenamento compatível com o Priax (Opensearch) o Collector pode ou não utilizar o Data Prepper (ver abaixo as informações sobre o DataPrepper).
Para compreender mais sobre os layouts de implantação do Data Collector, consulte a página do OpenTelemetry que trata sobre o assunto.
Instalação e Configuração dos Collectors
A instalação dos Collectors é relativamente simples e pode ser realizada diretamente sobre os sistemas operacionais Windows ou Linux ou ainda utilizando Docker ou Kubernetes. As instruções para instalação podem ser consultadas na página de instalação do Collector do OpenTelemetry.
A Configuração completa do Collector pode ser consultada na extensa documentação fornecida pelo OpenTelemetry porém aqui apresentamos alguns cenários tipicamente utilizados.
Configuração do Collector para uso com e sem Data Prepper
receivers:
otlp:
protocols:
http:
#include_metadata: true
cors:
allowed_origins: ["http://*"]
allowed_headers: ["*"]
#max_age: 7200
#endpoint: 127.0.0.1:4318
kafka:
protocol_version: 3.3.0
group_id: priaxapm1
encoding: otlp_proto
brokers:
- priax-teste-01.servicebus.windows.net:9093
topic: priax
auth:
sasl:
username: $$ConnectionString
password: Endpoint=sb://kafkaAzure.servicebus.windows.net/;SharedAccessKeyName=teste-priax;SharedAccessKey=z5kREHICeAw0EEMySt7cP2kgh4XGb/zh4+AEhMe7r0g=;EntityPath=priax
mechanism: PLAIN
tls:
insecure: true
processors:
batch: {}
tail_sampling/priax:
decision_wait: 40s
policies:
- name: sample-ottl
type: ottl_condition
ottl_condition:
span:
- "status.code == 2 and attributes[\"lime.envelope.type\"] == nil"
- "status.code == 2 and attributes[\"lime.envelope.type\"] != nil and attributes[\"lime.envelope.type\"] != \"Notification\""
- "end_time - start_time > Duration(\"29s\")"
- "attributes[\"sample.force\"] == true"
- name: probabilistic-policy
type: probabilistic
probabilistic:
hash_salt: "custom-salt"
sampling_percentage: 0.1
k8sattributes:
extract:
metadata:
- k8s.namespace.name
- k8s.deployment.name
- k8s.statefulset.name
- k8s.daemonset.name
- k8s.cronjob.name
- k8s.job.name
- k8s.node.name
- k8s.pod.name
- k8s.pod.uid
- k8s.pod.start_time
passthrough: false
pod_association:
- sources:
- from: resource_attribute
name: k8s.pod.ip
- sources:
- from: resource_attribute
name: k8s.pod.uid
- sources:
- from: connection
memory_limiter:
check_interval: 5s
limit_percentage: 80
spike_limit_percentage: 25
resource:
attributes:
- action: insert
from_attribute: k8s.pod.uid
key: service.instance.id
exporters:
debug:
verbosity: detailed
otlp/data-prepper:
endpoint: data-prepper:21890
tls:
insecure: true
opensearch:
http:
endpoint: https://opensearchserver:9200
auth:
authenticator: basicauth/client
extensions:
health_check:
pprof:
zpages:
endpoint: ":55679"
basicauth/client:
client_auth:
username: ingester
password: ingesterpass
service:
extensions: [health_check, pprof, zpages]
pipelines:
traces:
receivers: [otlp]
processors: [k8sattributes,memory_limiter,resource,batch,tail_sampling/priax]
exporters: [debug,opensearch]
metrics:
receivers: [otlp]
processors: [k8sattributes,memory_limiter,resource,batch]
exporters: [debug,opensearch]
logs:
receivers: [otlp]
processors: [k8sattributes,memory_limiter,resource,batch]
exporters: [debug,opensearch]
traceswithKafkaandDataprepper:
receivers: [kafka]
processors: [k8sattributes,memory_limiter,resource,batch]
exporters: [debug,otlp/dataprepper]
metricswithKafkaandDataprepper:
receivers: [kafka]
processors: [k8sattributes,memory_limiter,resource,batch]
exporters: [debug,otlp/dataprepper]
logswithKafkaandDataprepper:
receivers: [kafka]
processors: [k8sattributes,memory_limiter,resource,batch]
exporters: [debug,otlp/dataprepper]Amostragem de Traces e Spans
É importante perceber que a configuração acima define que serão enviadas ao Backend de Armazenamento o 0,1% das spans coletadas pela instrumentação. Isso se dá nos trechos destacados abaixo:
[...]
processors:
[...]
tail_sampling/priax:
decision_wait: 40s
policies:
- name: sample-ottl
type: ottl_condition
ottl_condition:
span:
- "end_time - start_time > Duration(\"29s\")"
- "attributes[\"sample.force\"] == true"
- name: probabilistic-policy
type: probabilistic
probabilistic:
hash_salt: "custom-salt"
sampling_percentage: 0.1
[...]
pipelines:
traces:
receivers: [otlp]
processors: [k8sattributes,memory_limiter,resource,batch,tail_sampling/priax]
# Para não utilizar o sampling neste pipeline basta rever o processador tail_sampling/priax desta seção.
exporters: [debug,opensearch]
traces:
receivers:
- kafka
processors:
- batch
- tail_sampling/priax
exporters:
- otlp/data-prepper
[...]Para que sejam enviados 100% dos traces para o Backend de Armazenamento, remova a configuração de sampling do pipeline desejado conforme comentado no exemplo acima.
Data Prepper
Data Prepper
O Data Prepper é um componente da infraestrutura do Opensearch. É um coletor de dados do lado do servidor, capaz de filtrar, enriquecer, transformar, normalizar e agregar dados para análise e visualização posteriores. É a ferramenta de ingestão de dados preferida para o OpenSearch, recomendada para a maioria dos casos de uso de ingestão de dados no OpenSearch, especialmente para o processamento de conjuntos de dados grandes e complexos.
Com o Data Prepper, você pode criar pipelines personalizados para melhorar a visão operacional de suas aplicações. Dois casos de uso comuns do Data Prepper são a análise de rastros (trace analytics) e a análise de logs (log analytics). A análise de rastros ajuda a visualizar fluxos de eventos e identificar problemas de desempenho. Já a análise de logs oferece ferramentas para aprimorar as capacidades de busca, realizar análises detalhadas e obter insights sobre o desempenho e o comportamento das suas aplicações.
Conceitos-chave e fundamentos
O Data Prepper processa dados por meio de pipelines personalizáveis. Esses pipelines são compostos por componentes modulares que podem ser ajustados para atender às suas necessidades, inclusive permitindo a integração de implementações próprias. Um pipeline do Data Prepper consiste nos seguintes componentes:
- Uma fonte (source)
- Um ou mais destinos (sinks)
- (Opcional) Um buffer
- (Opcional) Um ou mais processadores (processors)
Cada pipeline contém dois componentes obrigatórios: a fonte e o destino. Se um buffer, um processador, ou ambos estiverem ausentes do pipeline, o Data Prepper usará o buffer padrão bounded_blocking e um processador no-op. É importante observar que uma única instância do Data Prepper pode conter um ou mais pipelines.
O uso do Data Prepper com o Priax, facilita a adoção de padrões do Opensearch e é altamente recomendável.
Instalação do Data Prepper
A instalação do Data Prepper é relativamente simples e sua documentação pode ser consultada diretamente na página do OpenSearch.
Configurações básicas de pipeline
A configuração básica do Data Prepper para uso com o Priax pode ser vista abaixo:
entry-pipeline:
delay: "100"
source:
otel_trace_source:
ssl: false
buffer:
buffer_size: 10240
batch_size: 160
sink:
- pipeline:
name: "raw-trace-pipeline"
- pipeline:
name: "service-map-pipeline"
raw-trace-pipeline:
source:
pipeline:
name: "entry-pipeline"
buffer:
bounded_blocking:
buffer_size: 10240
batch_size: 160
processor:
- otel_trace_raw:
sink:
- stdout: null
- opensearch:
hosts: ["http://opensearchserver:9200"]
username: ingester
password: passwordingester
max_retries: 20
bulk_size: 4
insecure: true
index_type: trace-analytics-raw
service-map-pipeline:
delay: "100"
source:
pipeline:
name: "entry-pipeline"
buffer:
bounded_blocking:
buffer_size: 10240
batch_size: 160
processor:
- service_map_stateful:
sink:
- stdout: null
- opensearch:
hosts: ["http://opensearchserver:9200"]
username: ingester
password: passwordingester
max_retries: 20
bulk_size: 4
insecure: true
index_type: trace-analytics-service-mapVisualização de Dados de Aplicações
Conceitos Essenciais
O Priax oferece os recursos visuais para analisar o desempenho, a estrutura, as dependências de aplicações. Para que se possa compreender essas telas é importante entender alguns conceitos iniciais.
| Conceito | Descrição |
| Serviço | Os serviços são os blocos de construção das arquiteturas modernas de microserviços. Em termos gerais, um serviço agrupa endpoints, consultas ou tarefas com o objetivo de construir o aplicativo. Em aplicações mais antigas, um serviço representa uma porção lógica da aplicação que desempenha uma porção de trabalho delimitável da aplicação. |
| Transação | Representam um trecho de código delimitado sendo executado dentro de um serviço. Tal trecho de código pode ser o atendimento de usuários remotos através de um socket de rede (por exemplo um servidor Web atendendo a um usuário), a execução de uma lógica ou função interna para montar a resposta para esse usuário ou a conexão à serviços de rede externos para coletar dados ou informações necessárias. |
| Indicadores/Métricas | Métricas APM funcionam como métricas regulares, mas com controles específicos para o APM. Use essas métricas para receber alertas no nível do serviço sobre acessos, erros e diversas medidas de latência. |
| Trace | Um trace é usado para rastrear o tempo gasto por um aplicativo processando uma solicitação e o status dessa solicitação. Cada trace consiste de um ou mais spans. |
| Instrumentação | Instrumentação é o processo de adicionar código ao seu aplicativo para capturar e relatar dados de observabilidade. |
Explorando Serviços, Traces e Transações
Depois de instrumentar serviços e ativar o discovery de transações no Priax, os serviços serão populados com as transações que estão sendo executadas pelas aplicações e suas interações com usuários e demais sistemas com os quais trocam informações. No Priax, um serviço pode ser representado por um Container (oriundos de sistemas Docker ou similares), um Deplyment, Statefulset, Daemonset (esses três últimos componentes de um cluster Kubernetes) ou ainda por aplicações hospedadas em servidores de aplicação ou interpretadores de linguagens (java, .net, php, ruby, perl, pyton, etc).
Abaixo podemos ver um exemplo de Deployment de um cluster Kubernetes com as transações executadas dentro de seus Pods. Neste caso o Deployment representa o Serviço da aplicação instrumentada.

Para ver o mapa de um serviço instrumentado, basta selecioná-lo e no canto superior direito do painel da esquerda acessar suas dependências no botão  .
.
.

Nesta tela é exibido o mapa de dependências do Serviço. Podemos visualizar tanto os componentes internos das aplicações, representados por transações quanto os componentes da infraestrutura que suportam essas transações, como bases de dados e a estrutura do Kubernetes. Ao selecionar uma Transação, são exibidas à direita os gráficos de Time Series dos indicadores e métricas que são gerados ao longo do tempo como a média de tempo de execução, taxa de erros e taxa de transferência de dados.

Ao selecionar uma operação na árvore, abaixo são exibidas os detalhes das transações e clicando na aba Transactions você pode filtrar o tempo de exibição que deseja para visualizar as ocorrências quando aquela operação foi executada pela aplicação.

Desta fora são exibidas todas execuções da operação ocorridas naquele período de tempo.
No ícone  , podemos personalizar a janela de tempo que será exibida. Podemos também dar zoom-in e zoom-out ao longo do tempo para poder ter mais detalhes das execuções da transação. As barras que representam cada execução fornecem informações importantes sobre o tempo que levou cada execução. Barras mais longas foram as execuções que mais demoraram, e o tempo de execução pode ser visto passando o mouse em cima de cada execução, o que nos fornece outras informações como ID da Span e do Trace.
, podemos personalizar a janela de tempo que será exibida. Podemos também dar zoom-in e zoom-out ao longo do tempo para poder ter mais detalhes das execuções da transação. As barras que representam cada execução fornecem informações importantes sobre o tempo que levou cada execução. Barras mais longas foram as execuções que mais demoraram, e o tempo de execução pode ser visto passando o mouse em cima de cada execução, o que nos fornece outras informações como ID da Span e do Trace.
Ao clicar em uma das execuções podemos explorar todo o Trace da qual a execução da Transação faz parte e assim podemos compreender exatamente como transcorreu aquela execução, como foi chamada, por qual transação e o que ocorreu com aquela chamada de sistema como um todo.
O gráfico de Destacado em vermelho, acima, mostra a linha de tempo e a relação pai-filho entre as spans (execuções da transação) e o gráfico em verde, mostra como o tempo foi percentualmente distribuído entre as spans pai e filho de cada trace.
Clicando em cada span em qualquer um dos gráficos, é possível ver os detalhes de cada execução, incluindo logs e parâmetros de execução.
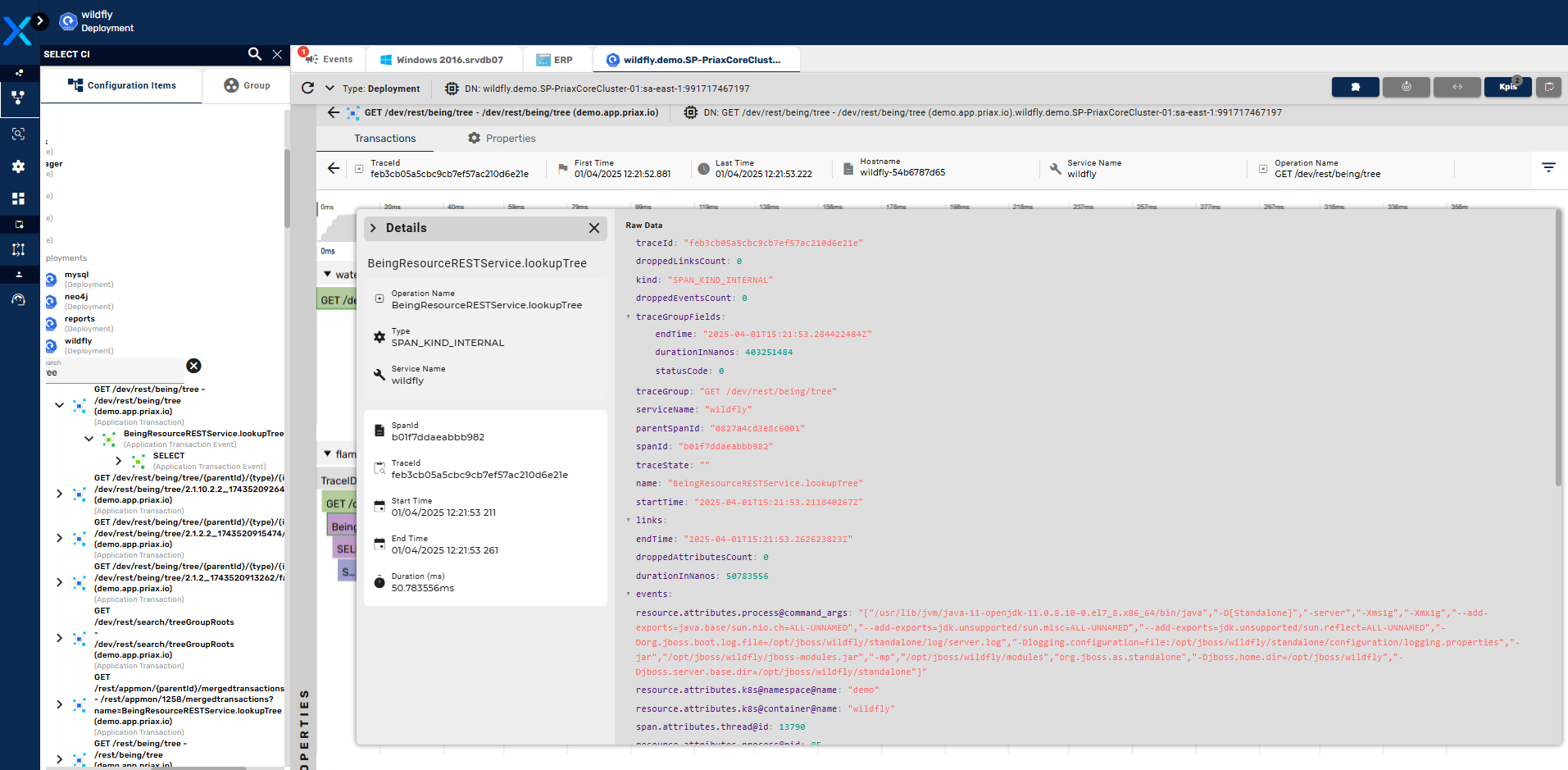
As métricas para cada transação tal como: tempo médio Latency (ou Avg Transaction Time), Número de execuções por período (Calls), taxa de erros por período (Error Tax), são exibidas no painel da direita, além de diversos dashboards com será demonstrado nesse documento.
Dentre as diversas tipos de transações que o Priax consegue detectar e analisar, exibir estatísticas, gráfcos e realizar drill down , além de produzir eventos e alertas estão:
- Transações de Servidor HTTP, gRPC, RPC,
- Transações internas (trechos de código que são executados internamente na aplicação, sem interação externa)
- Chamadas de Web Services para outros sistemas, estejam eles instrumentados ou não;
- Consultas à bancos de dados relacionais e não relacionais;
- Produção e consumo em sistemas de mensagens e filas como Kafka e RabbitMQ;
- Dados produzidos pelo navegador, coletado diretamente o comportamento do usuário.
Os indicadores tradicionalmente coletadas para cada Transação são:
- Média de Tempo de Execução ao longo do tempo para 5, 10 e 15 minutos.
- Média de Taxa de erros de execução ao longo do tempo para 5, 10 e 15 minutos.
- Média de taxa de transferência de dados para 5, 10 e 15 minutos.
No entanto as métricas podem ser customizadas para cada caso.
Detectando problemas em Transações
Ao detectar um problema, que pode ser pela detecção de limites auto-calculados o Priax realiza, com a utilização de técnicas de análise de dados e machine learning, uma análise profunda de causa raiz, diferenciando os indicadores que representam um sintoma dos indicadores que de fato estão causando o problema, e unificando isso em um único Evento.
A partir do momento que um novo evento é detectado e sua causa raiz isolada, ele pode ser direcionado para a equipe e indivíduo correto, podendo ele realizar análise das correlações dos indicadores e itens de configuração envolvidos no Evento.
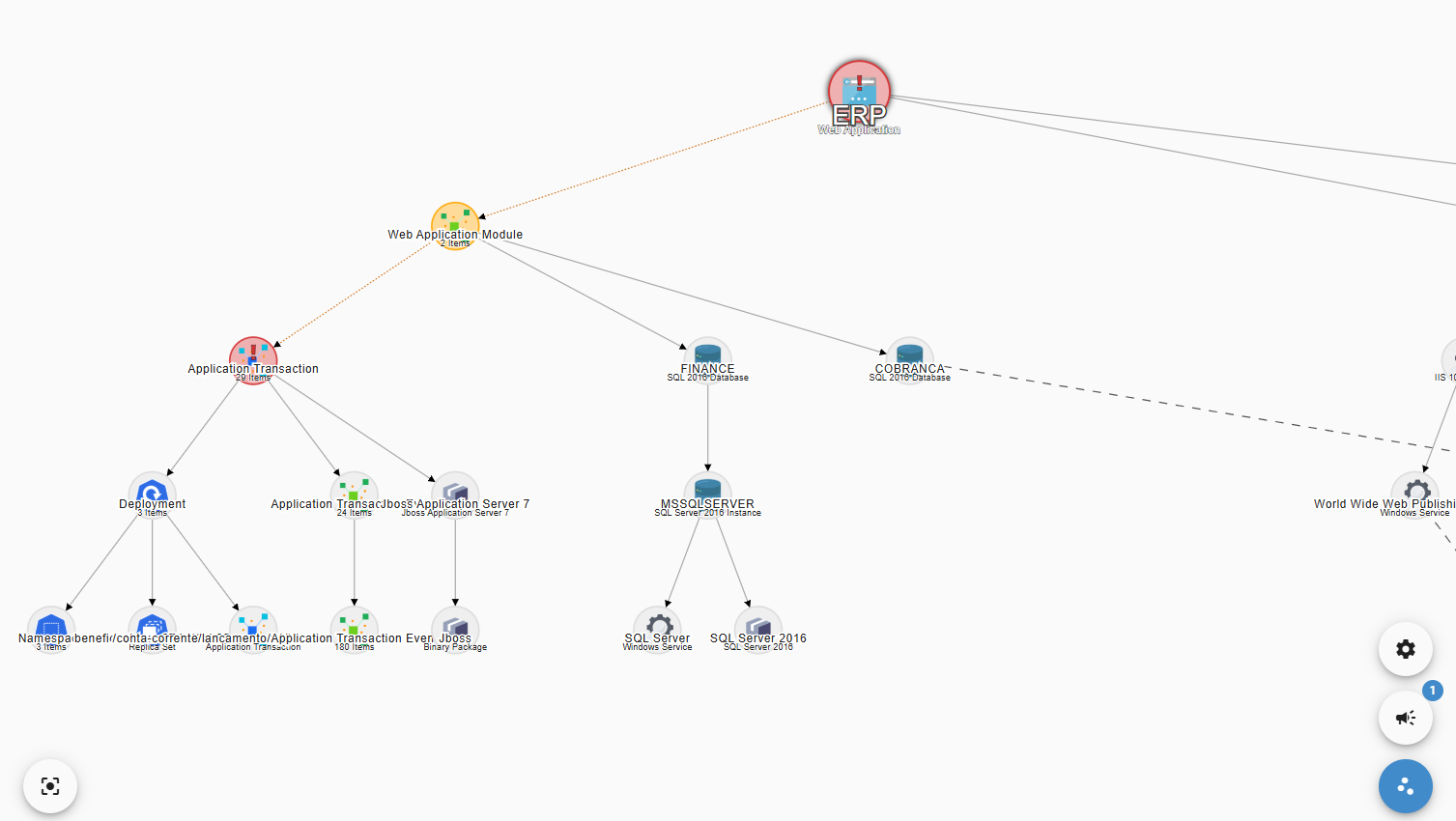
Ao receber um evento, você pode realizar a análise de impactos e de dependências da Transação causa-raiz do evento, o que nos permite entender quais outras Transações, Serviços e Aplicações estão sendo afetadas pelo problema. Ao analisar as dependências, também podemos detectar indicadores de infraestrutura que podem estar causando indiretamente o Evento.
Sempre que um Evento é criado são realizadas as análises que evitam a duplicação de eventos, criação de falsos positivos e a criação de eventos isolados quando esses possuem a mesma causa raíz. Para tal o Priax realiza:
- Identificação de Indicadores correlacionados na mesma árvore de Causa-Efeito: Este procedimento garante que apenas um evento seja criado quando múltiplas transações dependentes entre sí, ou ainda recursos que sustentam essas transações estejam reportando comportamento anormal. Neste caso o Item de Configuração ou transação de mais baixo nível na árvore de causa-efeito será a eleito como causa raíz, e todos os demais itens impactados serão reportados como impactos neste mesmo evento.
- Análise flapping: Utilizada para indicadores com alternância constante entre estados, evitando a criação de eventos múltiplos para o mesmo indicador causa-raiz.
As trigger para disparo de Eventos podem ser configuradas manualmente ou ainda podem ser calculadas baseadas nos dados históricos com técnicas de Análise de Dados e Machine Learning.
Na tela acima, de edição do Indicador é possível habilitar o aprendizado de Triggers, definir se os limites deverão ser abaixo, acima ou abaixo e acima da normalidade, definir se haverá um perfil diferente de trigger por dia da semana e por horário, além de definir qual será o menor nível de alerta que será gerado pelas trigger automaticamente aprendidas.
Para saber mais sobre o Gerenciamento de Eventos, consulte o capítulo específico sobre Gerenciamento de Operações e Eventos neste manual.
APM Dashboards
Após instrumentar uma aplicação ou serviço e coletar métricas, traces e logs é possível no Priax criar painéis e relatórios a respeito de Transações ocorridas dentro de cada Serviço da Aplicação. Ao longo do tempo, com a execução continuada das transações, são produzidos dados Time Series com os indicadores relevantes a respeito de cada transação, como por exemplo:
- Média de Tempo de Execução ao longo do tempo para 5, 10 e 15 minutos.
- Média de Taxa de erros de execução ao longo do tempo para 5, 10 e 15 minutos.
- Média de taxa de transferência (throughput) de dados para 5, 10 e 15 minutos.
Tais dados podem ser visualizados em Dashboards customizados agregados por:
- Aplicações: Conjunto de Serviços que são agrupados logicamente formando a Aplicação.
- Serviços; Componente instrumentado e identificado com o mesmo nome de Serviço.
- EndPoints: Todo o destino de conexão identificado pelo conjunto de transações executadas em determinado período de tempo.
- Transação: Cada operação identificada por um nome na instrumentação realizada.
Abaixo pode ser visualizado um exemplo de Dashboard que apresenta dados sobre as Transações executadas ao londo de determinado período. Os Dashboards podem ser acessados através do ícone destacado na barra de ícones da esquerda na imagem abaixo.
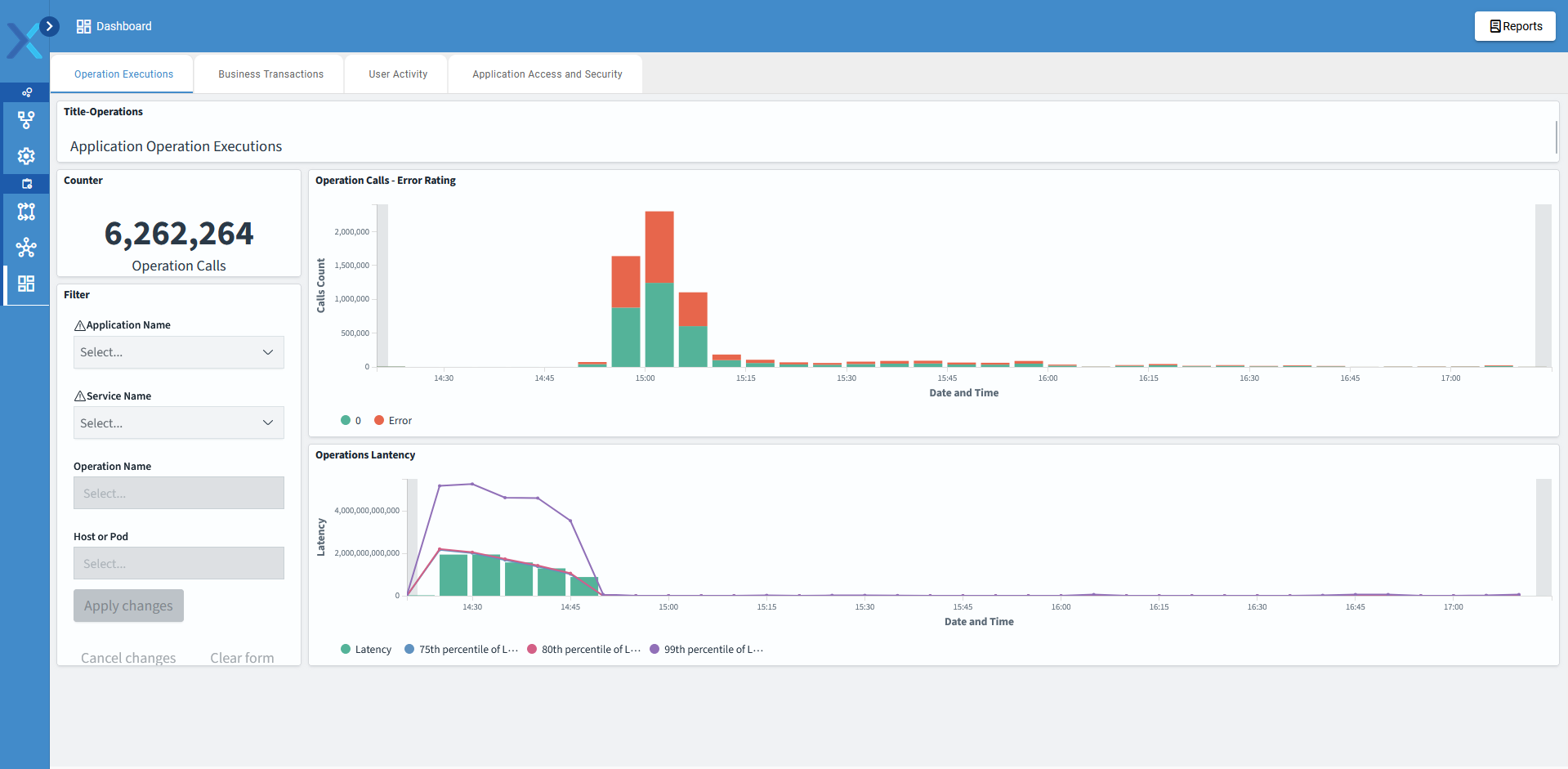
Na tela acima são exibidos de acordo com o Número destacado:
- Tela de Filtros: Os filtros podem ser aplicados para definir quais Transações serão considerados no Dashboard. Neste dashboard de exemplo, foram adicionados componentes para que se possa filtrar por Aplicação, Serviço, Transação e Host que executou a transação. É possível, no entanto, filtrar por qualquer Atributo presente nas Spans, como por exemplo, por qualquer campo que represente um endpoint ou pelo tipo de operação realizada.
- Gráfico que exibe a taxa de execução e de erros ocorrida nas transações filtradas em cada período de tempo.
- Gráfico que exibe latência média e nos percentis 75 e 99 para cada período de tempo.
Todas os dashboards podem ser filtrados ao nível de Transação específica, podendo exibir dados dos seguintes tipos de transações entre outros:
- Transações de Servidor HTTP, gRPC, RPC: Contendo os endereços, métodos e detalhes da requisição realizada.
- Transações internas (trechos de código que são executados internamente na aplicação, sem interação externa): Contendo informações sobre o código executado, linguagem, versões, etc.
- Chamadas de Web Services para outros sistemas, estejam eles instrumentados ou não: Contendo os detalhes sobre a requisição http realizada.
- Consultas à bancos de dados relacionais e não relacionais: Contendo as consultar realizadas (Statement SQL) anonimizadas, a base de dados consultada, o endereço dos servidores consultados, etc.
- Produção e consumo em sistemas de mensagens e filas como Kafka e RabbitMQ: Contendo o nome dos tópicos os métodos de consumo e demais informações sobre o consumo ou produção nesses sistemas.
- Dados produzidos pelo navegador, coletado diretamente o comportamento do usuário: Contendo o detalhes sobre o User Agent (navegador) utilizado, ip, nome do usuário quando aplicável.
Os dashboards são completamente customizáveis, podendo receber novos componentes, filtros, gráficos e layout de exibição. Novos dashboards podem ser criados e publicados, criando novas abas de exibição no topo da tela de dashboards exibida na tela acima.
Gestão de Operações e Eventos (ITOM)
Introdução à Gestão de Eventos
O Priax possui a funcionalidade de gestão de eventos que permite que fatos relevantes do ambiente sejam direcionados às Equipes e pessoas adequadas baseado em diversas características do evento que podem influenciar em quem deve ser notificado em cada situação.
Tipos de Eventos
O Priax possui a capacidade de detectar, classificar, filtrar e notificar os seguintes tipos de eventos do ambiente de TI:
- Eventos de Disponibilidade: Recursos que entram em situação de indisponibilidade, deixando de cumprir seu papel no ambiente de TI.
- Eventos de Capacidade: Recursos que operam em regime precário, podendo representar ineficiência ou falhas eventuais devido à sobrecarga ou falta de recursos de hardware ou má configuração.
- Eventos de Mudança: Mudanças em configurações sem prévio conhecimento.
- Logs: Logs que representam a necessidade de atenção por parte de alguma equipe de operação.
Fluxo da Gestão de Eventos no Priax
O Priax realiza desde a detecção do evento, com agentes próprios ou integrado à ferramentas de terceiros capazes de capturar eventos nos recursos gerenciados, até a gestão pós-mortem destes eventos. Ao detectar eventos, o Priax realiza uma série de atividades até que sejam efetivamente notificados às equipes interessadas. As principais fases da gestão de eventos são:
Monitoramento Contínuo
Os sistemas de TI são monitorados constantemente por ferramentas que coletam dados de logs, métricas, transações e outros sinais emitidos por servidores, aplicativos, redes e dispositivos.
Detecção de Eventos Relevantes
Nem todos os eventos detectados são significativos. O processo de detecção inclui filtros para diferenciar eventos importantes (como erros críticos) de eventos rotineiros. Este processo inclui a filtragem de eventos de acordo com os parâmetros selecionados pelos usuários do Priax, além de mecanismos de detecção de falsos positivos e atenuação de pequenas oscilações normais do ambiente. Nesta fase também são realizadas os cálculos estatísticos e utilização de dados históricos para cálculo gatilhos de anormalidade com técnicas de machine learning.
Classificação do Evento
Eventos detectados são classificados por sua criticidade (information, warning, average, critical ou down) e priorizados com base no impacto potencial no ambiente. Também são calculados os SLAs com base nos serviços impactados.
Correlação de Eventos
O Priax utiliza IA e machine learning para correlacionar eventos aparentemente desconexos e identificar padrões, ajudando a prever problemas antes que ocorram. A correlação de eventos é o processo de identificar relações entre eventos aparentemente independentes para determinar uma causa raiz ou padrão subjacente. Em ambientes complexos, muitos eventos isolados podem ser sintomas do mesmo problema.
Técnicas de Correlacionamento:
- Coleta Centralizada: Eventos são reunidos em uma plataforma central (como um SIEM ou ferramenta de monitoramento).
- Análise Temporal: Eventos ocorrendo em curtos períodos de tempo podem ser correlacionados.
- Reconhecimento de Padrões: Ferramentas usam algoritmos (ou mesmo IA) para identificar padrões comuns que indicam incidentes recorrentes.
- Modelagem de Dependências: Mapas de dependências entre sistemas ajudam a correlacionar eventos com base na hierarquia ou comunicação entre componentes.
Identificação de Impactos de Eventos
Dado um evento, devidamente correlacionado e identificado sua causa-raiz, o Priax realiza a análise de impactos, identificando, baseado nas dependências presentes na CMDB, a análise de quais os recursos, aplicações e serviços afetados pelo evento, permitindo. Isso permite que se tenha imediatamente uma análise da gravidade do evento e que se ajuste o SLA do evento baseado nos impactos gerados pelo evento.
Seleção de Responsáveis por Eventos
Com as informações de causa-raiz e impatos, é possível então definir os responsáveis por agir e mitigar as consequências do evento. Para isso o Priax possui regras que podem definir baseado em:
- Horário de ocorrência do evento
- Causa raiz e tipos de causa raiz (tipo de IC e grupos de tipo de IC)
- Impactos
- Tags
- Host e Grupos de Host
Notificações do Evento
O Priax possui aplicativo próprio para gestão dos eventos, capaz de receber notificações em celular ou em aplicativo Windows. No entanto o Priax também é capaz de notificar usando SMS, Whatsapp, Telegram, Microsoft Teams.
Post-Mortem do Evento
O processo de post-mortem de um evento é uma prática essencial para analisar incidentes críticos ocorridos em ambientes de TI, com o objetivo de entender o que aconteceu, identificar a causa raiz e implementar ações para evitar a recorrência. Ele é parte integrante de uma cultura de aprendizado contínuo e melhoria, especialmente em equipes que seguem metodologias como DevOps, SRE (Site Reliability Engineering), ou ITIL.
O Priax oferece ferramentas para realização completa do processo de Post-Mortem de um evento tais como:
-
Registro do Incidente
- Documentar o incidente de forma detalhada, incluindo:
- Data e hora do início e fim.
- Serviços ou sistemas afetados.
- Impacto no negócio ou nos usuários.
- Integração com Ferramentas de ITSM (ServiceNow, Jira, Helix, OTRS)
- Documentar o incidente de forma detalhada, incluindo:
-
Linha do Tempo do Incidente
- Reconstituir uma timeline detalhada do incidente:
- O que aconteceu e quando.
- Quem fez o quê.
- Como o incidente foi detectado.
- Ferramentas de logs e monitoramento podem ajudar a criar uma visão cronológica.
- Reconstituir uma timeline detalhada do incidente:
-
Identificação da Causa Raiz
- Usar técnicas como:
- 5 Porquês (5 Whys): Perguntar repetidamente "Por quê?" até chegar à causa raiz.
- Análise de Árvore de Falhas: Diagramar as falhas e suas inter-relações.
- Diferenciar entre causas imediatas (sintomas) e causas profundas.
- Usar técnicas como:
-
Avaliação da Resposta ao Incidente
- Avaliar como a equipe respondeu:
- O que funcionou bem (boas práticas)?
- Onde houve falhas no processo ou demora na resolução?
- Identificar gaps em alertas, playbooks ou habilidades da equipe.
- Avaliar como a equipe respondeu:
-
Ações Corretivas e Preventivas
- Propor ações concretas para evitar a repetição do problema, como:
- Melhorias em configurações ou infraestrutura.
- Atualizações em playbooks ou runbooks.
- Revisão de SLAs e práticas de monitoramento.
- Treinamentos para a equipe.
- Propor ações concretas para evitar a repetição do problema, como:
-
Compartilhamento do Relatório
- Documentar o post-mortem em um relatório claro e objetivo, incluindo:
- Descrição do incidente.
- Linha do tempo.
- Causa raiz.
- Impacto.
- Lições aprendidas.
- Ações corretivas e preventivas.
- Compartilhar com todas as partes interessadas para alinhamento.
- Documentar o post-mortem em um relatório claro e objetivo, incluindo:
Seleção e Customização de ICs e Indicadores a serem Observados
O Priax, ao detectar um IC automaticamente habilita os indicadores que são selecionados como indicador padrão do IC. Porém, podemos customizar, habilitar ou desabilitar o monitoramento de qualquer indicador de qualquer IC, conforma a necessidade de cada situação.
Habilitando e desabilitando Indicadores
Para isso, na tela principal do Priax, podemos navegar na árvore de ICs, selecionar o item desejado e na aba Indicadores selecionar ou deselecionar os indicadores desejados.
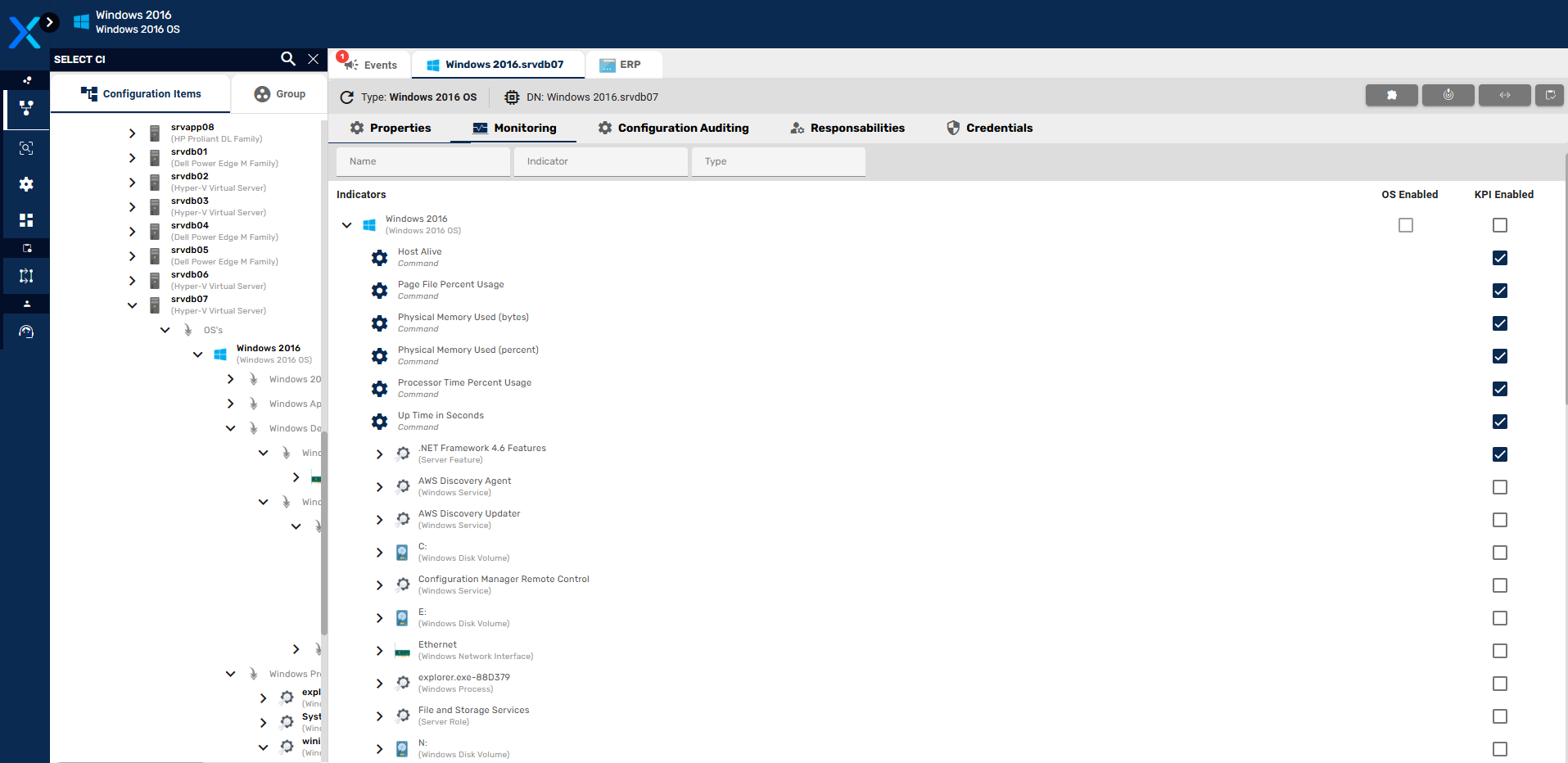
Customização de Indicadores
Para customizar o indicador, pode-se clicar no ícone no indicador do IC desejado. Será exibida a tel abaixo:
Ao passar o mouse em cada uma das opções, as instruções de preenchimento serão exibidas, com uma pequena documentação individual por atributo.
Definindo Triggers estáticas
Triggers são os limites que podem ser definidos para que, ao coletar os valores de um indicador, o Priax avalie se deve ou não gerar um evento e seus respectivos alertas e notificações. Para definir estaticamente esses limites customize vá para a aba Thresholds.
Configure os limites conforme seu desejo:
- Warning Threshold: Primeiro limite que pode ser ativado.
- Average Threshold: Segundo nível de criticidade de alerta que pode ser ativado.
- Urgent Threshold: Terceiro e mais crítico nível de alerta que pode ser ativado.
Esses três níveis de alerta podem ser utilizados no atributo Check Parameters para que sejam efetivamente utilizados
Habilitando o Cálculo de automático de Triggers (Linha Base)
O Priax suporta a geração de alertas baseado em cálculo automatizado de linha base. Para que os indicadores passem a gerar alertas sem a necessidade de explicitar os limites fixos você pode habilitar o cálculo de trigger baseado em histórico.
Para isso localize a opção Learn "Triggers based on History" na tela de configuração do indicador e habilite essa opção. Depois configure as opções conforme descrito abaixo.
- Triggers Profile: Selecione se as triggers devem ser calculadas para limites superiores, inferiores ou para ambos. Quando um indicador cuja a normalidade fica abaixo dos valores que podem causar problemas, então selecione a opção Upper Limits. Para indicador cuja a normalidade se situa acima de valores que podem causar problemas, selecione Botton Limits. E para indicador cuja a normalidade não pode se afastar de uma média, selecione Upper and Botton Limits.
- Weekday Profile: Selecione True se você deseja ter um cálculo de trigger diferenciado para dia da semana.
- Time Profile: Selecione True se você deseja ter um cálculo de trigger diferenciado para cada horário do dia.
- Minimum Trigger Level: Selecione o nível mínimo de trigger que será criado para o indicador. Se você selecionar High, apenas um nível de trigger será calculado. Se você selecionar Average, serão criados dois níveis e se você selecionar Warning serão criados três níveis.
- Time Window: Selecione quanto tempo de dados serão considerados para criar as triggers, as opções são: 24 horas, 7 dias, 30 dias, 180 dias, 365 dias.
Importante, os indicadores serão coletados pelos PPA Agents. Eles devem ser instalados conforme explicado em seção específica deste manual.
Criação do Indicador no Discovery
O Priax pode auto-habilitar um indicador para um Item de Configuração quando ele for descuberto pelo processo de Discovery. Para isso, basta editar o tipo de IC, navegando na árvore de categorias (Grupos) de ICs, selecionar a aba "KPI's Default Values".
Localize o Indicador desejado e clique em Configurar no indicador desejado.
Na primeira opção "Enable on CI Creation" selecione a opção "True".
Criação de Regras de Reação
Recepção e Tratamento de Eventos
Acesso e Instalação ao Priax ITOM
Os eventos no Priax são recebitos e gerenciados no módulo Priax ITOM, que é uma aplicação Web integrada ao Priax, porém também possui interface através de aplicativo instalável em sistemas operacionais Android e IOS. A aplicação pode ser instalada também em Sistemas operacionais Windows e Linux através do navegador de sua preferência.
Para acessar o Priax ITOM através de seu navegador acesse: https://itom.app.priax.io.
Ao acessar, antes mesmo de fazer login, é apresentado na barra de endereços um ícone:

Este ícone (pode variar um pouco de navegador para navegador) permite a instalação da aplicação no sistema operacional. Durante o processo de instalação o usuário é questionado se deseja criar os ícones na barra de tarefas e na área de trabalho.
Em celulares, o procedimento é bastante parecido. porém a opção de instalação aparece no menu do navegador:
A instalação deverá criar os ícones da aplicação nos locais tradicionais do seu sistema operacional.
Tela inicial do Priax ITOM
Ao acessar a aplicação, serão exibidas as Equipes que seu usuário faz parte, com o respectivo quadro de atividades:
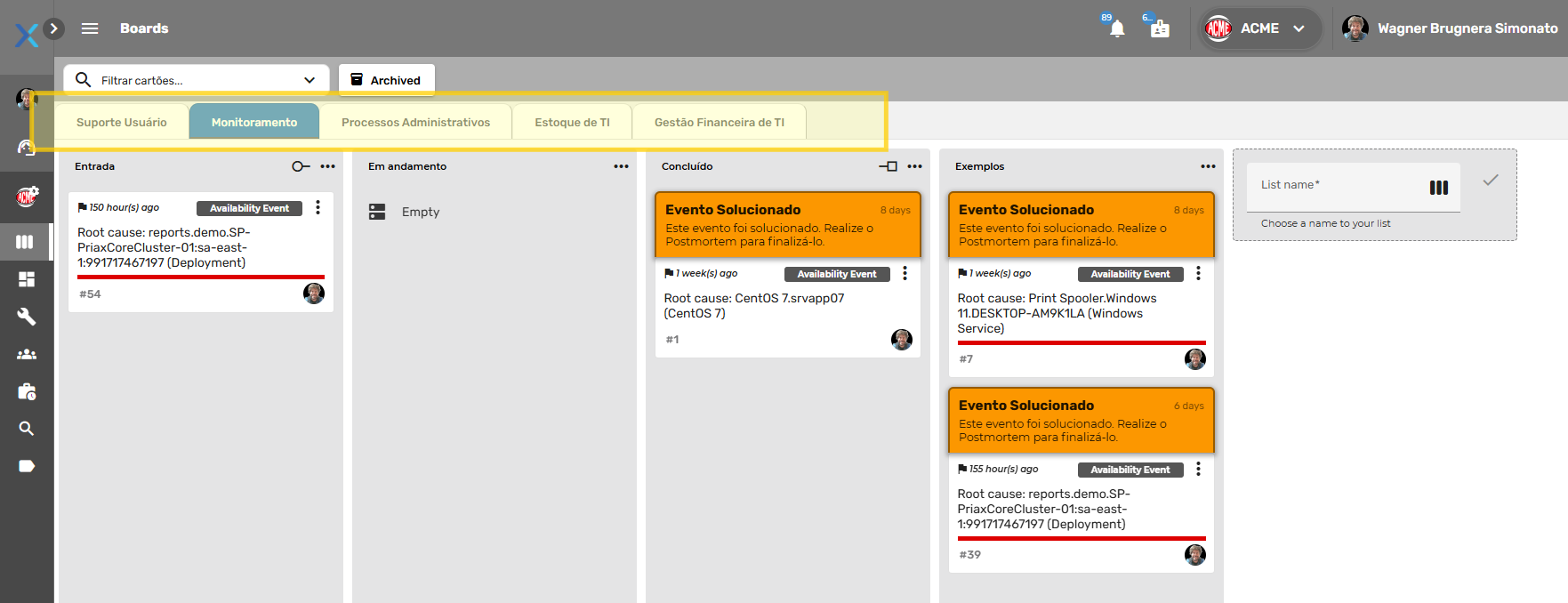
Cada aba da imagem acima representa uma equipe que pode receber Eventos. Cada equipe pode organizar seu trabalho criando estágios do gerenciamento dos eventos, no entanto a coluna Entrada e Concluído representam respectivamente o estado que onde serão criados os eventos e para onde serão movidos quando forem solucionados/encerrados.
Ao clicar em um evento, os detalhes sobre ele serão exibidos.
Gerenciamento de Eventos
Ao clicar em um evento a tela de detalhes de eventos é exibida, onde se pode ver informações detalhadas e gerenciar o evento:
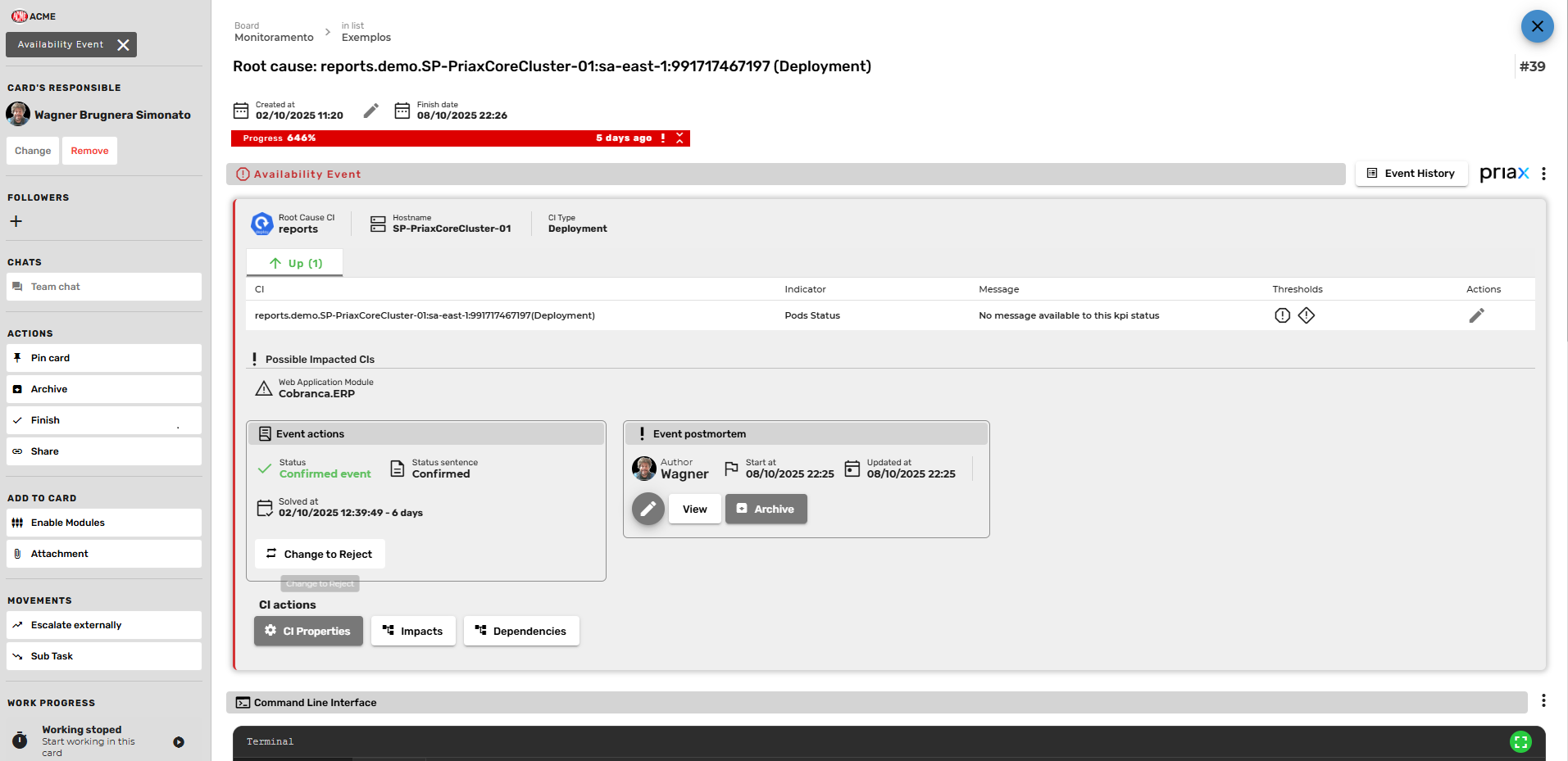
- Causa raiz do evento, sendo que qualquer recurso ou indicador correlacionado, sempre terá sido causado por este elemento.
- Todos os recursos (ICs) e respectivos indicadores nos quais foram detectados anormalidades, e que foram causados pela mesma causa raiz. Nesta área são apresentados também os indicadores da própria causa raíz.
- Os indicadores são apresentados em abas que representam o nível de gravidade que os indicadores atingiram, indicadores com o mesmo nível de gravidade detectados são agrupados na mesma aba.
- Detalhes do IC que causou o problema e navegar nos impactos gerados por ele, visualizando os indicadores que apresentam problemas nessas árvores de impacto e dependências.
- Gráfico de cada indicador ao longo do tempo.
Análise de Impactos
No botão "Impacts" podemos ver os impactos de um evento:
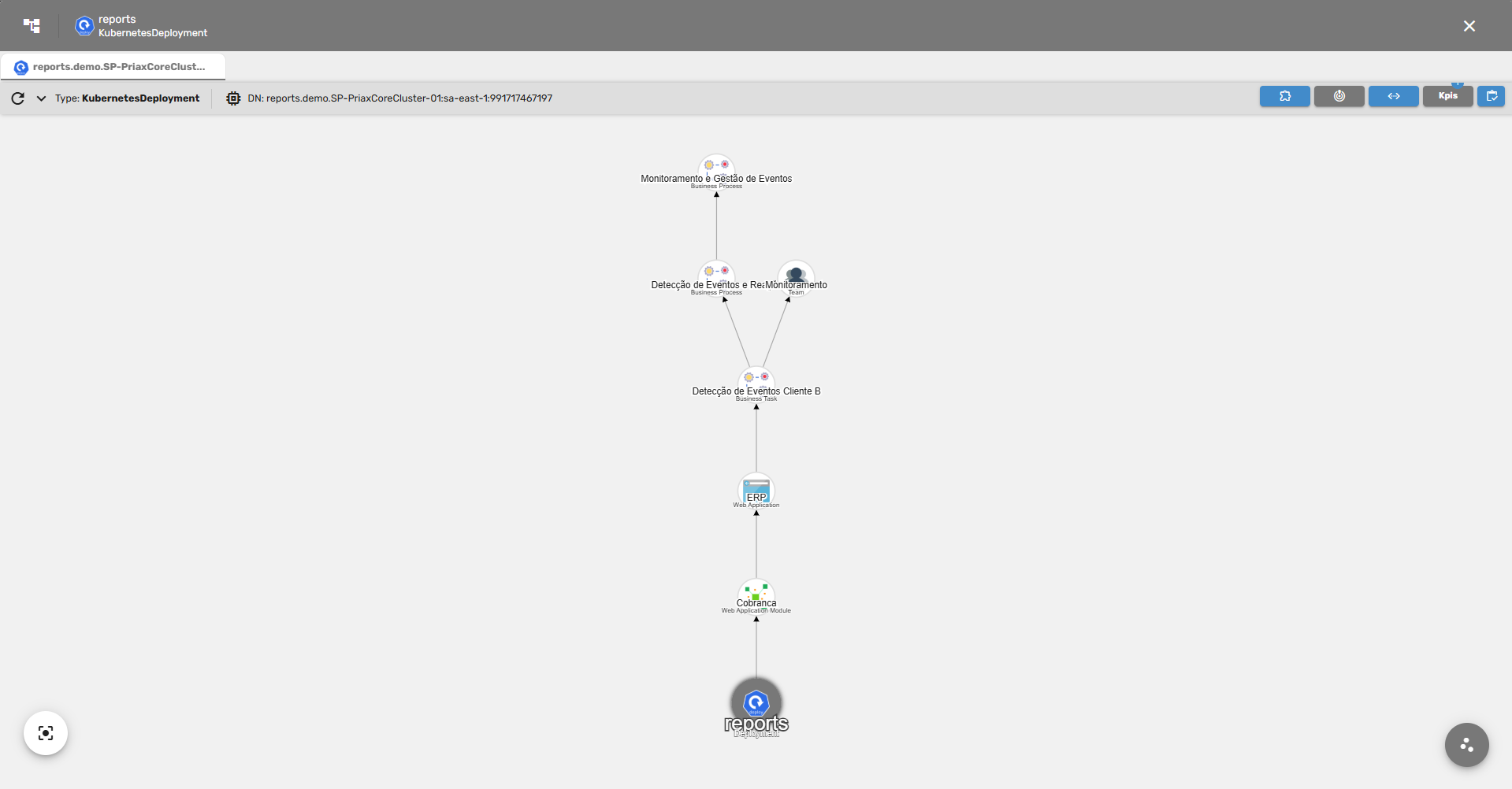
Nesta tela é possível visualizar todos os indicadores eferados. Os recursos (ICs) que são afetados com o problema (mesmo que ainda não possuam indicadores em estado de alerta). Os ICs para os quais foram detectados indicadores que confirmam o impacto são pintados de vermelho e ao clicar neles pode-se ver os indicadores afetados. Quando o indicador de um IC pode ser causado pelo de outro, apenas um Evento é criado, função essa da fase de correlação de eventos.
Análise de Dependências
Da mesma forma que podemos ver os impactos de um evento, podemos ver também de quais outros recursos depende um IC que é a causa raiz de um evento. Nesta análise de causa dependências são exibidos ICs que estão em estado saudável e também ICs que podem estar sendo afetados por outros Eventos, porém que não foram correlacionados por se tratarem de eventos de outras naturezas. Essa análise pode ajudar a entender mais profundamente um problema e como corrigi-lo.
Visualização de Histórico de Indicadores
No item 5 da tela de visualização de detalhes do evento, ou diretamente nos detalhes do indicador na tela de análise de impactos e de dependências, pode-se visualizar o histórico de qualquer indicador relacionado a qualquer IC ou dos indicadores associados ao evento.
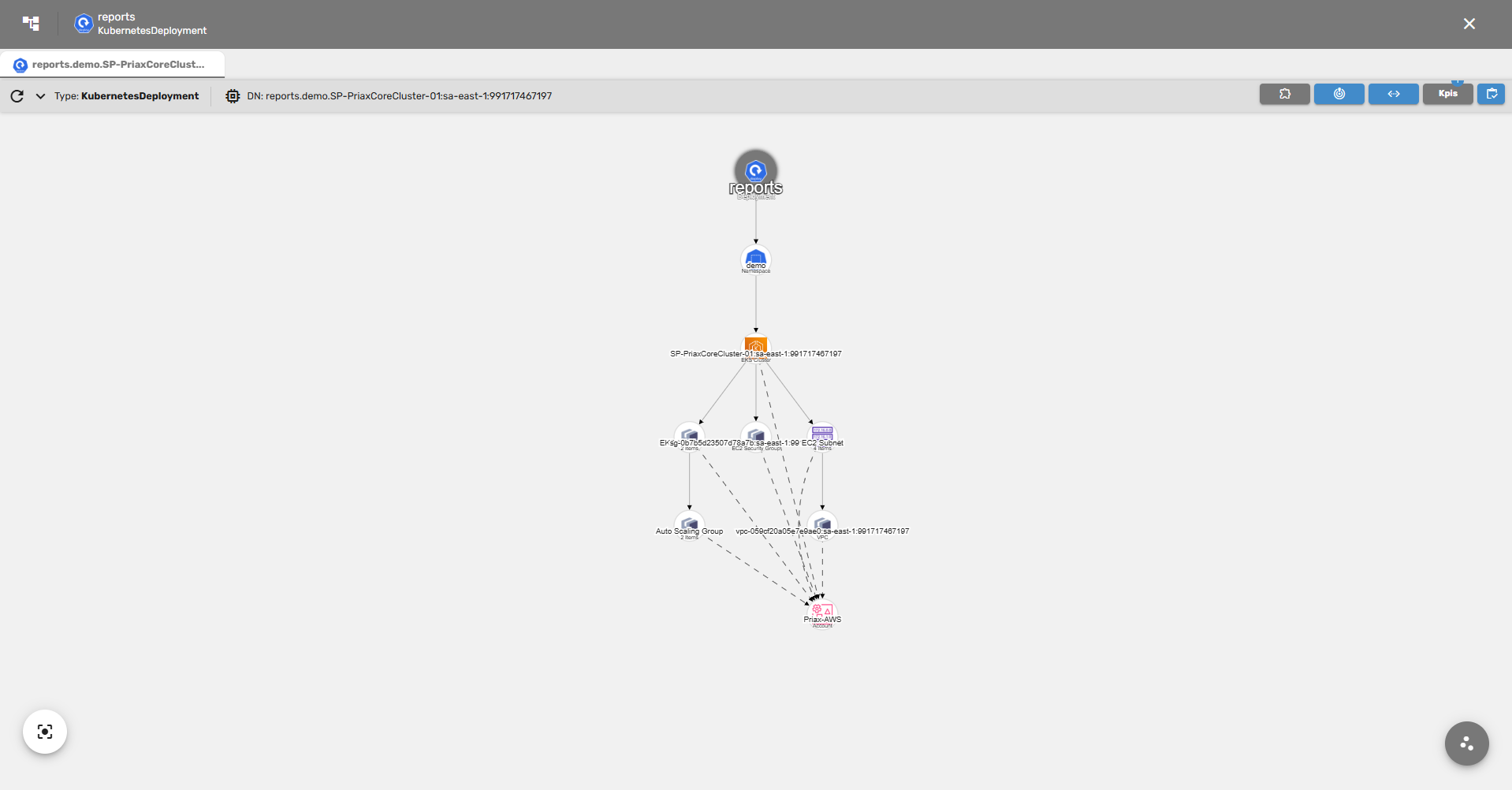
Nesta tela pode-se navegar no dado coletado, realizando zoom-in ou zoon-out em qualquer período de tempo, que também pode ser customizado no botão "Filters".
Gestão de Equipes e Usuários
Criação de Equipes
Para criar uma equipe no Priax ITOM, você pode utilizar o botão "Add" no canto superior direito dos Boards, na tela principal.
Criação de Usuários
Para criar usuários, precisamos convidá-los para o uso do sistema. Para isso, utilize o menu lateral, clicando no ícone de configuração de seu Local (Empresa):  . Apõs clicar no ícone, navegue no menu para "Team".
. Apõs clicar no ícone, navegue no menu para "Team".
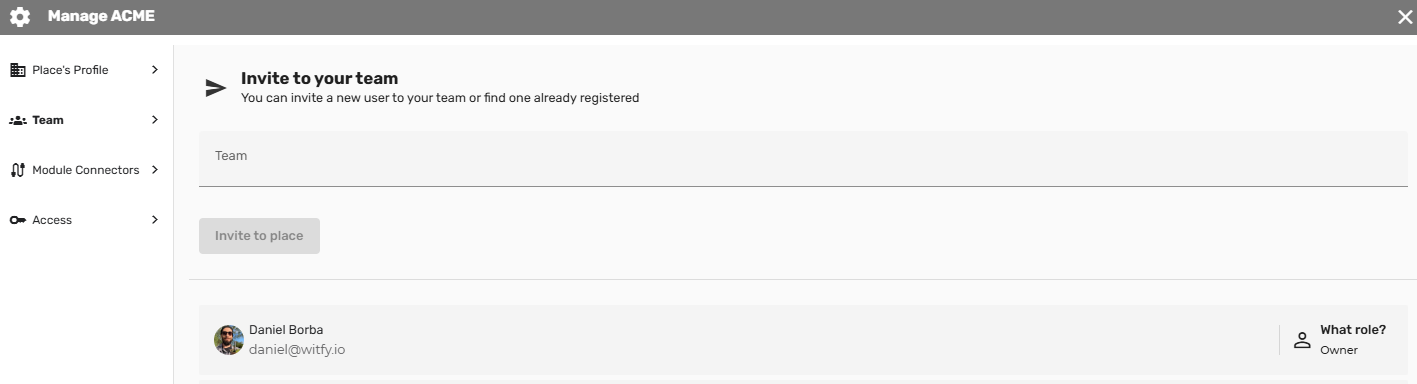
E finalmente para convidar um usuário, preencha o email do usuário e clique em "Invite to Place".
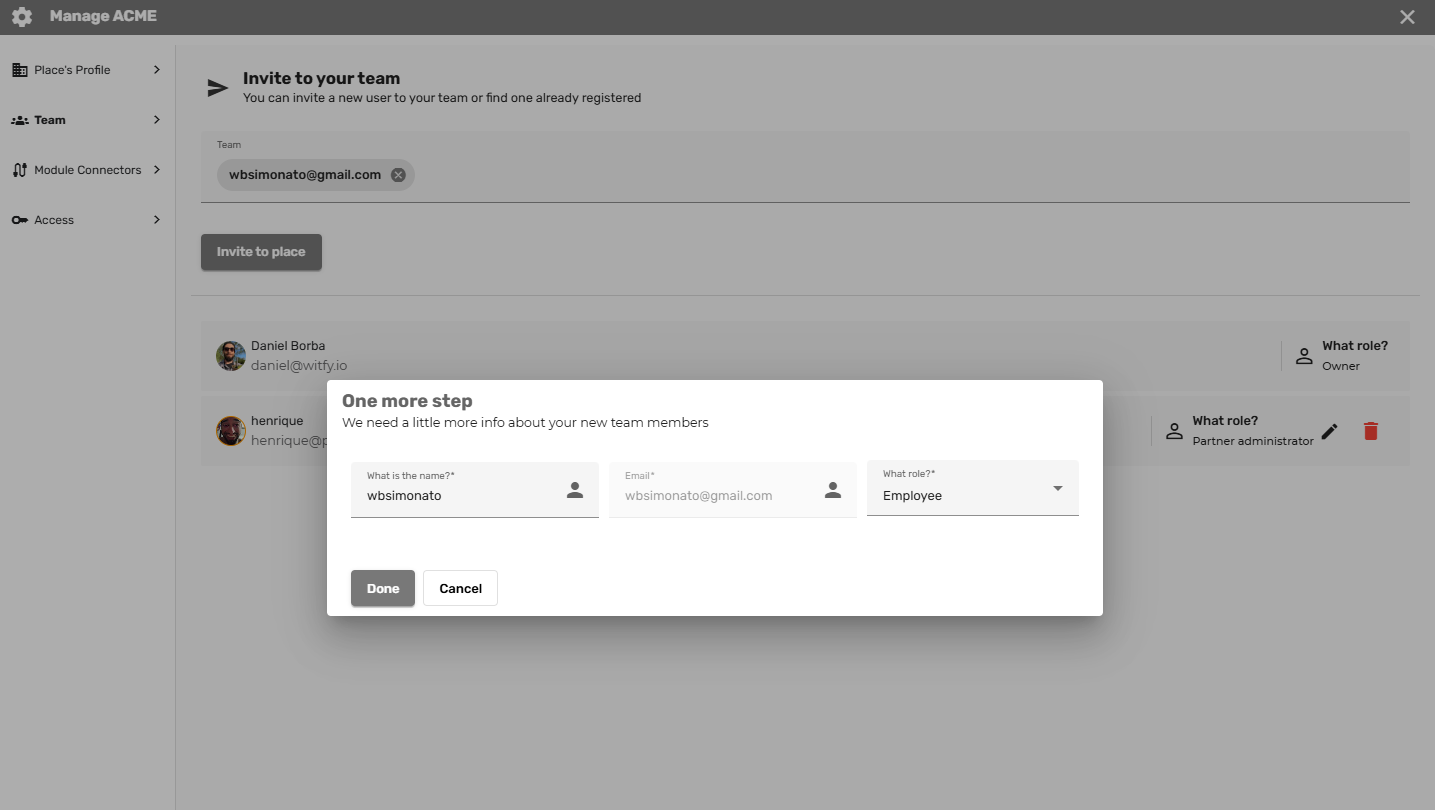
Selecione o Role adequado para o usuário:
- Partner Administrator: Pode administrar todos os aspectos do local como o Nome, Logotipo, criar equipes, associar módulos., adicionar usuários e atribuir qualquer tipo de role..
- Administrator: Pode criar equipes, organizar os quadros e criar usuários dos perfis Administrator e Employees.
- Employee: Pode gerenciar as demandas que das equipes para as quais forem atribuídos.
O usuário receberá em seu email um Link para acesso á ferramenta. Caso o email seja vinculado à uma conta Microsoft ou do Microsoft Entra Domain Services, ele pode utilizar seu login integrado para realizar o acesso à ferramenta. Caso o email inserido seja de uma conta não vinculada à essas ferramentas, então ele deverá criar sua senha de Acesso ao Priax ITOM.
Atribuição de Usuários à Equipes
Para atribuir usuários às equipes, basta navegar até o Board da equipe nas abas do topo superior da ferramenta:

Na equipe na qual se deseja adicionar o usuário, expanda as configurações da equipe no ícone  no canto direito do Board da equipe.
no canto direito do Board da equipe.
No sinal + você pode adicionar os usuários à equipe, como Manager ou como Worker do Board. Além de gerenciar os cards e demandas, os Managers podem reorganizar os quadros, mudar ordem das colunas, atribuir novos Usuários e gerenciar os responsáveis de todos os cartões do Board.