Visialização de Dados de Aplicações
Conceitos Essenciais
O Priax oferece os recursos visuais para analisar o desempenho, a estrutura, as dependências de aplicações. Para que se possa compreender essas telas é importante entender alguns conceitos iniciais.
| Conceito | Descrição |
| Serviço | Os serviços são os blocos de construção das arquiteturas modernas de microserviços. Em termos gerais, um serviço agrupa endpoints, consultas ou tarefas com o objetivo de construir o aplicativo. Em aplicações mais antigas, um serviço representa uma porção lógica da aplicação que desempenha uma porção de trabalho delimitável da aplicação. |
| Transação | Representam um trecho de código delimitado sendo executado dentro de um serviço. Tal trecho de código pode ser o atendimento de usuários remotos através de um socket de rede (por exemplo um servidor Web atendendo a um usuário), a execução de uma lógica ou função interna para montar a resposta para esse usuário ou a conexão à serviços de rede externos para coletar dados ou informações necessárias. |
| Indicadores/Métricas | Métricas APM funcionam como métricas regulares, mas com controles específicos para o APM. Use essas métricas para receber alertas no nível do serviço sobre acessos, erros e diversas medidas de latência. |
| Trace | Um trace é usado para rastrear o tempo gasto por um aplicativo processando uma solicitação e o status dessa solicitação. Cada trace consiste de um ou mais spans. |
| Instrumentação | Instrumentação é o processo de adicionar código ao seu aplicativo para capturar e relatar dados de observabilidade. |
Explorando Serviços, Traces e Transações
Depois de instrumentar serviços e ativar o discovery de transações no Priax, os serviços serão populados com as transações que estão sendo executadas pelas aplicações e suas interações com usuários e demais sistemas com os quais trocam informações. No Priax, um serviço pode ser representado por um Container (oriundos de sistemas Docker ou similares), um Deplyment, Statefulset, Daemonset (esses três últimos componentes de um cluster Kubernetes) ou ainda por aplicações hospedadas em servidores de aplicação ou interpretadores de linguagens (java, .net, php, ruby, perl, pyton, etc).
Abaixo podemos ver um exemplo de Deployment de um cluster Kubernetes com as transações executadas dentro de seus Pods. Neste caso o Deployment representa o Serviço da aplicação instrumentada.
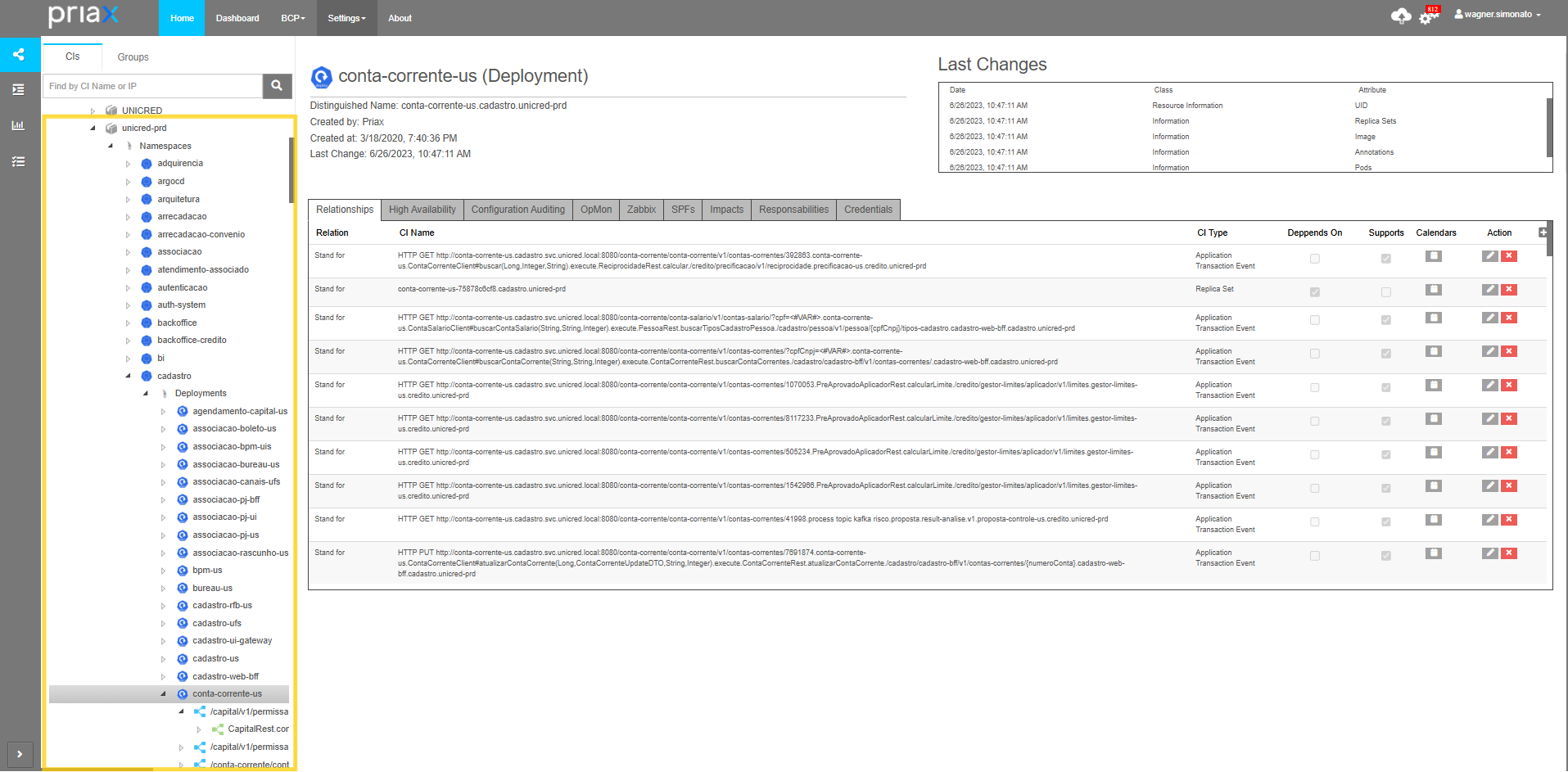
Para ver o mapa de um serviço instrumentado, basta clicar com o botão direito sobre ele e selecionar CI Reports\Dependencies.
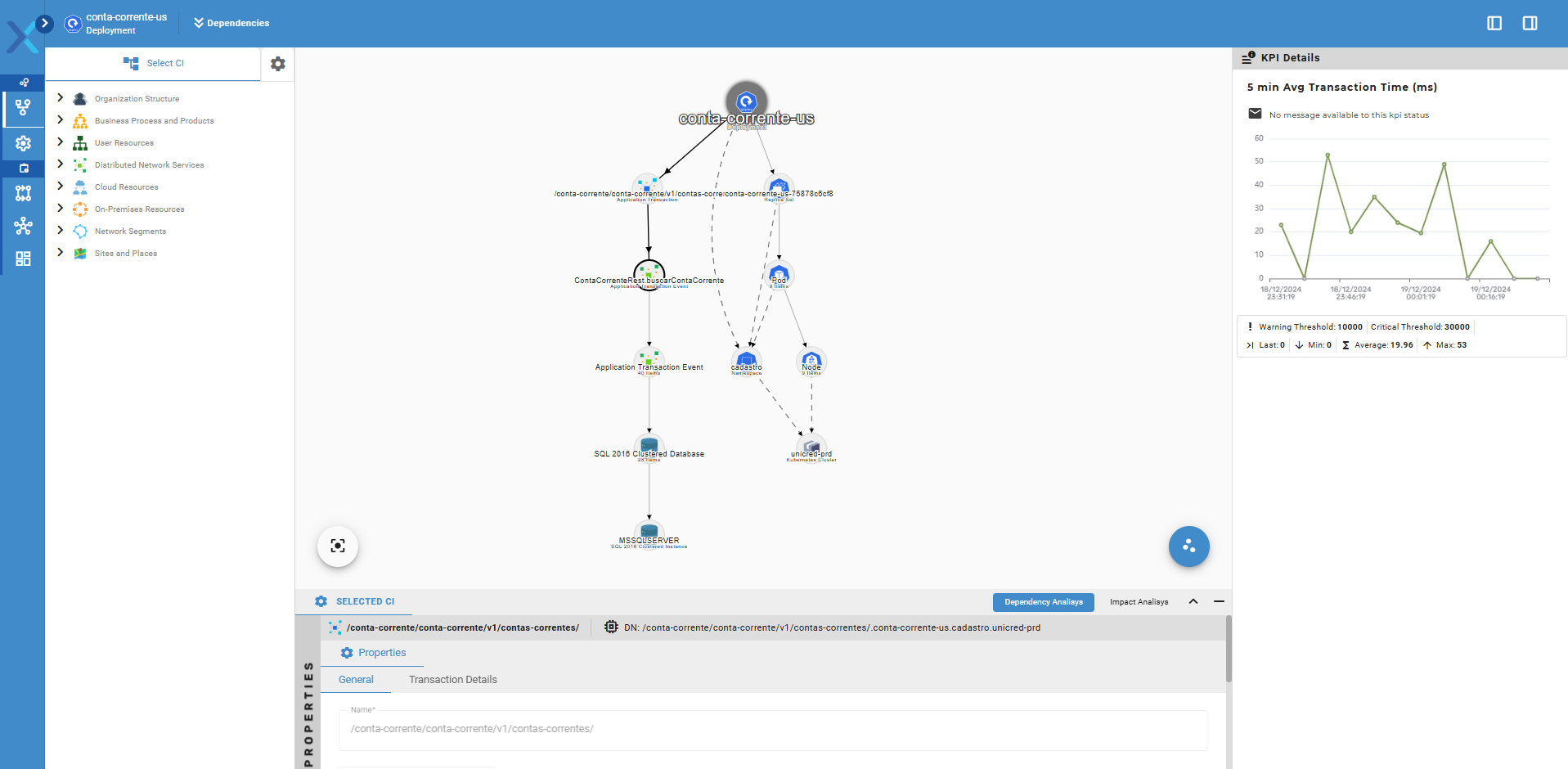
Nesta tela é exibido o mapa de dependências do Serviço. Podemos visualizar tanto os componentes internos das aplicações, representados por transações quanto os componentes da infraestrutura que suportam essas transações, como bases de dados e a estrutura do Kubernetes. Ao selecionar uma Transação, são exibidas à direita os gráficos de Time Series dos indicadores e métricas que são gerados ao longo do tempo como a média de tempo de execução, taxa de erros e taxa de transferência de dados e abaixo as execuções da transação ao longo do tempo (cada vez que a transação é executada dentro da aplicação).
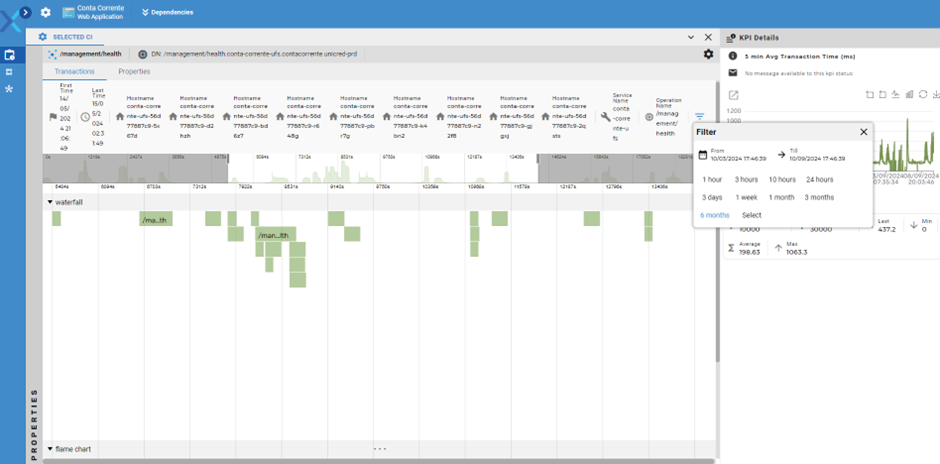
Como se pode ver na tela acima, podemos personalizar a janela de tempo que será exibida. Podemos também dar zoom-in e zoom-out ao longo do tempo para poder ter mais detalhes das execuções da transação. As barras que representam cada execução fornecem informações importantes sobre o tempo que levou cada execução. Barras mais longas foram as execuções que mais demoraram, e o tempo de execução pode ser visto passando o mouse em cima de cada execução, o que nos fornece outras informações como ID da Span e do Trace.
Ao clicar em uma das execuções podemos explorar todo o Trace da qual a execução da Transação faz parte e assim podemos compreender exatamente como transcorreu aquela execução, como foi chamada, por qual transação e o que ocorreu com aquela chamada de sistema como um todo.
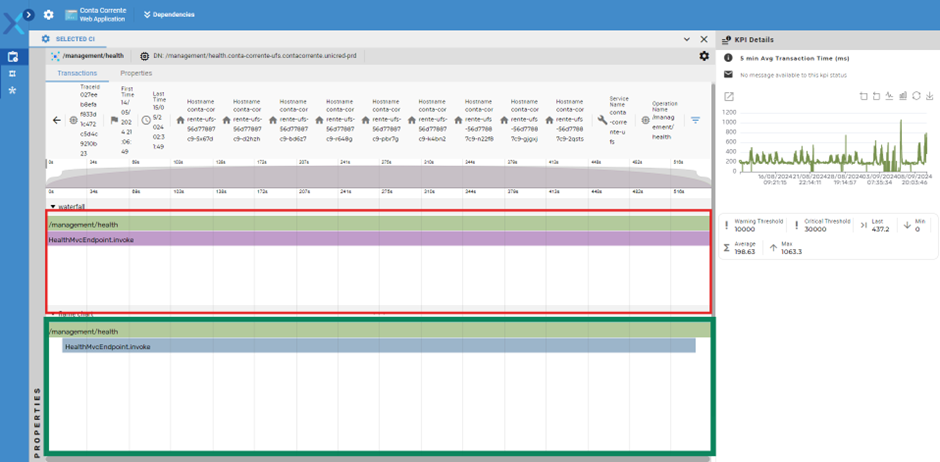
O gráfico de Destacado em vermelho, acima, mostra a linha de tempo e a relação pai-filho entre as spans (execuções da transação) e o gráfico em verde, mostra como o tempo foi percentualmente distribuído entre as spans pai e filho de cada trace.
Clicando em cada span em qualquer um dos gráficos, é possível ver os detalhes de cada execução, incluindo logs e parâmetros de execução.
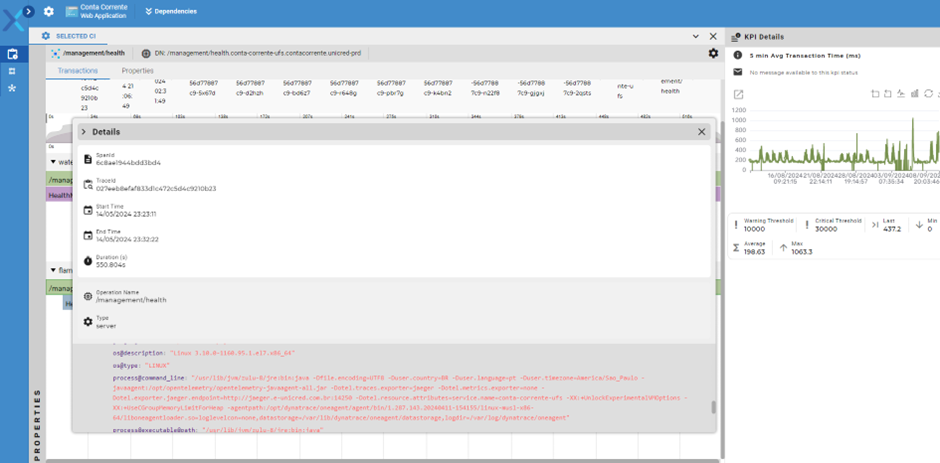
As métricas para cada transação tal como: tempo médio Latency (ou Avg Transaction Time), Número de execuções por período (Calls), taxa de erros por período (Error Tax), são exibidas no painel da direita, além de diversos dashboards com será demonstrado nesse documento.
Dentre as diversas tipos de transações que o Priax consegue detectar e analisar, exibir estatísticas, gráfcos e realizar drill down , além de produzir eventos e alertas estão:
- Transações de Servidor HTTP, gRPC, RPC,
- Transações internas (trechos de código que são executados internamente na aplicação, sem interação externa)
- Chamadas de Web Services para outros sistemas, estejam eles instrumentados ou não;
- Consultas à bancos de dados relacionais e não relacionais;
- Produção e consumo em sistemas de mensagens e filas como Kafka e RabbitMQ;
- Dados produzidos pelo navegador, coletado diretamente o comportamento do usuário.
Todas as métricas armazenadas pelo Priax (as citadas acima, mas também todas as métricas de qualquer Item de Configuração) podem ser mantidas por tempo configurável e ao selecionar, e se pode dar drill-down na métrica armazenada para análise retroativa selecionado o botão em destaque em vermelho abaixo.

Ao clicar nesse Botão você pode explorar os dados do Indicador ao longo do tempo. Indicadores
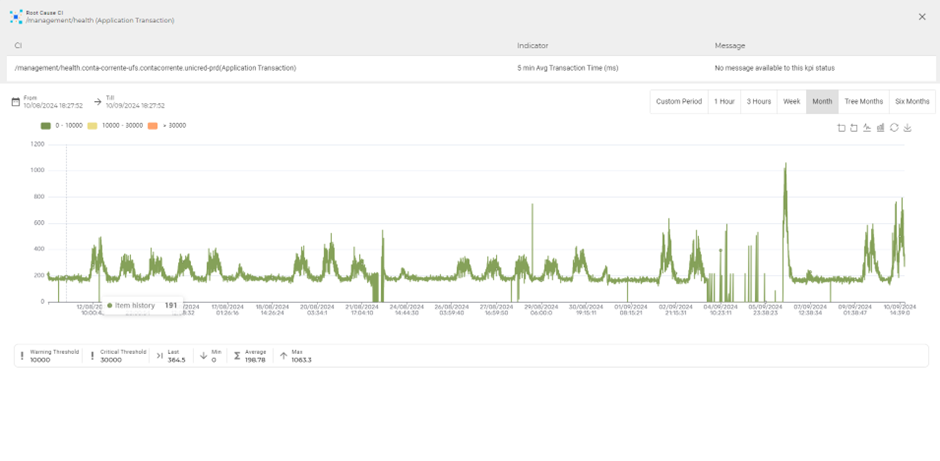
Nesta tela se pode tanto visualizar o dado de forma mais profunda (por exemplo por uma hora):
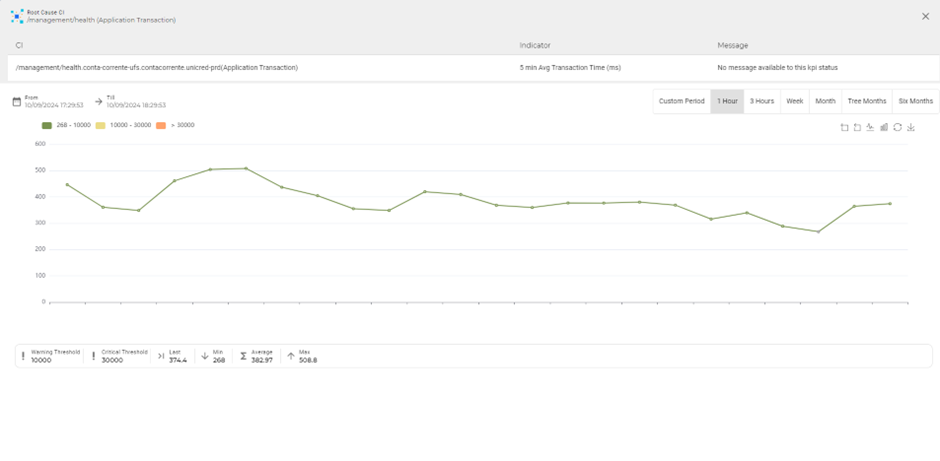
Tradicionalmente coletados para cada Transação são:
- Média de Tempo de Execução ao longo do tempo para 5, 10 e 15 minutos.
- Média de Taxa de erros de execução ao longo do tempo para 5, 10 e 15 minutos.
- Média de taxa de transferência de dados para 5, 10 e 15 minutos.
No entanto as métricas podem ser customizadas para cada caso.
Detectando problemas em Transações
Ao detectar um problema, que pode ser pela detecção de limites auto-calculados o Priax realiza, com a utilização de técnicas de análise de dados e machine learning, uma análise profunda de causa raiz, diferenciando os indicadores que representam um sintoma dos indicadores que de fato estão causando o problema, e unificando isso em um único Evento.
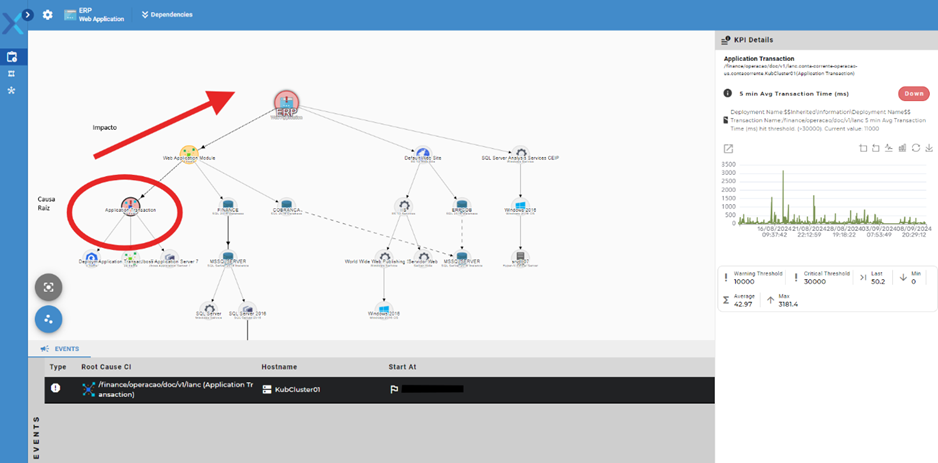
A partir do momento que um novo evento é detectado e sua causa raiz isolada, ele pode ser direcionado para a equipe e indivíduo correto, podendo ele realizar análise das correlações dos indicadores e itens de configuração envolvidos no Evento.
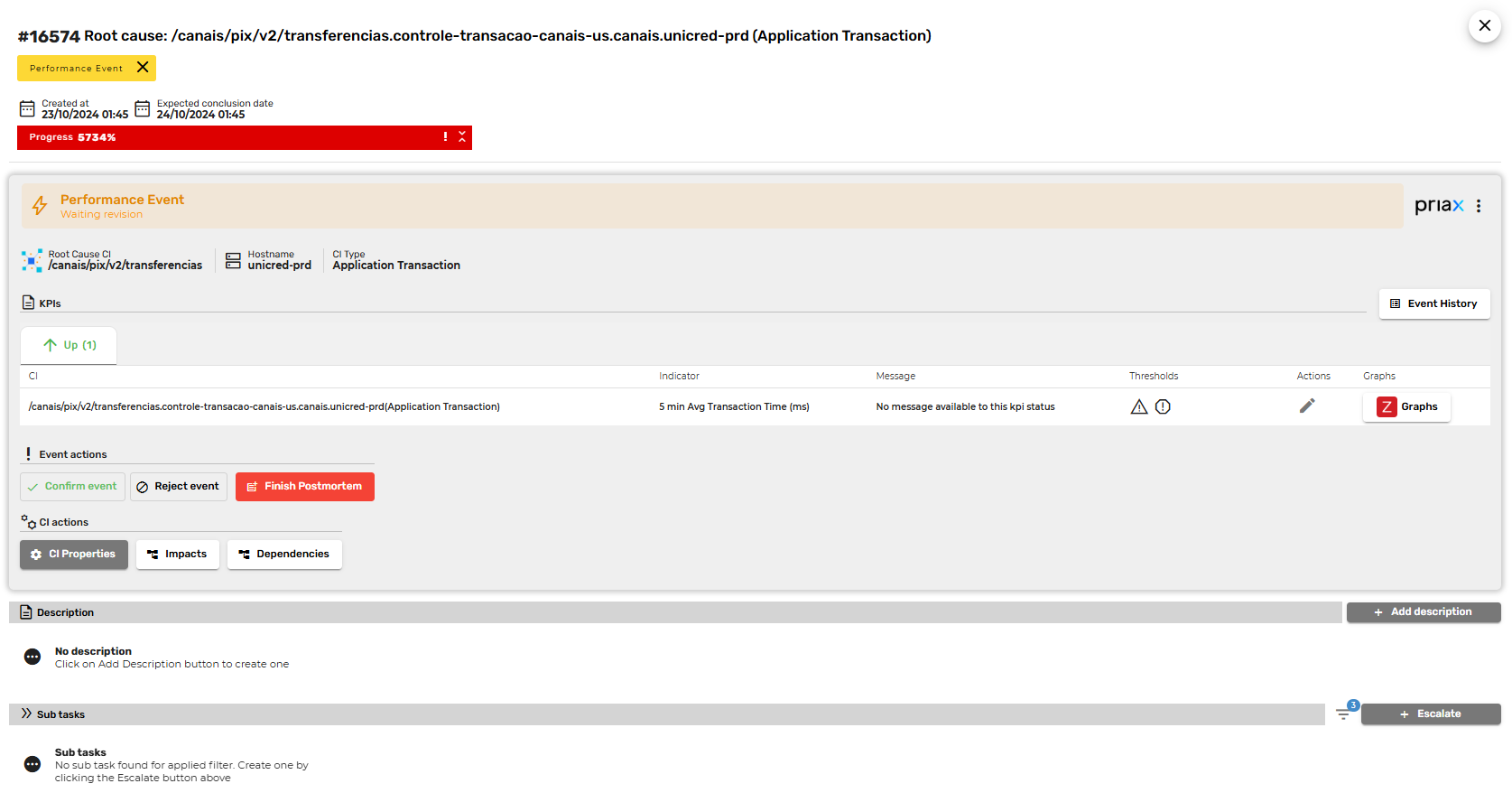
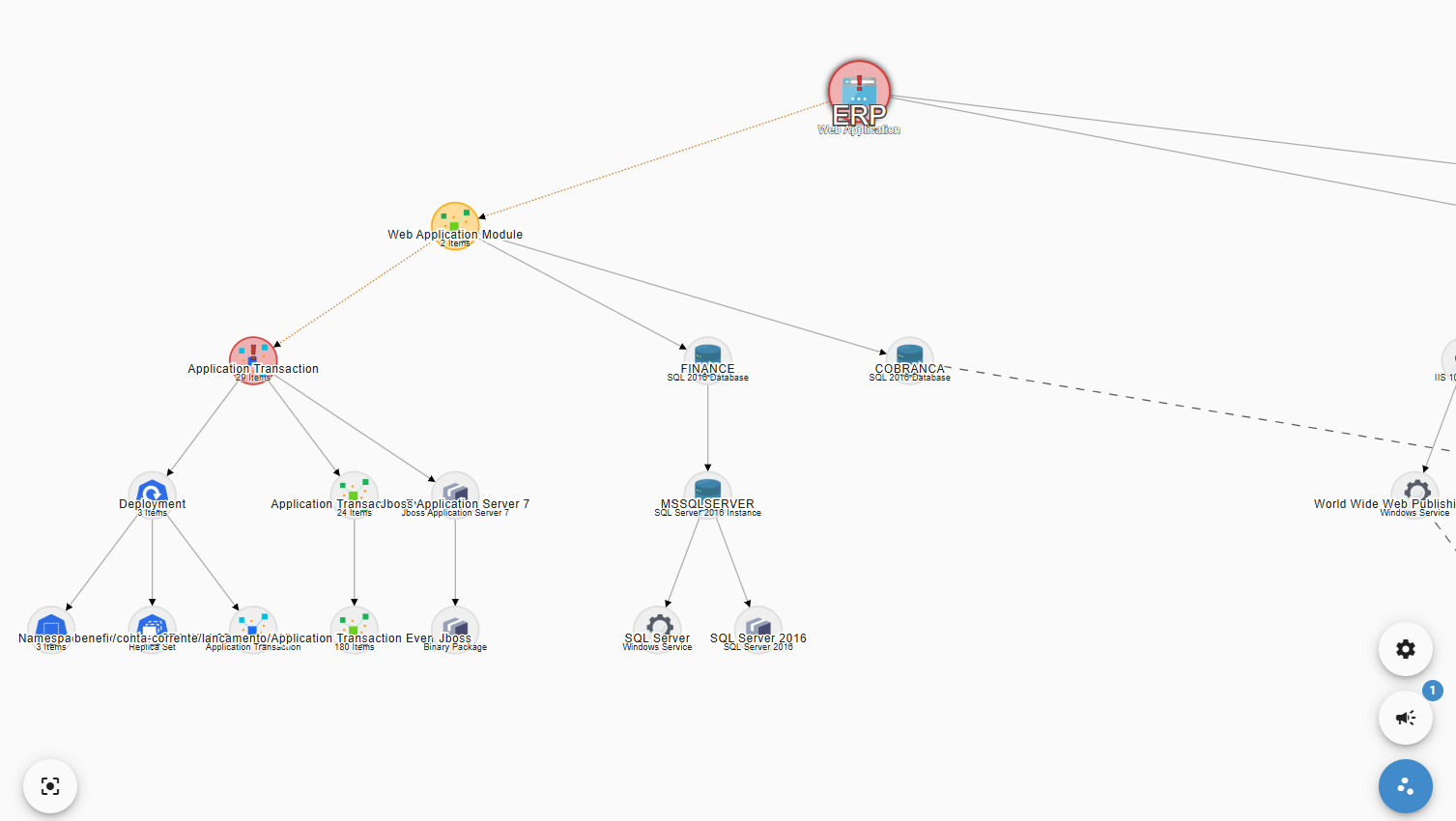
Ao receber um evento, você pode realizar a análise de impactos e de dependências da Transação causa-raiz do evento, o que nos permite entender quais outras Transações, Serviços e Aplicações estão sendo afetadas pelo problema. Ao analisar as dependências, também podemos detectar indicadores de infraestrutura que podem estar causando indiretamente o Evento.
Para saber mais sobre o Gerenciamento de Eventos, consulte o capítulo específico sobre Gerenciamento de Operações e Eventos neste manual.